溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“PostgreSQL掃描方法是什么”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“PostgreSQL掃描方法是什么”吧!
關系型數據庫都需要產生一個最佳的執行計劃從而在查詢時耗費的時間和資源最少。通常情況下,所有的數據庫都會產生一個以樹形式的執行計劃:計劃樹的葉子節點被稱為表掃描節點。查詢節點對應于從基表獲取數據。
例如,這一個查詢:SELECT *FROM TAB1,TAB2 where TAB2.ID>1000。假設計劃樹如下:
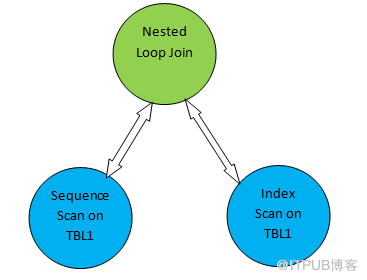
上面的計劃樹:“TBL1上的順序掃描”和“TBL2上的索引掃描”分別對應于表TBL1和TBL2上的表掃描方法。TBL1上的順序掃描:從對應頁中順序獲取數據;索引掃描:使用索引掃描訪問表2。選擇一個正確的掃描方法作為計劃的一部分對于查詢性能非常重要。
深入理解PG的掃描方法之前,先介紹幾個重要的概念。
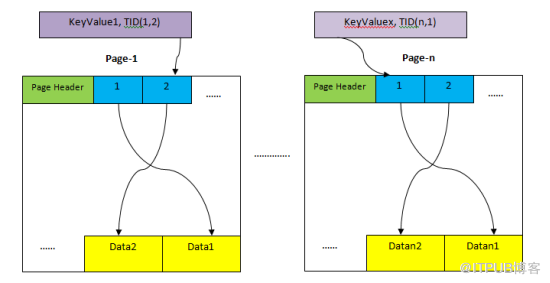
HEAP:存儲表整個行的存儲域。如上所示,整個域被分割為多個頁,每個頁大小默認是8K。每個頁中,item指針(例如上述頁中的1,2)指向頁內的數據。
Index Storage:只存儲KEY值,即索引中包含的列值。也是分割成多個頁,每個索引頁默認8K。
Tuple Identifier(TID):TID為6個字節,包含兩部分。前4個字節為頁號,后2個字節為頁內tuple索引。TID可以定位到特定記錄。
當前版本,PG支持以下掃描方法:順序掃描、索引掃描、索引覆蓋掃描、bitmap掃描、TID掃描。依賴于表基數、選擇的表、磁盤IO、隨機IO、順序IO等,每種掃描方法都非常有用。我們先創建一個表并預制數據,并解釋這些掃描方法。
postgres=# CREATE TABLE demotable (num numeric, id int); CREATE TABLE postgres=# CREATE INDEX demoidx ON demotable(num); CREATE INDEX postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 1000000); INSERT 0 1000000 postgres=# analyze; ANALYZE
這個例子中,預制1億條記錄并執行analyze更新統計信息。
順序掃描
顧名思義,表的順序掃描就是順序掃描對應表所有頁的item指針。如果一個表有100頁,每頁有1000條記錄,順序掃描就會獲取100*1000條記錄并檢查是否匹配隔離級別以及where條件。因此,即使只有1條記錄滿足條件,他也會掃描100K條記錄。針對上表的數據,下面的查詢會進行順序掃描,因為有大部分的數據需要被selected。
postgres=# explain SELECT * FROM demotable WHERE num < 21000; QUERY PLAN -------------------------------------------------------------------- Seq Scan on demotable (cost=0.00..17989.00 rows=1000000 width=15) Filter: (num < '21000'::numeric) (2 rows)
注意,不計算和比較計劃耗費,幾乎不可能直到選用哪個掃描方法。但是為了使用順序掃描,至少需要滿足以下關鍵點:謂詞部分沒有可用的索引鍵;或者SQL查詢獲取的行記錄占表的大部分。如果只有少數行數據被獲取,并且謂詞在一個或多個列上,那么久會嘗試使用或者不使用索引來評估性能。
索引掃描
和順序掃描不同,索引掃描不會順序獲取所有表記錄。相反,依賴于不同索引類型并和查詢中涉及的索引相對應使用不同的數據結構。然后索引掃描獲取的條目直接指向heap域中的數據,然后根據隔離級別判斷可見性。因此索引掃描分兩步:
從索引數據結構中獲取數據,返回heap中數據對應的TID;然后定位到對應的heap頁直接訪問數據。由于以下原因需要執行額外的步驟:查詢可能請求可用索引更多的列;索引數據中不維護可見信息,為了判斷可見性,需要訪問heap數據。
此時可能會迷惑,索引掃描如此高效,為什么有時不用呢?原因在于cost。這里的cost涉及IO的類型。索引掃描中,為了獲取heap中的對應數據,涉及隨機IO;而順序掃描涉及順序IO,只有隨機IO耗時的1/4。
因此只有當順序IO的代價大于隨機IO時,才會選擇索引掃描。
針對上表和數據,執行下面查詢時會使用索引掃描。隨機IO代價小,從而查詢標記快。
postgres=# explain SELECT * FROM demotable WHERE num = 21000; QUERY PLAN -------------------------------------------------------------------------- Index Scan using demoidx on demotable (cost=0.42..8.44 rows=1 width=15) Index Cond: (num = '21000'::numeric) (2 rows)
