溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
隊列用來有序地鎖定關系與非關系型的Oracle結構。關系型結構可能是Oracle的數據字典表或應用程序表。例如,當Oracle更新sys.col$表或一個應用程序更新它的employee表,隊列將會被調用。如果一個服務器進程被鎖定的表所阻止,不僅僅會post一個enqueue wait等待事件,還會在v$lock,dba_lock,v$enqueue_statistics與其它視圖中顯示鎖信息。非關系型結構被鎖定是為了阻止不合適的更改比如library cache cursor。
顧名思義,隊列是非常有序的,并確保以非常確定的方式更改結構。進程的入隊列請求會被推送到適當的隊列上,當它需要處理時,它的入隊列條目會從隊列中彈出(也叫作dequeue)。這里并沒有什么令人興奮的地方,但是排隊不是為了冒險,而是為了確保以一種非常有序的、類似會計的方式更改Oracle結構。
Oracle維護了數量驚人的隊列。在Oracle 10gr2中有208種隊列,在Oracle 11gr1中有247種隊列。但不必驚慌,因為你可能只會遇到幾個排隊的人。另外,如果您是一位經驗豐富的DBA,您已經處理過使用enqueue的行級和表級鎖。
診斷Enqueue等待
當解決隊列問題時,首先判斷隊列類型,然后確定所涉及的SQL,最后根據您對應用程序和相關Oracle內部的知識開發解決方案。在深入研究最常見的排隊等待(事務(TX)排隊)之前,務必了解如何確定正在等待哪個排隊和oracle 10g之前和之后版本中的相關會話。
在Oracle 10g之前,所有隊列的等待事件都是enqueue。這確實很不幸,因為這要從v$lock或v$session_wait中取樣來確定隊列名稱。下面的SQL語句用來從v$session_wait中來確實enqueue名。會話4388已經鎖表,沒有等待鎖,因此沒有顯示。隊列中的第一個會話是4387,緊接著是會話4393。判斷正在運行的SQL與所涉及的表最簡單的方式就是從v$session中查詢會話的sql_address或sql_hash_values。對于TM隊列,表可以通過p2列(ID 1列)來識別。它包含object_id,可以使用它來從dba_objects中進行查詢。這使得確定爭用對象非常簡單。
SQL> col sid format 9999 heading "Sid" SQL> col enq format a4 heading "Enq." SQL> col edes format a30 heading "Enqueue Name" SQL> col md format a10 heading "Lock Mode" trunc SQL> col p2 format 9999999 heading "ID 1" SQL> col p3 format 9999999 heading "ID 2" SQL> select sid, 2 chr(bitand(p1, -16777216) / 16777215) || 3 chr(bitand(p1, 16711680) / 65535) enq, 4 decode(chr(bitand(p1, -16777216) / 16777215) || 5 chr(bitand(p1, 16711680) / 65535), 6 'TX', 7 'Row related lock (row lock or ITL)', 8 'TM', 9 'Table related lock', 10 'TS', 11 'Tablespace and Temp Seg related lock', 12 'TT', 13 'Temporary Table', 14 'ST', 15 'Space Mgt (e.g., uet$, fet$)', 16 'UL', 17 'User Defined', 18 chr(bitand(p1, -16777216) / 16777215) || 19 chr(bitand(p1, 16711680) / 65535)) edes, 20 decode(bitand(p1, 65535), 21 1, 22 'Null', 23 2, 24 'Sub-Share', 25 3, 26 'Sub-Exlusive', 27 4, 28 'Share', 29 5, 30 'Share/Sub-Exclusive', 31 6, 32 'Exclusive', 33 'Other') md, 34 p2, 35 p3 36 from v$session_wait 