溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下用python批量獲取網頁圖片的方法,希望大家閱讀完這篇文章后大所收獲,下面讓我們一起去探討吧!
用python批量獲取網頁圖片的方法:1、通過url獲取目標文件源碼;2、處理【index.html】源碼中的圖片資源;3、保存【index.html】中的【css】文件;4、解碼base64格式的圖片并保存。

你可能需要的工作環境:
Python 3.6官網下載
我們這里以sogou作為爬取的對象。
首先我們進入搜狗圖片

進去后就是這個啦,然后F12進入開發人員選項,筆者用的是Chrome。
右鍵圖片>>檢查
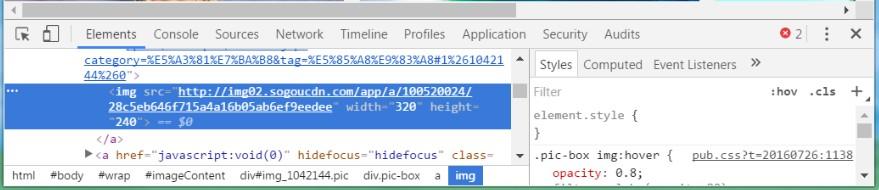
發現我們需要的圖片src是在img標簽下的,于是先試著用 Python 的 requests提取該組件,進而獲取img的src然后使用 urllib.request.urlretrieve逐個下載圖片,從而達到批量獲取資料的目的,思路好了,下面應該告訴程序要爬取的url為http://pic.sogou.com/pics/recommend?category=%B1%DA%D6%BD,此url來自進入分類后的地址欄。明白了url地址我們來開始愉快的代碼時間吧:
在寫這段爬蟲程序的時候,最好要逐步調試,確保我們的每一步操作正確,這也是程序猿應該有的好習慣。筆者不知道自己算不算個程序猿哈。線面我們來剖析該url指向的網頁。
import requests
import urllib
from bs4 import BeautifulSoup
res = requests.get('http://pic.sogou.com/pics/recommend?category=%B1%DA%D6%BD')
soup = BeautifulSoup(res.text,'html.parser')
print(soup.select('img'))output:

發現輸出內容并不包含我們要的圖片元素,而是只剖析到logo的img,這顯然不是我們想要的。也就是說需要的圖片資料不在url 即 http://pic.sogou.com/pics/recommend?category=%B1%DA%D6%BD里面。因此考慮可能該元素是動態的,細心的同學可能會發現,當在網頁內,向下滑動鼠標滾輪,圖片是動態刷新出來的,也就是說,該網頁并不是一次加載出全部資源,而是動態加載資源。這也避免了因為網頁過于臃腫,而影響加載速度。下面痛苦的探索開始了,我們是要找到所有圖片的真正的url 筆者也是剛剛接觸,找這個不是太有經驗。最后找的位置F12>>Network>>XHR>>(點擊XHR下的文件)>>Preview。
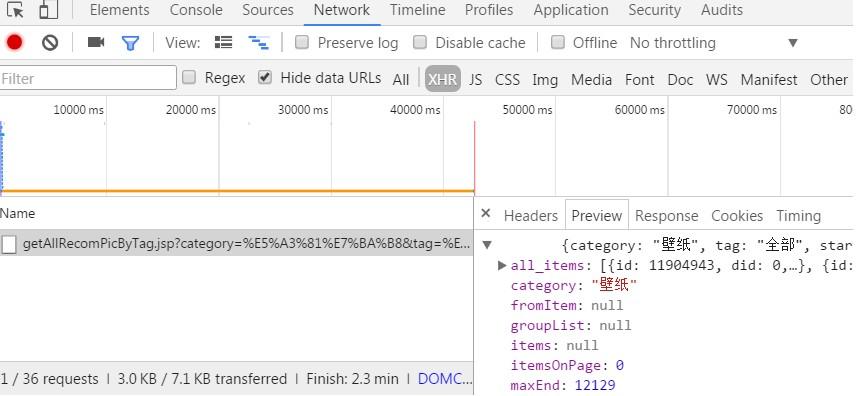
發現,有點接近我們需要的元素了,點開all_items 發現下面是0 1 2 3...一個一個的貌似是圖片元素。試著打開一個url。發現真的是圖片的地址。找到目標之后。點擊XHR下的Headers
得到第二行
Request URL:
http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category=%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=0&len=15&width=1536&height=864,試著去掉一些不必要的部分,技巧就是,刪掉可能的部分之后,訪問不受影響。經筆者篩選。最后得到的url:http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category=%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=0&len=15 字面意思,知道category后面可能為分類。start為開始下標,len為長度,也即圖片的數量。好了,開始愉快的代碼時間吧:
開發環境為Win7 Python 3.6,運行的時候Python需要安裝requests,
Python3.6 安裝requests 應該CMD敲入:
pip install requests
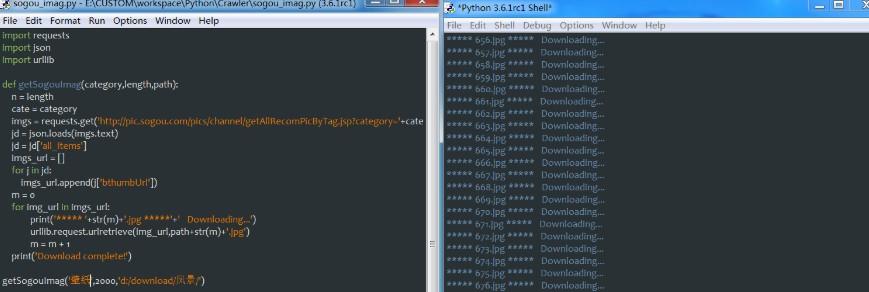
筆者在這里也是邊調試邊寫,這里把最終的代碼貼出來:
import requestsimport jsonimport urllibdef getSogouImag(category,length,path):
n = length
cate = category
imgs = requests.get('http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category='+cate+'&tag=%E5%85%A8%E9%83%A8&start=0&len='+str(n))
jd = json.loads(imgs.text)
jd = jd['all_items']
imgs_url = [] for j in jd:
imgs_url.append(j['bthumbUrl'])
m = 0 for img_url in imgs_url: print('***** '+str(m)+'.jpg *****'+' Downloading...')
urllib.request.urlretrieve(img_url,path+str(m)+'.jpg')
m = m + 1 print('Download complete!')
getSogouImag('壁紙',2000,'d:/download/壁紙/')程序跑起來的時候,筆者還是有點小激動的。來,感受一下:

至此,關于該爬蟲程序的編程過程敘述完畢。整體來看,找到需要爬取元素所在url,是爬蟲諸多環節中的關鍵。
看完了這篇文章,相信你對用python批量獲取網頁圖片的方法有了一定的了解,想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





