溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章運用簡單易懂的例子給大家介紹Reids數據類型的使用方法,代碼非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
1、Redis API
1.安裝redis模塊
$ pip3.8 install redis
2.使用redis模塊
import redis # 連接redis的ip地址/主機名,port,password=None r = redis.Redis(host="127.0.0.1",port=6379,password="gs123456")
3.redis連接池
redis-py使用connection pool來管理對一個redis server的所有連接,避免每次建立、釋放連接的開銷。默認,每個Redis實例都會維護一個自己的連接池。可以直接建立一個連接池,然后作為參數Redis,這樣就可以實現多個Redis實例共享一個連接池。
總之,當程序創建數據源實例時,系統會一次性創建多個數據庫連接,并把這些數據庫連接保存在連接池中,當程序需要進行數據庫訪問時,無需重新新建數據庫連接,而是從連接池中取出一個空閑的數據庫連接
import redis # 創建連接池,將連接保存在連接池中 pool = redis.ConnectionPool(host="127.0.0.1",port=6379,password="gs123456",max_connections=10) # 創建一個redis實例,并使用連接池"pool" r = redis.Redis(connection_pool=pool)
2、String 操作
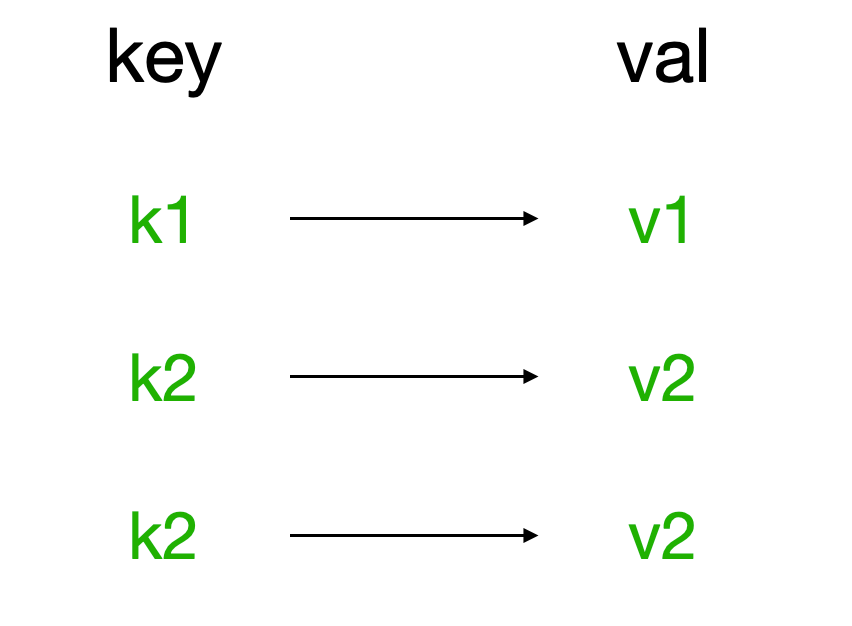
redis中的String在內存中按照一個name對應一個value來存儲。如圖:
1. set 為name設置值
# 在Redis中設置值,默認,不存在則創建,存在則修改 set(name, value, ex=None, px=None, nx=False, xx=False, keepttl=False) name:設置鍵 value:設置值 ex:設置過期時間(秒級) px:設置過期時間(毫秒) nx:如果設置為True,則只有name不存在時,當前set操作才執行,同setnx(name, value) xx:如果設置為True,則只有name存在時,當前set操作才執行
set用法:
r.set("name1","jack",ex=3600)
r.set("name2","xander",xx=36000)setnx用法:
# 設置值,只有name不存在時,執行設置操作(添加) setnx(name, value)
setex用法:
# 設置值,參數:time -->過期時間(數字秒 或 timedelta對象) setex(name, value, time)
psetex用法:
# 設置值,參數:time_ms,過期時間(數字毫秒 或 timedelta對象) psetex(name, time_ms, value)
2. get 獲取name的值
# 根據key獲取值
get(name)
r.get("foo")3. mset 批量設置name的值:
mset(mapping)
data = {
"k1":"v1",
"k2":"v2",
}
r.mset(data)4. Mget 批量獲取name的值
# 批量獲取值,根據多key獲取多個值
mgets(mapping)
# 方法一
r.mget("k1","k2")
# 方法二
data = ["k1","k2"]
r.mget(data)
# 方法三
data = ("k1","k2")
r.mget(data)5. getset 設置新值并獲取原來的值
getset(name, value)
r.set("foo", "xoo")
ret = r.getset("foo", "yoo")
print(ret) # b'xoo'6. append 為name原有值后追加內容
# key對應值的后面追加內容
append(key, value)
r.set("name","jack")
