溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹如何理解vxlan在openstack中的使用場景,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
介紹前,首先講一下網絡中underlay和overlay的概念。underlay指的是物理網絡層,overlay是指在物理網絡層之上的邏輯網絡或者又稱為虛擬網絡。overlay是建立在underlay的基礎上,需要物理網絡中的設備兩兩互聯,overlay的出現突破了underlay的物理局限性,使得網絡的架構更為靈活。以vlan為例,在underlay環境下不同網絡的設備需要連接至不同的交換機下,如果要改變設備所屬的網絡,則要調整設備的連線。引入vlan后,調整設備所屬網絡只需要將設備加入目標vlan下,避免了設備的連線調整。
vlan id數量不足
vlan header由12bit組成,理論上限為4096個,可用vlan數量為1~4094個,無法滿足云環境下的需求。
vm熱遷移
云計算場景下,傳統服務器變成一個個運行在宿主機上的vm。vm是運行在宿主機的內存中,所以可以在不中斷的情況下從宿主機A遷移到宿主機B,前提是遷移前后vm的ip和mac地址不能發生變化,這就要求vm處在一個二層網絡。畢竟在三層環境下,不同vlan使用不同的ip段,否則路由器就犯難了。
mac表項有限
普通的交換機mac表項有4k或8k等,在小規模場景下不會成為瓶頸,云計算環境下每臺物理服務器上運行多臺vm,每個vm有可能有多張vnic,mac地址會成倍增長,交換機的表項限制則成為必須面對的問題。
以多取勝
vxlan header由24bit組成,所以理論上VNI的數量為16777216個,解決了vid數量不足的問題。
此處需要說明的是:在openstack中,盡管br-tun上的vni數量增多,但br-int上的網絡類型只能是vlan,所有vm都有一個內外vid(vni)轉換的過程,將用戶層的vni轉換為本地層的vid。
細心的你可能會有這樣的疑問:盡管br-tun上vni的數量為16777216個,但br-int上vid只有4096個,那引入vxlan是否有意義?答案是肯定的,以目前的物理機計算能力來說,假設每個vm屬于不同的tenant,1臺物理機上也不可能運行4094個vm,所以這么映射是有意義的。 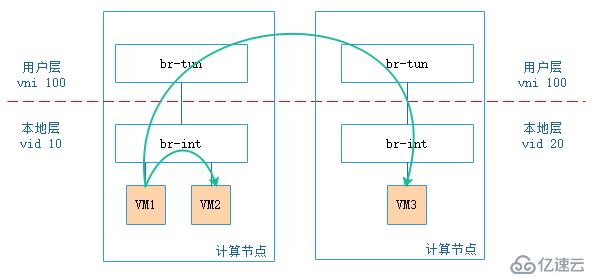