37 where event = 'enqueue' 38 and state = 'WAITING' 39 / SQL> Sid Enq. Enqueue Name Lock Mode ID 1 ID 2 ----- ---- ------------------------------ ---------- -------- -------- 4387 TM Table related lock Exclusive 49911 0 4393 TM Table related lock Sub-Exlusi 49911 0 SQL> @swswp enq% Database: prod16 31-MAR-10 04:32pm Report: swswp.sql OSM by OraPub, Inc. Page 1 Session Wait Real Time w/Parameters Sess ID Wait Event P1 P2 P3 ----- ---------------------------- ------------ --------- ----- 4383 enq: TM – contention 1414332422 49911 0 4388 enq: TM – contention 1414332422 49911 0 2 rows selected. SQL> l 1 select sid, event, 2 p1, p2, p3 3 from v$session_wait 4 where event like '&input%' 5 and state = 'WAITING' 6* order by event,sid,p1,p2
與latch等待事件一樣,從Oracle 10g開始,每一種隊列都有它自己的等待事件。這節省了診斷步驟,因為我們可以通過一個簡單的查詢確定所涉及的會話和隊列類型。會話4393已經持有表鎖并且沒有等待所以沒有顯示,會話4383和4388正等待鎖表因此post一個TM隊列等待。通過使用P2列(49911)來與dba_objects視圖的object_id關聯進行查詢來獲得被調用的表。
TX Enqueue等待
TX隊列等待是最常見的隊列等待事件。這也是最迷人的。想深入研究這個等待事件,因為它將使您更深入地了解Oracle如何管理事務并發性,這與塊克隆、undo、讀取一致性和相關事務列表有關。
TX隊列也叫作行級鎖隊列,實際上出現TX隊列有三個原因,并且只有一個實際上是行級鎖。每一個Oracle數據塊可以被抽象為三個區域:
.行數據包含真實的Oracle行記錄并且是每個數據塊最重要的一個部分。
.可變數據包含事務元數據
.可用空間數量可以通過行數據增長與可變數據增長而減小
相關事務列表(ITLs)
內置在每個Oracle數據塊的可以數據區域的結構叫作相關事務列表(ITLs)。這些結構最主要是用來負責Oracle的行級鎖與讀一致性。從高度抽象的角度來看,可以認為ITLs就像檢查框,每個檢查框與一個特定的事務相關。如果想要更新行記錄,但被鎖定的行已經與其它事務的ITL關聯,你將會收到一個TX隊列等待,這確實是行級鎖。
每個Oracle數據塊都創建了特定數量的ITLs。ITLs的初始值是由表的initrans空間參數所控制的并且可以通過dba_tables視圖的ini_trans列來查看。從Oracle 9i開始,缺省的ini_trans值為1,然而通過簡單的塊dump可以清楚的看到創建了兩個ITL。使用兩個ITLs,單個數據塊可以同時并發地執行兩個事務。
假設第三個事務想要修改塊中沒有被鎖定的行而只在兩個ITL存在時,第三個事務的服務器進程將嘗試動態創建一個額外的ITL。然而服務器進程必須首先確保ITL的最大數(max_trans)不會被超過并且在數據塊中要有可用空間。如果服務器進程不能創建額外的ITL,它將發出一個TX隊列等待事件,并且這個進程將耐心等待。為了減小這種情況的出現,單個塊的ITLs的缺省值與最大值都可以設置為255。當不超過這個值時可以執行alter table命令來修改。
一旦在數據塊中創建了一個ITL后,唯一能獲得空間的方式是重新創建整個表。修改空間參數將不會影響已經創建的ITL。這就是為什么缺省的ITLs為1(實際上創建了兩個ITL)并且最大值設置為255的原因。如果數據塊的并發請求更多的ITLs,Oracle寧愿消耗空間也不愿意發出TX隊列等待事件而讓事務等待。