r.append("name","-m")
ret = r.get("name")
print(ret) # b'jack-m'7. strlen 返回name的值字節長度:
# 返回字符串的長度,當name不存在時返回0
strlen(name)
r.set("name","jack-")
ret = r.strlen("name")
print(ret) # 58. incr 為name整數累加值
# 自增mount對應的值,當mount不存在時,則創建mount=amount,否則,則自增,amount為自增數(整數)
incr(name, amount=1)
r.incr('mount')
r.incr('mount')
r.incr('mount', amount=3)
ret = r.get('mount')
print(ret) # b'5'3、Hash 操作
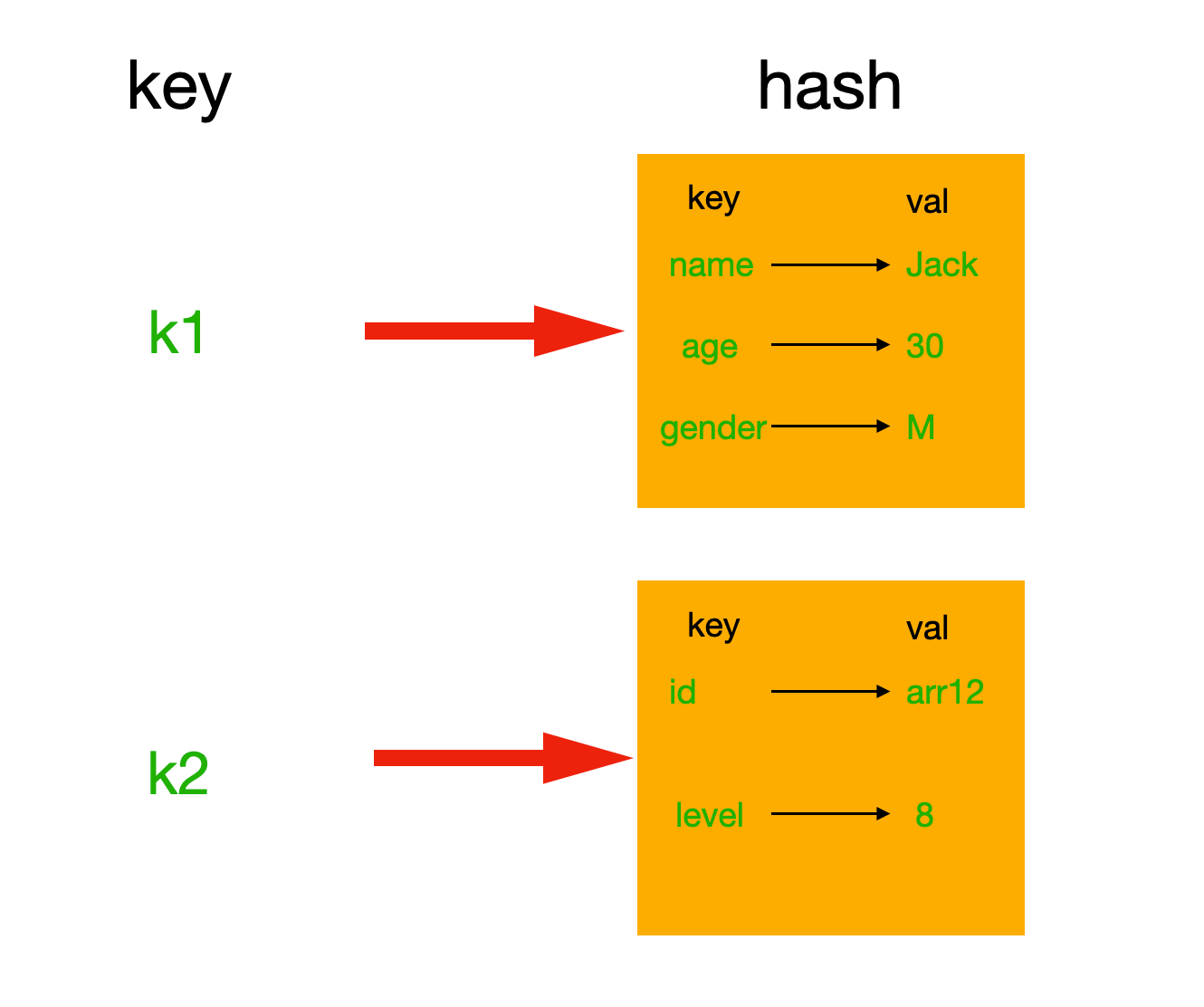
hash表現形式上有些像pyhton中的dict,可以存儲一組關聯性較強的數據 ,redis中Hash在內存中的存儲格式如下圖:
1. hset 為name設置單個鍵值對
# name對應的hash中設置一個鍵值對(不存在,則創建;否則,修改) hset(name, key, value) name:設置name key:name對應hash中的key(鍵) value:name對應的hash中的value(值)
hset用法
# 一次只能設置一個鍵值對
r.hset("student-jack", "name", "Jack")2 . hget 獲取name單個鍵值對
# 根據name對應的hash中獲取根據key獲取value
hget(name,key)
ret = r.hget("student-jack", "name")
print(ret) // b'Jack'3. hmset 為name設置多個鍵值對
# mapping中傳入字典(不存在,則創建;否則,修改)
hmset(name, mapping):
data = {
"name": "Jack",
"age": 20,
"gender": "M",
}
r.hmset("student-jack", mapping=data)4. hmget 獲取name多個鍵值對
# 根據name對應的hash中獲取多個key的值
hmget(name, keys, *args)
name:指定name
keys:要獲取key集合,如:['k1', 'k2', 'k3']
*args:要獲取的key,如:k1,k2,k3
# 直接傳入需要獲取的鍵
ret = r.hmget("student-jack", "name", "age")
print(ret) # [b'Jack', b'20']
# 列表中指定需要獲取的鍵
data = ["name", "age"]
ret = r.hmget("student-jack", data)
print(ret) # [b'Jack', b'20']5. hgetall 獲取name的鍵值對
# 根據name獲取hash的所有值
hgetall(name)
ret = r.hgetall("student-jack")
print(ret) # {b'name': b'Jack', b'age': b'20', b'gender': b'M'}6、hlen 獲取name中的鍵值對個數
# 根據name獲取hash中鍵值對的總個數
hlen(name)
ret = r.hlen("student-jack")
print(ret) # 3 , 3個鍵值對7. hkeys 獲取name中鍵值對所有key
# 獲取name里鍵值對的key
hkeys(name)
ret = r.hkeys('student-jack')
print(ret) # [b'name', b'age', b'gender']8. hvals 獲取name中鍵值對所有value
# 獲取name里鍵值對的value
hvals(name)
ret = r.hvals('student-jack')
print(ret) # [b'Jack', b'20', b'M']9. hkeys 檢查name里的鍵值對是否有對應的key