上圖是2計算節點間vm通信的示意圖,圖中所有的vm屬于同一個tenant,盡管在用戶層同一tenant的vni一致,但在本地層,同一tenant由nova-compute分配的vid可以不一致,同一宿主機上同一tenant的相同subnet之間的vm相互訪問不需要經過內外vid(vni)轉換,不同宿主機上相同tenant的vm之間相互訪問則需要經過vid(vni)轉換。如果所有宿主機上vid和vni對應關系一致,整個云環境最多只能有4094個tenant,引入vxlan才真的沒有意義。
暗渡陳倉
前面說過,vm的熱遷移需要遷移前后ip和mac地址不能發生管改變,所以需要vm處于一個二層網絡中。vxlan是一種overlay的技術,將原有的報文進行再次封裝,利用udp進行傳輸,所以也稱為mac in udp,表面上傳輸的是封裝后的ip和mac,實際傳播的是封裝前的ip和mac。 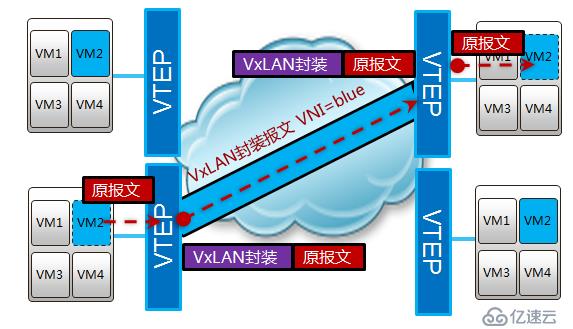
銷聲匿跡
在云環境下,接入交換機的表項大小會成為瓶頸,解決這個問題的方法無外乎兩種:
1.擴大表項 : 更高級的交換機有著更大的表項,使用高級交換機取代原有接入交換機,此舉會增加成本。
2.隱藏mac地址: 在不增加成本的前提下,使用vxlan也能達到同樣的效果。前文得知,vxlan是對原有的報文再次封裝,實現vxlan功能的vetp角色可以位于交換機或者vm所在的宿主機,如果vtep角色位于宿主機上,接入交換機只會學習經過再次封裝后vtep的mac地址,不會學習其上vm的mac地址。 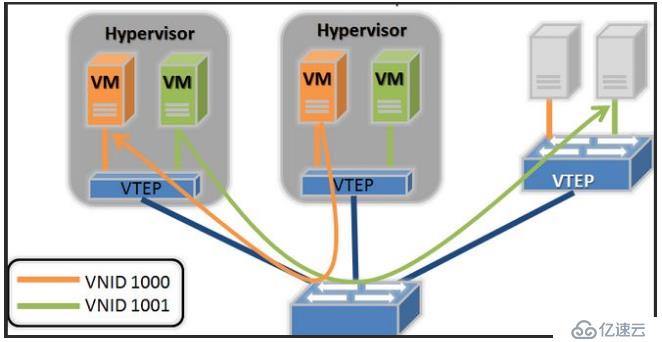
如果vtep角色位于接入交換機上,處理報文的效率更高,但是接入交換機會學習到vm的mac地址,表項的限制依然沒有得到解決,后續對這兩種情況會做詳細說明。
以上就是openstack場景中使用vxlan的原因,下面將會對vxlan的實現原理進行詳細說明。
vxlan報文長什么樣
vxlan報文是在原有報文的基礎上再次進行封裝,已實現三層傳輸二層的目的。 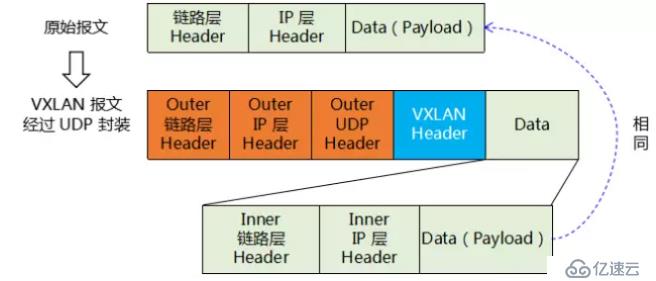
如上圖所示,原有封裝后的報文成為vxlan的data部分,vxlan header為vni,ip層header為源和目的vtep地址,鏈路層header為源vtep的mac地址和到目的vtep的下一個設備mac地址。
在筆者所從事的公有云架構中,vtep角色通過宿主機上的ovs實現,宿主機上聯至接入交換機的接口類型為trunk,在物理網絡中為vtep專門規劃出一個網絡平面 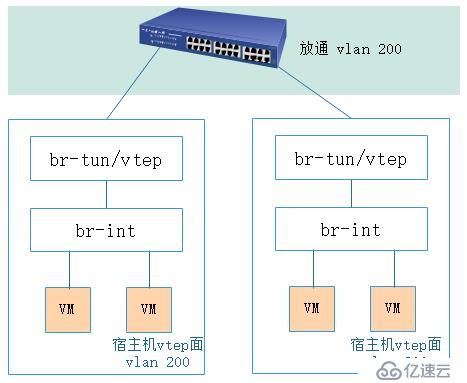
vm在經過vtep時,通過流表規則,去除vid,添加上vni 
vtep平面規劃的vid在vxlan的封裝過程中被打上,原因如下圖所示,vxlan的mac header中可以設置vlan tag 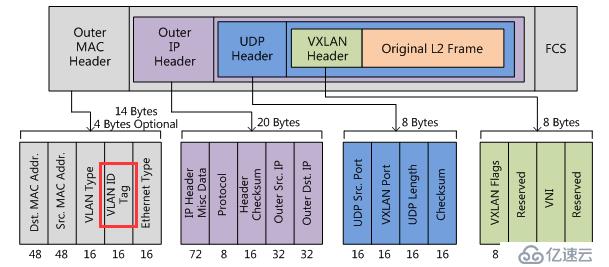