初看,ITL的最大數是255可能看上去非常有限,但請考慮這種情況:想想在最高并發應用程序中,在最高并發的數據庫中的最高并發表。也許有一個表可能有250個并發進程正在更新,刪除與插入記錄。現在真正有多少進程將會并發更新,刪除或插入記錄到一個數據塊中,而不是整個表或區,是單個塊。即使使用最高并發性的應用程序,在一個塊中激活超過255個并發事務也是極不可能的。所以ITL的最大數255并沒有太大的限制。然而如果確實出現了問題,可以通過增加表的pct_free參數來減小數據塊的并發性或者為了減少存儲在塊中的行記錄可以增加固定長度的列。
Unod段的事務表
每個undo段在它的頭塊中包含一個結構叫事務表。Oracle開發人員將事務表中的行稱作slots(插槽)。每一個已經占用的slot都與正在或已經在undo段中存儲undo信息的事務相關。如果一個事務已經提交或者回滾,它確實是一個非活動事務,否則它就是一個活動事務。除了包含slot號與事務狀態,每個slot也包含一個序列號。為了區分不同的事務使用相同的slot并能讓slot重用,序列號可以增長。UBA是undo塊地址,提供到事務的undo的直接鏈接。SCN是當相關事務開始時事務的系統改變號。
事務表與性能分析人員相關因為它們提供了事務號。每個事務有一個相關的事務號,并且事務號是基于事務的事務表條目生成的。事務號由三組數字組成。第一部分是事務表號,第二部分是slot號,最后是相關序列號。例如,一個事務號為00100.000.00007。ITLs與事務表之間的聯系是每個ITL條目關聯到一個特定的事務并且在ITL條目中包含事務號,比如00100.000.00007。
深入了解相關事務列表(ITL)
已經了解了ITL與undo段事務表,現在是將它們作為單個工作單元組合在一起的時候了,并展示在事務活動期間ITLs是如何變化的。深入了解相關事務列表可以讓你深入理解Oracle如何管理事務并發性,如何創建讀一致性塊以及為什么要小心“snapshot too old”錯誤。
下面通過執行命令alter system dump datafile 1 block 75847來dump數據塊。在執行塊dump時,這個塊(1,75847)包含了許多行記錄并且有三個活動事務更新四行不同的記錄。第一個與第三個事務顯示正在更新一行記錄,第二個事務正在更新二行記錄。
$ cat prod5_ora_21741.trc ... Block header dump: 0x00412847 Object id on Block? Y seg/obj: 0xff6b csc: 0x00.50fcb6 itc: 3 flg: O typ: 1 - DATA fsl: 0 fnx: 0x412848 ver: 0x01 Itl Xid Uba Flag Lck Scn/Fsc 0x01 0x0003.00d.00000318 0x00c3e3d0.0593.0c ---- 1 fsc 0x0000.00000000 0x02 0x0008.01b.00000340 0x00c41bce.0481.24 ---- 2 fsc 0x0000.00000000 0x03 0x0001.000.00000320 0x00c45fa0.0599.0b ---- 1 fsc 0x0000.00000000 ...
ITL條目包含以下內容:
itl:這是事務的ITL號
xid:這是事務ID,它由事務表ID(0003),事務表slot號(00d)與序列號(00000318)組成。事務ID是很重要的,因為它用于確保看起來相關的undo信息是真正相關的。
uba:這是undo塊地址。這直接指向事務的最新更改undo,對于回滾事務和讀取一致性(克隆緩沖區構造)都是必要的。
flag:事務的狀態它可以有許多值,以下是常見值
----- 意味著事務是活動的,DML在執行事務沒有提交或回滾
--U-- 意味著事務已經提交,因此任何行數據都可以引用在活動事務中沒有被使用的ITL并且它們沒有被鎖定。事務的行數據可能沒有被合并。例如,如果一個列被更新,在更改之前與之前的值可能保留在行數據中。
--C-- 意味著事務已經提交,行數據已經合并,并且行數據中的ITL條目已經被刪除。任何塊touch可能觸發對這個flag的改變,包括select語句。我知道這很難相信。這種看似延遲的更改通常稱為延遲塊清除,或者簡單地稱為塊清除。
Lck:這是事務在某個時刻鎖定在這個塊中的行數。大于0的值不能夠說時行被鎖定。如果這個值為2,就像第二個事務一樣,這個事務關聯兩行記錄。鎖會保持到flag改變為C----為止。這意味著在一個事務提交后且不再被認為是活動(--U--)狀態時,Lck值可能大于0