Index Only Scan
僅索引掃描和索引掃描類似,區別在于第二步,僅僅涉及到掃描索引數據。有兩個條件:查詢獲取的數據只有key列,且該列是索引的一部分;所有獲取的數據都是可見的。如下所示:
postgres=# explain SELECT num FROM demotable WHERE num = 21000; QUERY PLAN ----------------------------------------------------------------------------- Index Only Scan using demoidx on demotable (cost=0.42..8.44 rows=1 Width=11) Index Cond: (num = '21000'::numeric) (2 rows)
Bitmap Scan
是索引掃描和順序掃描的混合體。為了解決索引掃描的缺點并充分利用其優點。正如上面所說,對于索引數據結構中的數據,需要找到heap頁中對應的數據。因此需要獲取一次索引頁,然后獲取heap頁,從而造成大量隨機IO。Bitmap掃描方法平衡了不使用隨機IO的索引掃描優點。
Bitmap index scan:首先獲取索引數據并為所有TID創建bitmap。為了理解方法,可以認為bitmap包含所有頁的哈希(基于頁號),每個頁的entry包含頁內所有偏移的數組。
Bitmap heap scan:從頁的bitmap中讀取值,然后針對頁和偏移掃描數據。最后檢查可見性和條件并返回tuple。
下面查詢使用bitmap掃描,因為他選擇的記錄很多(比如too much for index scan)但不是大量(too little for sequential scan)。
postgres=# explain SELECT * FROM demotable WHERE num < 210; QUERY PLAN -------------------------------------------------------------------------- Bitmap Heap Scan on demotable (cost=5883.50..14035.53 rows=213042 width=15) Recheck Cond: (num < '210'::numeric) -> Bitmap Index Scan on demoidx (cost=0.00..5830.24 rows=213042 width=0) Index Cond: (num < '210'::numeric) (4 rows)
再看另一個查詢,選擇同樣多的記錄但是僅僅索引列。不需要heap頁因次沒有隨機IO,因此這個查詢選擇index only scan而不是bitmap scan。
postgres=# explain SELECT num FROM demotable WHERE num < 210; QUERY PLAN --------------------------------------------------------------------------- Index Only Scan using demoidx on demotable (cost=0.42..7784.87 rows=208254 width=11) Index Cond: (num < '210'::numeric) (2 rows)
TID Scan
TID掃描是PG中非常特殊的一種方式,和Oracle中的基于ROWID查詢類似:
postgres=# select ctid from demotable where id=21000; ctid ---------- (115,42) (1 row) postgres=# explain select * from demotable where ctid='(115,42)'; QUERY PLAN ---------------------------------------------------------- Tid Scan on demotable (cost=0.00..4.01 rows=1 width=15) TID Cond: (ctid = '(115,42)'::tid) (2 rows)
此外,PG社區還在討論其他的掃描方法:MySQL中的“Loose Index Scan”、Oracle中的“index skip scan”、DB2中的“jump scan”。這個掃描方法用在指定場景:選擇的B-tree索引的key列值都不同。避免遍歷所有相等的key值,而只遍歷第一個唯一值然后跳到下一個大值。這項工作PG正在開發,同樣被叫做“Index skip scan”,未來可以在release中看到這個特性。
感謝各位的閱讀,以上就是“PostgreSQL掃描方法是什么”的內容了,經過本文的學習后,相信大家對PostgreSQL掃描方法是什么這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





