溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文介紹了非易失性內存在阿里巴巴集團生產環境的首次應用:線上運行的情況;使用NVM遇到的問題和優化的過程;最后,總結性地給出了基于NVM構建緩存服務的設計要點,希望這些實踐總結能對大家的工作有所啟發。

簡介
Tair MDB是阿里巴巴生態系統內廣泛使用的緩存服務,它采用非易失性內存 Non-volatile memory (NVM)作為DRAM的補充,輔助DRAM作為后端存儲介質,從天貓618購物節開始在生產環境上線灰度,經歷了2次全鏈路壓測,至今運行穩定。在使用NVM的過程中,Tair MDB遇到了寫不均衡、鎖開銷等問題,經過優化之后取得了非常顯著的效果。
通過這一系列優化工作和生產環境的實踐,Tair工程團隊總結出了一些在Non-volatile memory (NVM) / Persistent memory (PMEM)上實現緩存服務的設計準則,相信這些準則對其它有意愿使用Non-volatile memory來進行優化的產品會非常有指導意義。
背景
Tair Mdb主要服務于緩存場景,在阿里巴巴集團內部有著大量的部署和使用。隨著用戶態網絡協議棧、無鎖數據結構等特性的引入,單機QPS極限能力已經達到了1000w+的級別。Tair Mdb所有的數據都是存儲在內存中,隨著單機QPS極限能力的上升,內存容量逐漸成為限制集群規模的主要因素。
NVM產品單根DIMM的容量相對于DRAM DIMM要大很多,價格相對于DRAM更有優勢,將Tair Mdb的數據存放在NVM上,是突破單機內存容量的限制的一個方向。
生產環境
效果
端到端,讀寫平均延時和相同軟件版本下使用DRAM的節點數據持平;服務行為表現正常。生產環境的壓力并沒有達到Tair MDB節點的極限,后面的章節會介紹壓測時我們遇到的問題和解決方案。
成本
前面提到了單根NVM DIMM最大容量比DRAM DIMM要高,相同容量的價格會比DRAM便宜。Tair MDB容量型的集群,如果采用NVM來補充內存容量的不足,規模可以大幅減少。算上機器價格、電費、機架等因素,成本大約可以降低30% ~ 50%左右 。
原理
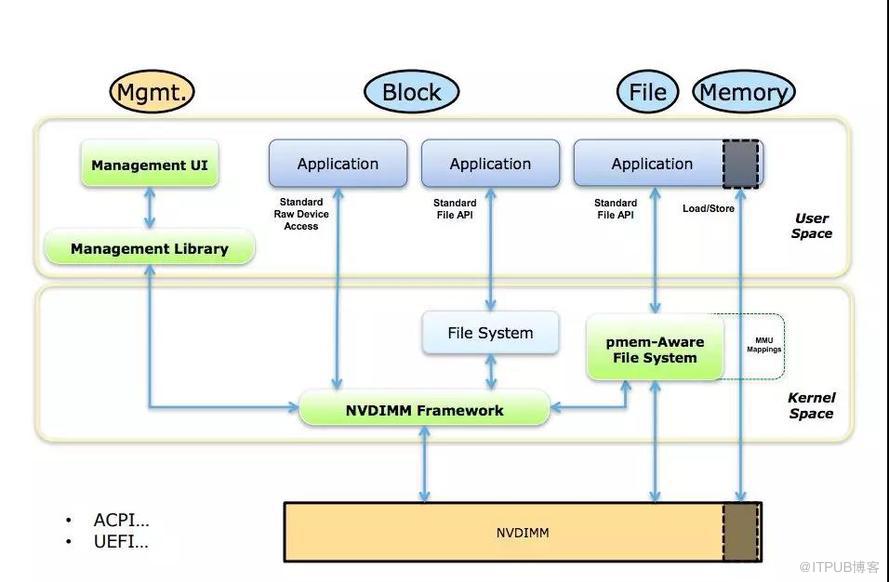