Scn/Fsc:SCN是系統改變號并用來判斷事務是何時結束的(提交或回滾)。上面的例子中SCN沒有被指泒,但在事務提交后,SCN被設置了如下所示。當創建一個buffer的讀一致性版本判斷是否需要檢索undo時SCN是很重要的。FSC引用可用空間信用。它用于未提交的事務當一個更新或刪除操作造成行記錄長度收縮使用。Oracle將保護這個空閑空間,以防事務回滾和需要重新填充空間。如果空閑空間用于其他用途,然后事務回滾,則可能需要遷移行!。在下面的dump結果中,前兩個事務(ITLs x01與x02)已經提交標記它們的事務為非活動狀態。第三個事務,ITL x03,還沒有提交。在前兩個事務提交后,相同的塊dump命令,alter system dump datafile 1 block 75847。注意flag已經改變了,一個SCN已經指泒給事務了。
$ cat prod5_ora_21741.trc ... Block header dump: 0x00412847 Object id on Block? Y seg/obj: 0xff6b csc: 0x00.50fcb6 itc: 3 flg: O typ: 1 - DATA fsl: 0 fnx: 0x412848 ver: 0x01 Itl Xid Uba Flag Lck Scn/Fsc 0x01 0x0003.00d.00000318 0x00c3e3d0.0593.0c --U- 1 fsc 0x0000.0050fd6f 0x02 0x0008.01b.00000340 0x00c41bce.0481.24 --U- 2 fsc 0x0000.0050fd6b 0x03 0x0001.000.00000320 0x00c45fa0.0599.0b ---- 1 fsc 0x0000.00000000
兩個flags ----與--U-是必需的,因為活動事或者過去的活動事務中涉及的行可以在其行數據中具有有效的ITL條目。因為簡單引用行數據與查看ITL條目不能說明行當前被活動事務調用與鎖定。為了檢查行是否被鎖定,一個服務器進程必須從行數據中得到ITL引用然后檢查數據塊的可變ITL區域中的flag。如果flag為 ----,那么服務器進程知道行確實被一個活動事務所調用且被鎖定。然而如果falg為--U,服務器進程知道行沒有被鎖定。
塊清除進程的部分工作將刪除非活動事務行數據ITL條目,將它們各自的ITL條目在數據塊的可變部分的flag的狀態修改為C---,并合并行數據。
這是一種聰明的策略,因為Oracle可以快速使用最小的改變來記錄數據塊中的改變,但仍然在行級別維護并發控制。最終需要對塊進行最后的更改,但這可能發生在工作負載較低的時期,比如基準測試完成之后。
執行查詢語句來touch塊1,75847后,再執行dump命令的結果如下,數據塊(1,75847)在執行查詢語句touch數據塊后事務flags從--U-變為了C---,指示塊清除已經發生了。
$ cat prod5_ora_21741.trc ... Block header dump: 0x00412847 Object id on Block? Y seg/obj: 0xff6b csc: 0x00.510047 itc: 3 flg: O typ: 1 - DATA fsl: 0 fnx: 0x412848 ver: 0x01 Itl Xid Uba Flag Lck Scn/Fsc 0x01 0x0003.00d.00000318 0x00c3e3d0.0593.0c C--- 0 scn 0x0000.0050fd6f 0x02 0x0008.01b.00000340 0x00c41bce.0481.24 C--- 0 scn 0x0000.0050fd6b 0x03 0x0001.000.00000320 0x00c45fa0.0599.0b ---- 1 fsc 0x0000.00000000 ...
現在我意識到這很有趣,但是我也理解一些讀者可能認為這個block dump和ITL的東西并沒有那么強的關聯。但我不敢茍同。您不僅對TX排隊有了更全面的了解,而且還清楚地了解了如何排隊Oracle實現了它的專利行級鎖方案。
深入了解Buffer克隆
介紹塊克隆是因為它與CBC latch競爭。現在將深入學習Oracle如何使用ITLs,undo塊,SCNs與其它有趣的Oracle技術。當一個服務器進程要定位一個請求的buffer并且發現請求的行在查詢開始后發生改變了,它必須為buffer創建一個時光倒流的鏡像。這就叫作當前(CU)buffer的一致性讀(CR)buffer。一旦buffer被拷貝,合適的undo被應用后,使被拷貝的buffer回退直到CR buffer被成功克隆好為止。
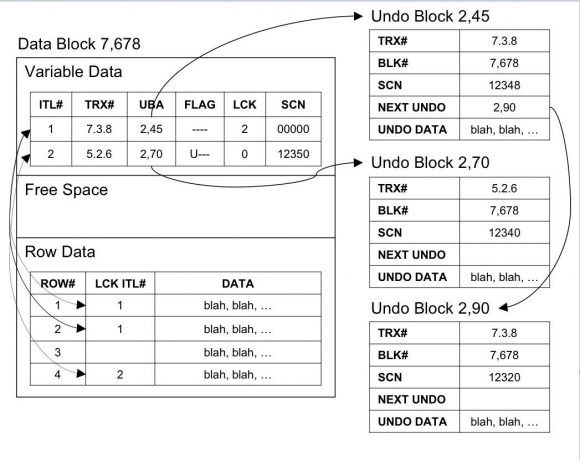