vtep是什么
vtep全稱vxlan tunnel endpoint,vxlan可以抽象的理解為在三層網絡中打通了一條條隧道,起點和終點的兩端就是vetp。vtep是實現vxlan功能的重要模型,可以部署在接入交換機或者服務器上,部署在不同的位置除了前文中提到是否學習vm的mac地址外,實現的機制也所有不同,以下內容如無特別說明,默認vtep部署在接入交換機上,vtep部署在服務器上后面會單獨說明。
vxlan隧道的建立
對于物理交換機而言,vtep是物理交換機上的一個角色,換句話說,vtep只是交換機上的一部分功能,并非所有的報文都需要走vxlan隧道,報文也可能走普通的二三層轉發。那么哪些報文需要走vxlan隧道? 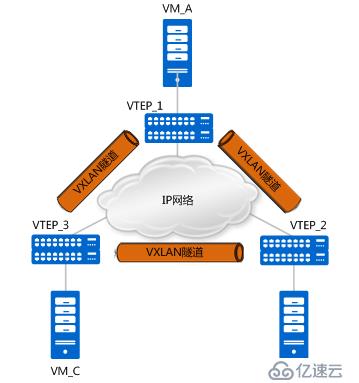
如上圖所示,vxlan打造了一個大二層的概念,當連接兩個不同vtep的vm需要進行通信時,就需要建立vxlan隧道。每一個大二層域稱為一個bridge-domain,簡稱bd,類似于vlan的vid,不同的bd用vni表示,bd與vni是1:1的關系。
創建bd和設置bd與vni對應關系的配置如下:
# bridge-domain 10 //創建一個編號為10的bd vxlan vni 5000 //設置bd10對應的vni為5000 #
vtep會根據以上配置生成bd與vni的映射關系表,該映射表可以通過命令行查看,如下所示: 
有了映射表后,進入vtep的報文就可以根據自己所屬的bd來確定報文封裝時該添加哪個vni。問題就剩下報文根據什么來確定自己屬于哪個bd。
它可以通過二層子接口接入vxlan隧道和vlan接入vxlan隧道來實現。二層子接口主要做兩件事:一是根據配置來檢查哪些報文需要進入vxlan隧道;二是判斷對檢查通過的報文做怎樣的處理。 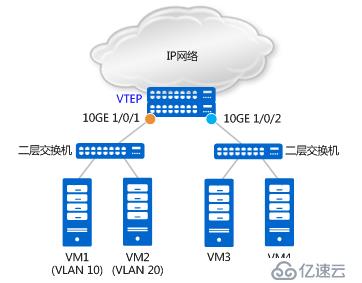
如上圖所示,基于二層物理接口10GE 1/0/1,分別創建二層子接口10GE 1/0/1.1和10GE 1/0/1.2,且分別配置其流封裝類型為dot1q和untag。配置如下:
# interface 10GE1/0/1.1 mode l2 //創建二層子接口10GE1/0/1.1 encapsulation dot1q vid 10 //只允許攜帶VLAN Tag 10的報文進入VXLAN隧道 bridge-domain 10 //報文進入的是BD 10 # interface 10GE1/0/1.2 mode l2 //創建二層子接口10GE1/0/1.2 encapsulation untag //只允許不攜帶VLAN Tag的報文進入VXLAN隧道 bridge-domain 20 //報文進入的是BD 20 #
基于二層物理接口10GE 1/0/2,創建二層子接口10GE 1/0/2.1,且流封裝類型為default。配置如下:
# interface 10GE1/0/2.1 mode l2 //創建二層子接口 10GE1/0/2.1 encapsulation default //允許所有報文進入VXLAN隧道 bridge-domain 30 //報文進入的是BD 30 #
至此,所有條件都已具備,就可以通過協議自動建立vxlan隧道隧道,或者手動指定vxlan隧道的源和目的ip地址在本端vtep和對端vtep之間建立靜態vxlan隧道。對于華為CE系列交換機,以上配置是在nve(network virtualization Edge)接口下完成的。配置過程如下:
# interface Nve1 //創建邏輯接口 NVE 1 source 1.1.1.1 //配置源VTEP的IP地址(推薦使用Loopback接口的IP地址) vni 5000 head-end peer-list 2.2.2.2 vni 5000 head-end peer-list 2.2.2.3 #
其中,vni 5000的對端vtep有兩個,ip地址分別為2.2.2.2和2.2.2.3,至此,vxlan隧道建立完成。
VXLAN隧道兩端二層子接口的配置并不一定是完全對等的。正因為這樣,才可能實現屬于同一網段但是不同VLAN的兩個VM通過VXLAN隧道進行通信。
總結一下,vxlan目前支持三種封裝類型,如下表所示: 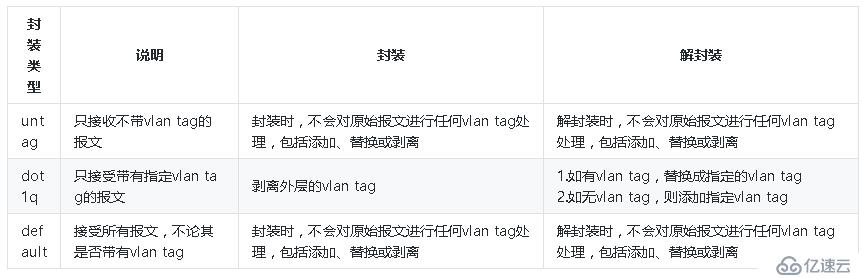
這種方法當有眾多個vni的時候,需要為每一個vni創建一個子接口,會變得非常麻煩。 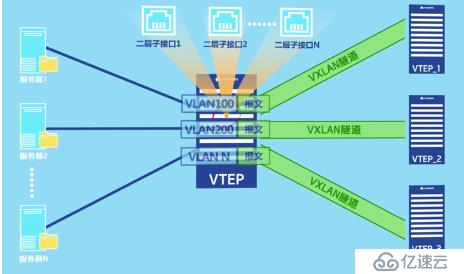
此時就應該采用vlan接入vxlan隧道的方法。vlan接入vxlan隧道只需要在物理接口下允許攜帶這些vlan的報文通過,然后再將vlan與bd綁定,建立bd與vni對應的bd信息,最后創建vxlan隧道即可。 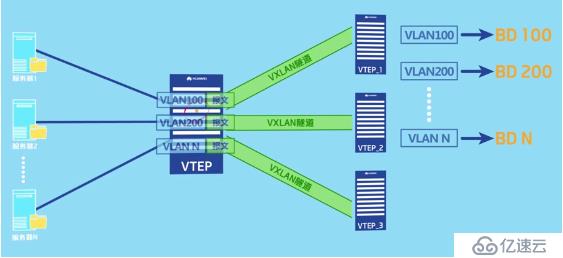
vlan與bd綁定的配置如下:
# bridge-domain 10 //創建一個編號為10的bd l2 binding vlan 10 //將bd10與vlan10綁定 vxlan vni 5000 //設置bd10對應的vni為5000 #
同子網vxlan通信流程 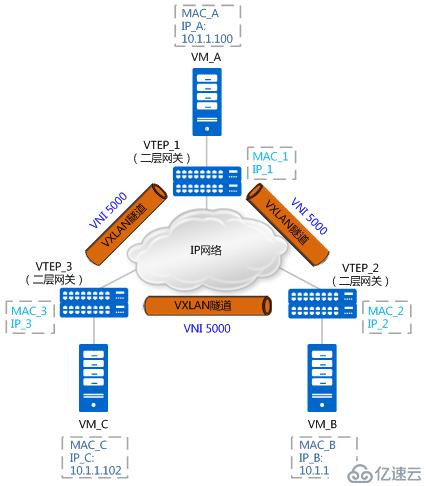
如上圖所示,假設vtep是通過接入交換機上的子接口實現,VM_A與VM_C進行首次進行通信。由于是,VM_A上沒有VM_C的MAC地址,所以會發送ARP廣播報文請求VM_C的MAC地址。就以ARP請求報文及ARP應答報文的轉發流程,來說明MAC地址是如何進行學習的。 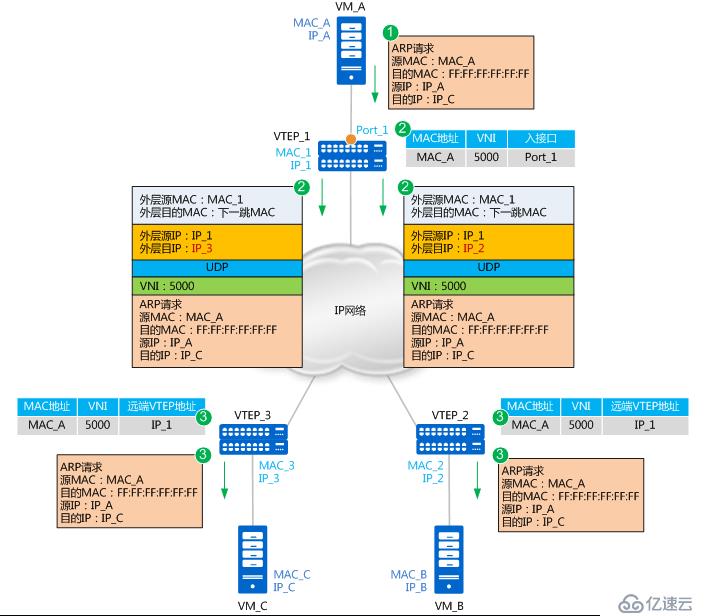