使用方式
Tair MDB使用NVM設備的方式,是把NVM以塊設備的形式使用Pmem-Aware File System掛載(DAX掛載模式)。分配NVM空間對應的操作是在對應的文件系統路徑上創建并打開文件,使用posix_fallocate分配空間。
內存分配器
NVM本身具備非易失的特性,對于緩存服務Tair MDB,是把NVM當作易失性設備,不需要去考慮操作的原子性和crash之后的recovery操作,也不需要顯式地調用clflush/clwb等命令將CPU Cache中的內容強制刷回介質。
使用DRAM空間時,有tcmalloc/jemalloc等內存分配器可供選擇,現在NVM的空間暴露給上層的是一個文件(或者是一個字符設備),所以如何使用內存分配器是首先需要考慮的事情。開源項目pmem[1]中維護了易失性的內存管理庫libmemkind,有易用的類malloc/free的API,大部分應用接入時可以考慮這種方式。
Tair MDB在實現時并沒有使用libmemkind[2]。下面介紹Tair MDB的內存布局,說明做出這種選擇的原因。
內存布局
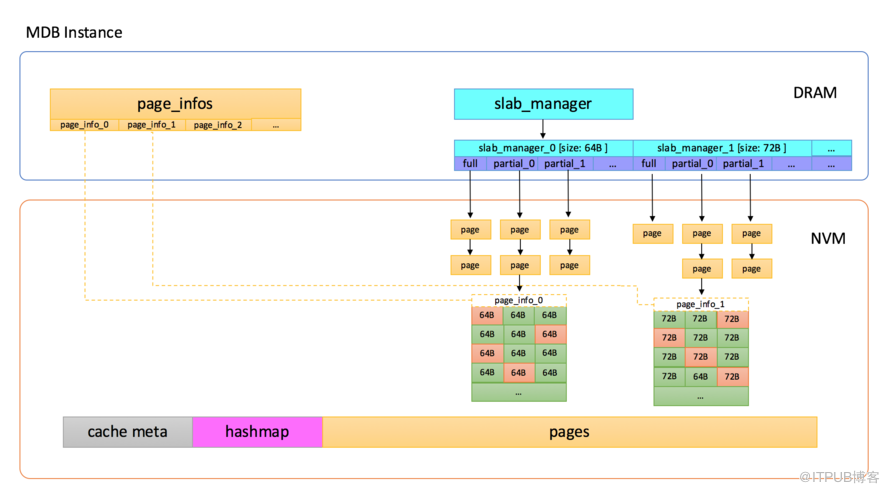
Tair MDB在內存管理上使用了slab機制,不是在使用時動態地分配匿名內存,而是在系統啟動時先分配一大塊內存,內置的內存管理模塊會把元數據、數據頁等在這一大塊內存上連續分布,如下圖所示:
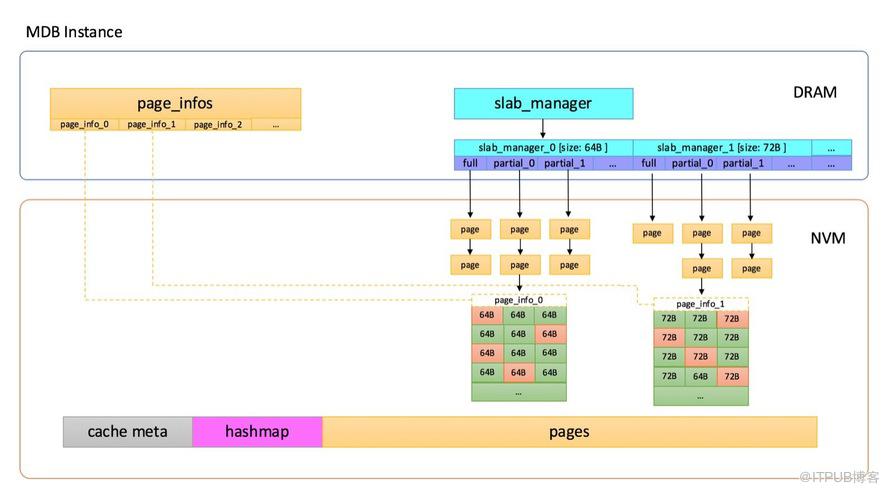 Tair MDB使用的內存主要分為以下幾部分:
Tair MDB使用的內存主要分為以下幾部分:
Cache Meta,存放了一些最大分片數之類的元數據信息,還有Slab Manager的索引信息。
Slab Manager,每個Slab Manager中管理固定大小的Slab。
Hashmap,全局哈希表索引,使用線性沖突鏈的方式處理哈希沖突,所有key的訪問都需要經過Hashmap。
Page pool,內存池,啟動之后會將內存劃分成以1M為單位的頁,Slab Manager會從Page pool中申請頁,并格式化成指定的slab大小。
Tair Mdb會在啟動時對所有可用的內存進行初始化,后續數據存儲部分不需要動態地從操作系統分配內存了。