假設我們的查詢執行時間是SCN 12330,查詢最終得到要訪問的buffer 7,678。然而,我們注意到存在一些ITL活動事務 7.3.8當前是活動狀態并且buffer可能在我們查詢開始后發生了改變。事務5.2.6是非活動狀態(flag為C,并指派了SCN,并且Lck為0),但是改變的提交時間在我們查詢開始之后并且影響這個當前(CU)buffer。這些塊改變意味著在CU buffer在我們查詢在SCN 12330時間點開始后已經發生改變了并且不能用于我們的查詢。我們需要一個一致性讀副本,它可以時光倒流回到SCN 12330時間點。因此CU buffer 7,678必須被克隆并應用undo,來創建一個SCN12330時間點的CR buffer。
在執行buffer克隆之前,必須找到一個不被頻繁訪問的free buffer然后使用7,678的CU buffer來替換它。服務器進程將獲得LRU chain latch與相關的LRU chain,然后從LRU chain的LRU端開始掃描,查找不被頻繁訪問的free buffer。最終將找到一個不被頻繁訪問的free buffer并使用CU buffer 7,678的副本來替換它。當然CBC結構也將被更新來映射克隆buffer在buffer cache中的位置。
從與第一個ITL相關的活動事務7.3.8開始。服務器進程需要檢索在我們查詢開始時間scn 12330之后所有生成的undo記錄。事務7.3.8的最近生成的undo可以通過它的ITL的undo塊地址(UBA)所鏈接到的undo塊2,45中找到。服務器進程然后必須訪問undo塊2,45。這需要請求CBC活動并且也可能請求LRU活動來執行IO調用。一旦訪問到undo buffer 2,45,將會通過比較事務號來檢查確保我們使用正確的事務在工作。數據塊與undo塊事務號需要匹配(7.3.8),因為事務是活動的,所以undo信息應該沒有鋪覆蓋。
undo塊2,45的SCN是12348,這意味著undo塊代表的塊改變出現在我們查詢開始時間scn 12330之后,因此,我們需要對克隆的CR buffer應用undo數據,讓它回退到過去一點點。
undo塊2,45也鏈接到了另一個undo塊2,90。這是一種undo鏈并且可能持續一段時間,消耗大量的計算資源。服務器進程現在必須訪問undo塊2,90(請求CBC活動并且也可能請求LRU活動來執行IO調用)并且再次比較事務號來確保它們是否匹配。它們匹配,現在檢查SCN。undo塊2,90的SCN是12320,它在我們的查詢開始時間SCN 12330之前,因此我們不需要應用undo。如果不應用undo,我們的CR buffer將代表的是塊7,678在SCN 12320時間點的版本,這比我們要查詢的時間SCN 12330早了。
現在查看第二個ITL,它與事務5,2.6關聯。這個事務在SCN 12350時間點已經提交了,在我們的查詢開始時間之后,因此我們需要應用它的undo。從ITL條目來看,我們將得到ndo塊地址2,70并且訪問這個undo塊。現在比較事務號,因為事務已經提交,undo信息將不再受保護。增加undo保留期可以讓udno信息保留更長的境,但也不受保護。
假設另一個服務器進程覆蓋了undo塊2,70中的相關事務undo信息。如果出現這種情況,服務器進程的事務號將被記錄并且這里將記錄為5.2.6。通過事務號比較,我們注意到差異并且立即知道undo塊2,70中的undo不能應用于我們的CR buffer。在這時,服務器進程將會發出快照太舊的錯誤信息并停止我們的查詢。很明顯,undo塊快照太舊因為被其它進程覆蓋了。
幸運地是,事務號是匹配的。undo塊2,70中的undo是在SCN 12340時間點發生的改變,它在我們的查詢開始之后,因此我們應用這個undo到我們的CR buffer。下一個undo鏈接是空的,因此沒有其它undo需要應用了。
現在返回到ITL條目,這里沒有更多的ITL需要考慮,因此我們完成的數據塊的克隆。任何一個服務器進程現在都可以訪問CR buffer 7,678它包含了SCN 12330時間所代表的內容。
現在應該很清楚為什么ITLs如此重要了,而且Oracle的讀取一致性模型雖然非常強大、必要且高效,但仍然相對昂貴,因為它可能會消耗大量CPU和IO,從而減慢應用程序的響應時間。Oracle非常清楚這一點,并且從Oracle 10gr2開始使用內存優化結構來臨時存儲undo信息。這些對象不是段類型并且不受與段相關的CBC和LRU chain活動的影響。在內存中,undo被存儲在shared pool中。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