ARP請求報文的轉發流程如下:
1. VM_A發送源MAC為MAC_A、目的MAC為全F、源IP為IP_A、目的IP為IP_C的ARP廣播報文,請求VM_C的MAC地址。
2. VTEP_1收到這種BUM(Broadcast&Unknown-unicast&Multicast)請求后,會根據頭端復制列表對報文進行復制,并分別進行封裝。根據二層子接口上的配置判斷報文需要進入VXLAN隧道。確定了報文所屬BD后,也就確定了報文所屬的VNI。同時,VTEP_1學習MAC_A、VNI和報文入接口(Port_1,即二層子接口對應的物理接口)的對應關系,并記錄在本地MAC表中。
3. 報文到達VTEP_2和VTEP_3后,VTEP對報文進行解封裝,得到VM_A發送的原始報文。同時,VTEP_2和VTEP_3學習VM_A的MAC地址、VNI和遠端VTEP的IP地址(IP_1)的對應關系,并記錄在本地MAC表中。之后,VTEP_2和VTEP_3根據二層子接口上的配置對報文進行相應的處理并在對應的二層域內廣播。
VM_B和VM_C接收到ARP請求后,比較報文中的目的IP地址是否為本機的IP地址。VM_B發現目的IP不是本機IP,故將報文丟棄;VM_C發現目的IP是本機IP,則對ARP請求做出應答。
ARP應答報文轉發流程如下圖所示: 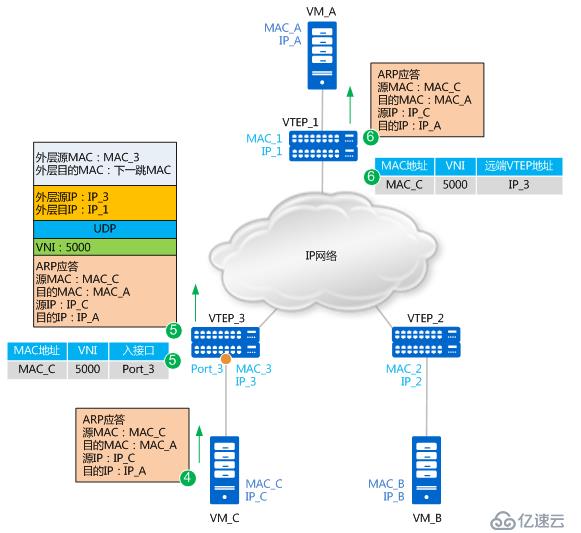
4. 由于此時VM_C上已經學習到了VM_A的MAC地址,所以ARP應答報文為單播報文,單播報文就不再進行頭端復制。報文源MAC為MAC_C,目的MAC為MAC_A,源IP為IP_C、目的IP為IP_A。
5. VTEP_3接收到VM_C發送的ARP應答報文后,識別報文所屬的VNI(識別過程與步驟2類似)。同時,VTEP_3學習MAC_C、VNI和報文入接口(Port_3)的對應關系,并記錄在本地MAC表中。之后,VTEP_3對報文進行封裝。這里封裝的外層源IP地址為本地VTEP(VTEP_3)的IP地址,外層目的IP地址為對端VTEP(VTEP_1)的IP地址;外層源MAC地址為本地VTEP的MAC地址,而外層目的MAC地址為去往目的IP的網絡中下一跳設備的MAC地址。封裝后的報文,根據外層MAC和IP信息,在IP網絡中進行傳輸,直至到達對端VTEP。
6. 報文到達VTEP_1后,VTEP_1對報文進行解封裝,得到VM_C發送的原始報文。同時,VTEP_1學習VM_C的MAC地址、VNI和遠端VTEP的IP地址(IP_3)的對應關系,并記錄在本地MAC表中。之后,VTEP_1將解封裝后的報文發送給VM_A。