在使用NVM時,把對應的文件mmap到內存,獲取虛擬地址空間,內置的內存管理模塊就可以透明地利用這塊空間了。所以在這個過程中,并不需要再調用malloc/free來管理NVM設備上的空間。
壓測
Tair MDB在使用NVM作為DRAM的補充,輔助DRAM作為后端存儲之后,在壓測過程中遇到了一些問題,在這一章節會介紹這些問題的具體表現和優化的方法。
問題
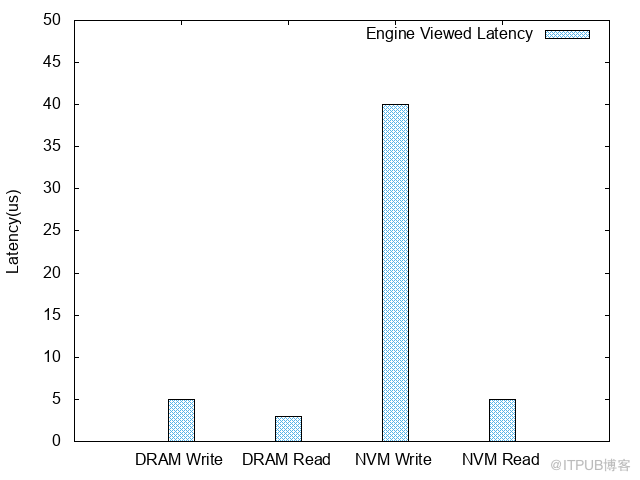
使用了NVM之后,使用100 bytes的條目對Tair MDB進行了壓測,得到如下的數據:
引擎內延遲
客戶端觀測QPS
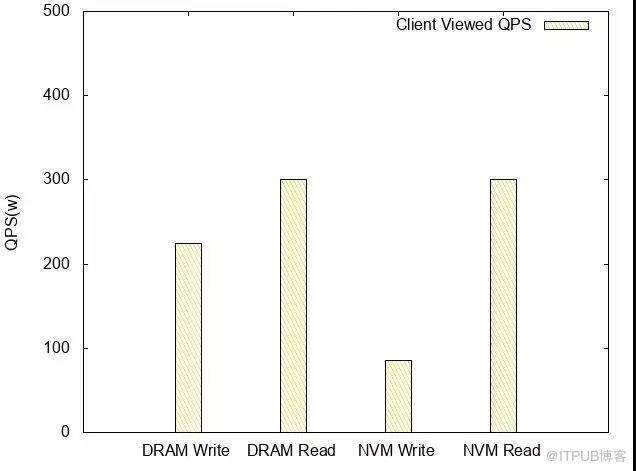
基于NVM的Read QPS /latency和DRAM相當,Write TPS大概是DRAM的1/3。
分析
寫性能的損耗從perf的結果上看都在鎖上,這個鎖管理的臨界區包含的是對上文內存布局中提到的Page的寫操作。懷疑這種情況是NVM上的寫延遲比DRAM上高導致的。
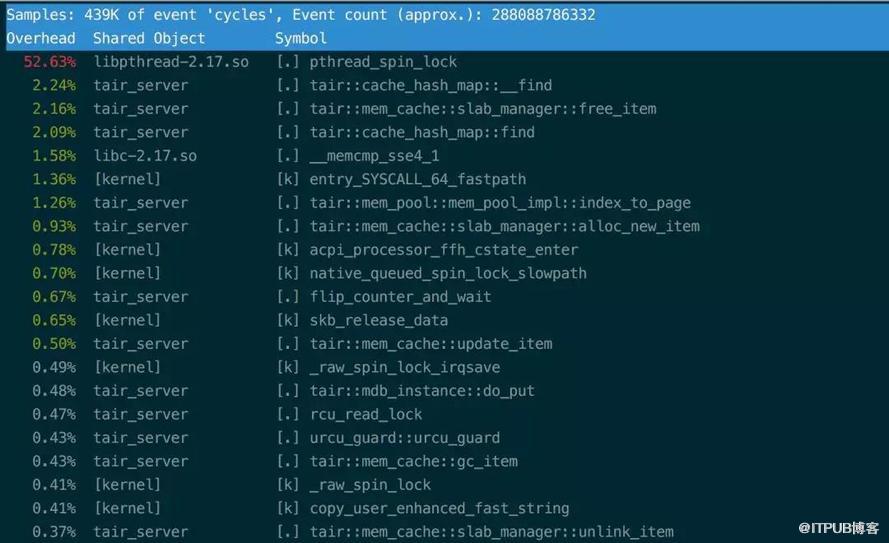 在壓測的過程中,使用pcm[3]查看NVM DIMMS的帶寬統計,觀察到在某一根DIMM上的寫非常不均衡,穩定情況下大約是其它DIMM的兩倍。
在壓測的過程中,使用pcm[3]查看NVM DIMMS的帶寬統計,觀察到在某一根DIMM上的寫非常不均衡,穩定情況下大約是其它DIMM的兩倍。
具體情況如下圖所示:
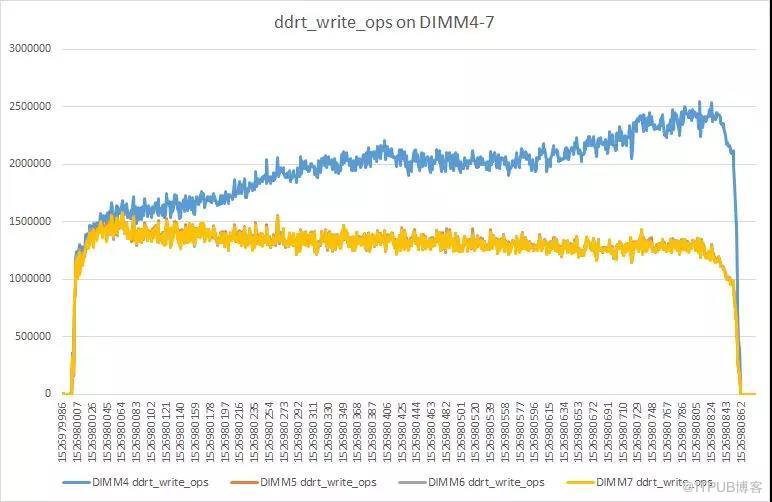
這里先大概介紹下NVM DIMM的放置策略。
放置策略
現在使用單socket放置了4根 NVM DIMM,具體分布類似下圖:
這種放置策略被稱為2-2-1。每一個socket有4根 DIMM,分別屬于四個不同的通道。在使用多個通道時,為了有效利用內存帶寬CPU會進行interleave。當前放置策略和配置下,CPU以4K為單位,按照DIMM順序進行interleave。

不均衡原因
從memory interleaving的策略,可以推斷每次都會寫同一個區域,而這片區域位于那根不均衡的DIMM上,導致這根DIMM的寫入量會明顯高于其它的DIMM。
那么接下來需要解決的問題就是找到導致寫熱點的處理邏輯。trivial的方法就是找些可疑的點,然后一個個排除下去,下面介紹下Tair工程團隊使用的方法。
優化
上面提到了,寫熱點導致NVM DIMM訪問不均衡,所以優化的第一步是先把寫熱點找出來,進行一些處理,比如說打散熱點訪問,或者把熱點訪問的區域放到DRAM中。
查找寫熱點
對于寫熱點的查找,Tair工程團隊使用了Pin[4]。上面提到Tair MDB是對文件進行mmap獲取邏輯地址來操作內存。于是我們可以使用Pin抓取mmap的返回值,進而得到NVM在程序內存空間中的邏輯地址。之后我們繼續使用Pin對所有操作內存的程序指令進行插樁,統計對NVM映射到的地址空間中的每個字節的寫入次數。
最終,發現寫熱點的確存在,相應的區域是Page的元數據。解決寫熱點的方案考慮過:加padding把熱點交錯到各個DIMM上、基本一樣熱的數據分DIMM存放、將熱點移回DRAM等,最終選擇將slab_manager和page_info移回DRAM。修改后結構如下:
至此,不均衡問題解決,TPS從85w提升至140w,此時引擎內寫延遲從40us降低到12us。
鎖開銷過大
當TPS在140w時,注意到上面提到過的pthread_spin_lock的開銷依然非常大。通過perf record的結果可以看到,pthread_spin_lock消耗的調用棧是:
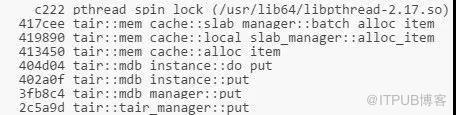
通過分析batch_alloc_item發現臨界區內對page中item的初始化操作會對NVM產生大量寫入。由于NVM的寫入速度比DRAM慢,所以這里成為一個很耗時的地方。
其實按照Tair MDB的邏輯,只有將page link進slab_manager的時候才需要加鎖。因此這里將對item的初始化操作移出臨界區。之后又對Tair MDB代碼中臨界區內所有對NVM的寫入操作進行了排查,并進行了相應的優化。
優化之后pthread_spin_lock開銷降低到正常范圍內,TPS提升至170w,此時引擎內寫延遲為9us。
優化結果
均衡寫負載、鎖粒度細化等優化有效地降低了Latency,TPS上升到了170w,相較之前的數據,TPS提高了100%。由于介質的差異,和DRAM的寫性能相比依然有30%左右的差距,但是對于緩存服務讀多寫少的場景,這個差距對整體的性能并不會有太大的影響。