至此,VM_A和VM_C均已學習到了對方的MAC地址。之后,VM_A和VM_C將采用單播方式進行通信。
不同子網vxlan通信流程 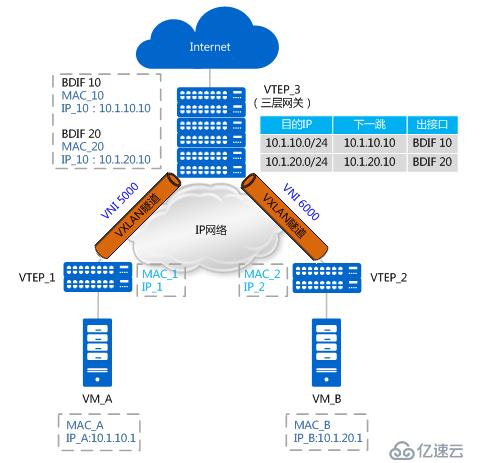
如上圖所示,VM_A和VM_B分別屬于10.1.10.0/24網段和10.1.20.0/24網段,且分別屬于VNI 5000和VNI 6000。VM_A和VM_B對應的三層網關分別是VTEP_3上BDIF 10和BDIF20的IP地址(BDIF接口的功能與VLANIF接口類似,是基于BD創建的三層邏輯接口,用以實現不同子網VM之間或VXLAN網絡與非VXLAN網絡之間的通信。)。VTEP_3上存在到10.1.10.0/24網段和10.1.20.0/24網段的路由。此時,VM_A想與VM_B進行通信。
由于是首次進行通信,且VM_A和VM_B處于不同網段,VM_A需要先發送ARP廣播報文請求網關(BDIF 10)的MAC,獲得網關的MAC后,VM_A先將數據報文發送給網關;之后網關也將發送ARP廣播報文請求VM_B的MAC,獲得VM_B的MAC后,網關再將數據報文發送給VM_B。以上MAC地址學習的過程與同子網互通中MAC地址學習的流程一致,不再贅述。現在假設VM_A和VM_B均已學到網關的MAC、網關也已經學到VM_A和VM_B的MAC,不同子網VM互通報文轉發流程如下圖所示: 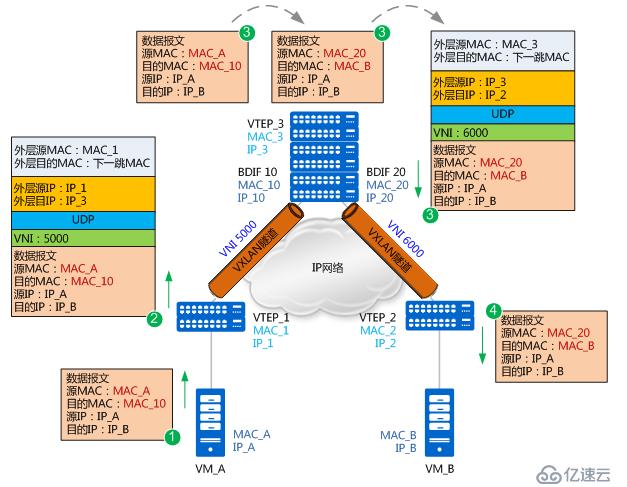
1. VM_A先將數據報文發送給網關。報文的源MAC為MAC_A,目的MAC為網關BDIF10的MAC_10,源IP地址為IP_A,目的IP為IP_B。
2. VTEP_1收到數據報文后,識別此報文所屬的VNI(VNI 5000),并根據MAC表項對報文進行封裝。這里封裝的外層源IP地址為本地VTEP的IP地址(IP_1),外層目的IP地址為對端VTEP的IP地址(IP_3);外層源MAC地址為本地VTEP的MAC地址(MAC_1),而外層目的MAC地址為去往目的IP的網絡中下一跳設備的MAC地址。
3. 報文進入VTEP_3,VTEP_3對報文進行解封裝,得到VM_A發送的原始報文。然后,VTEP_3會對報文做如下處理:
(1) VTEP_3發現該報文的目的MAC為本機BDIF 10接口的MAC,而目的IP地址為IP_B(10.1.20.1),所以會根據路由表查找到IP_B的下一跳。
(2) 發現下一跳為10.1.20.10,出接口為BDIF 20。此時VTEP_3查詢ARP表項,并將原始報文的源MAC修改為BDIF 20接口的MAC(MAC_20),將目的MAC修改為VM_B的MAC(MAC_B)。