設計指引
基于上述的優化工作和生產環境的實踐,Tair工程團隊總結了基于NVM實現緩存服務的設計準則,這些準則是和使用的硬件特性有緊密聯系的。
硬件特性
對緩存服務設計有影響的特有的NVM硬件特性:
相對于DRAM密度更高,更便宜
延遲相較DRAM高,帶寬比DRAM低
讀寫不均衡,寫延遲相較讀高
硬件有磨損,頻繁寫單一位置會加大磨損
設計準則
準則A:避免寫熱點
Tair MDB在使用NVM的過程中遇到過寫熱點的問題,寫熱點會加大介質的磨損,而且會導致負載不均衡(寫壓力在某一根DIMM上,不能充分利用所有DIMM的帶寬)。除了內存布局(元數據和數據混合存放)會導致寫熱點外,業務的訪問行為也會導致寫熱點。
這里,Tair工程團隊總結了幾種避免寫熱點的方法:
分離元數據和數據,將元數據移到DRAM中。元數據訪問頻率會相對于數據更高,前面提到的Tair MDB 中page_info屬于元數據。這樣可以從上層緩解NVM寫延遲相較DRAM高的劣勢。
上層實現Copy-On-Write的邏輯。這樣在一些場景下會減少對特定區域硬件的磨損,Tair MDB中更新一條數據時,并不會in-place update之前的條目,而是會新增條目添加到hashmap沖突鏈的頭部,異步刪除之前的條目。
常態檢測熱點寫,動態遷移到DRAM,執行寫合并。對于上面提到的業務訪問行為導致的熱點寫,Tair MDB會常態化檢測熱點寫,并把熱點寫進行合并,減少對下層介質的訪問。
準則B:減少臨界區訪問
由于NVM的寫延遲相較DRAM高,所以當臨界區中包含了對NVM的操作時,臨界區的影響會放大,導致上層的并發度降低。
前面提到的鎖開銷,Tair MDB運行在DRAM上時并沒有觀測到,原因是運行在DRAM上,假設了這個臨界區的開銷比較小,但是使用NVM時,這個假設不成立了。這也是在使用新介質時經常會遇到的問題,以往軟件流程中可能沒有意識到的一些假設,在新介質上不成立了,這時候就需要對原有的流程進行一些調整。
鑒于上面的原因,Tair工程團隊建議緩存服務使用NVM時,應該盡量地結合數據存儲做無鎖化的設計,減少臨界區的訪問,規避延遲升高帶來的級聯影響。