(3) 報文到BDIF20接口時,識別到需要進入VXLAN隧道(VNI 6000),所以根據MAC表對報文進行封裝。這里封裝的外層源IP地址為本地VTEP的IP地址(IP_3),外層目的IP地址為對端VTEP的IP地址(IP_2);外層源MAC地址為本地VTEP的MAC地址(MAC_3),而外層目的MAC地址為去往目的IP的網絡中下一跳設備的MAC地址。
4. 報文到達VTEP_2后,VTEP_2對報文進行解封裝,得到內層的數據報文,并將其發送給VM_B。VM_B回應VM_A的流程與上述過程類似,不再贅述。
需要說明的是:VXLAN網絡與非VXLAN網絡之間的互通,也需要借助于三層網關。其實現不同點在于報文在VXLAN網絡側會進行封裝,而在非VXLAN網絡側不需要進行封裝。報文從VXLAN側進入網關并解封裝后,就按照普通的單播報文發送方式進行轉發。
ovs如何創建vxlan隧道
從前文得知,vtep部署在接入交換機上時還是會學習到vm的mac地址,并沒有解決表項限制問題,這也是為什么在公有云場景下vtep角色都是部署在宿主機的ovs中。
不同于在接入交換機上通過手動的方式建立vxlan隧道,openstack中負責網絡的neutron-server啟動后,會自己建立隧道,下面來介紹neutron-server如何自動建立隧道。 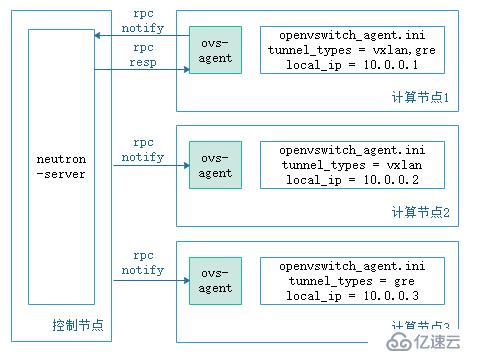
如上圖所示,每個宿主機上的ovs是由ovs-aget創建,當計算節點1接入網絡中時,他首先會去向neutron-server報告自己的網絡類型和local_ip,neutron-server收到這些資源信息后(neutron中network、port、subnet都稱為資源)會進行處理,找到相同網絡類型的其他計算節點并為他們之間創建隧道,同時將這個消息同步給其他計算節點上的ovs-agent。 
每當neutron資源發生變化時,或者ovs對流量不知該處和處理時,都會像neutron-server匯報或等待它的通知,再加上之前的流表,是不是感覺很熟悉?沒錯,neutron-server除了接受api請求外,他還是一個sdn控制器。
與接入交換機實現vtep的區別
1. 使用ovs實現的vtep接入交換機只會學習經過vtep封裝后的mac地址,學習不到vm的mac地址,這樣解決了mack地址表項的問題。
2. 物理交換機是通過bd和vni綁定的方法建立不同的隧道,ovs實現時每一個vtep內可以有多個vsi(virtual switch instance),每一個vsi對用一個vni。
以上就是vxlan在openstack中通過物理設備或者ovs實現的方式。
關于如何理解vxlan在openstack中的使用場景就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