Tair MDB引入了用戶態RCU,對大部分訪問路徑上的操作進行了無鎖化改造,極大地降低了NVM延遲對上層帶來的影響。準則C:實現合適的分配器
分配器是業務使用NVM設備的基礎組件,分配器的并發度會直接影響軟件的效率,分配器的空間管理會決定空間利用率。設計實現或者選擇適合于軟件特性的分配器,是緩存服務使用NVM的關鍵。
從Tair MDB的實踐上來看,適用于NVM的分配器應該具備以下功能和特性:
碎片整理:由于NVM有密度更高、容量更大,所以在相同碎片率下,相較于DRAM會浪費更多的空間。由于碎片整理機制的存在,所以需要上層應用避免in-place update,而且盡量保證分配器分配的空間是fixed size。
需要有Threadlocal的quota:和上面說的減小臨界區訪問類似,如果沒有Threadlocal的quota,從全局的資源池中分配資源的延時會降低分配操作的并發度。
Capacity-aware,分配器需要感知所能管理的空間: 緩存服務需要對管理的空間進行擴容或者縮容,分配器需要提供相應的功能以適配這個需求。
以上這些設計準則都是在實踐中檢驗過,切實可行,而且會對應用帶來有利的影響,相信對其它希望使用NVM的產品也會有非常大的幫助。
未來的工作
上面提到了Tair MDB使用NVM時還是當作易失性的設備,利用了密度大價格低的優勢來降低整體服務的成本。未來Tair工程團隊會致力于更好地利用NVM的非易失特性,挖掘新硬件的紅利,賦能于業務和其它上層的服務。
本文是阿里巴巴集團存儲技術事業部Tair團隊關于NVM的系列分享的開篇,接下來會陸續推出我們在NVM領域的思考和成果。
分布式在線存儲系統Tair 專注于承擔超大流量下的在線訪問加速,阿里巴巴集團大規模使用,在每秒數億次訪問請求的背后,提供著超低延時的響應。場景包括各類在線緩存,內存數據庫,高性能持久化NoSQL數據庫等,在高并發,快速響應和高可用上追求極致。在這里,你會遇到億級別訪問的尖峰時刻,不同類型業務錯綜復雜的場景需求,萬臺規模服務器集群的運營支撐,業務全球化等各類技術挑戰。
本文作者
漠冰(付秋雷),阿里巴巴集團存儲技術事業部技術專家,主要關注于分布式緩存、NoSQL數據庫。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