# 根據name檢查對應的hash是否存在當前傳入的key
hexists(name, key)
# 返回布爾值
ret = r.hexists('student-jack', 'name')
print(ret) # True10. hincrby 從name里的鍵值對設置自增值
1.整數自增:
# 自增name對應的hash中的指定key的值,不存在則創建key=amount
hincrby(name, key, amount=1)
name:設置鍵
key:hash對應的key
amount:自增數(整數)
ret = r.hincrby('student-jack', 'age')
ret = r.hincrby('student-jack', 'age')
print(ret) # 222.浮點自增
# 自增name對應的hash中的指定key的值,不存在則創建key=amount hincrbyfloat(name, key, amount=1.0) name:設置鍵 key:hash對應的key amount:自增數(浮點數)
11. hdel 根據name從鍵值對中刪除指定key
# 根據name將對應hash中指定的key鍵值對刪除
hdel(name,*keys)
r.hdel("info",*("m-k1","m-k2"))4、List 操作
List操作,redis中的List在內存中按照一個name對應一個List來存儲。如圖:

1. lpush 為name添加元素,每個新的元素都添加到列表的最左邊
# name對應的list中添加元素
lpush(name,values)
# 直接指定多個元素
r.lpush("names", "Jack", "Alex", "Eric")
# 將需要添加的元素添加到元組
data = ("Jack", "Alex", "Eric")
r.rpush("names", *data)
# 將需要添加的元素添加到列表
data = ["Jack", "Alex", "Eric"]
r.rpush("names", *data)Note:列表類型中的值統稱元素
2. rpush 為name添加元素,每個新的元素都添加到列表的最右邊
# 同lpush,但每個新的元素都會添加到列表的最右邊 rpush(name, values)
3. lpushx 為name添加元素,只有當name已存在時,將元素添加至列表最左邊
lpushx(name,value)
4. rpushx 同上,將元素添加至列表最右邊
rpushx(name, values)
5. llen 統計name中list的元素個數
# name對應的list元素的個數
llen(name)
ret = r.llen('names')
print(ret) # 3, 該list中有3個元素6. linsert 為name中list的某一個值或后 插入一個新的值
# 在name對應的列表的某一個值前或后插入一個新值
linsert(name, where, refvalue, value)
name:設置name
where:BEFORE或AFTER
refvalue:標桿值,即:在它前后插入數據
value:要插入的數據
// 在Alex值前插入一個值(BEFORE表示:在...之前)
r.linsert('names', 'BEFORE', 'Jack', 'Jason')
// 在Jack后插入一個值(AFTER表示:在...之后)
r.linsert('names', 'AFTER', 'Jack', 'Xander')7. lset 為name中list的某一個索引位置的元素重新賦值
# 對name對應的list中的某一個索引位置重新賦值
lset(name, index, value)
name:設置name
index:list的索引位置
value:要設置的值
// 將索引為1的元素修改為Gigi
r.lset('names', 1, 'Gigi')8. lrem 移除name里對應list的元素
# 在name對應的list中刪除指定的值
lrem(name, count, value)
name:設置name
value:要刪除的值
count:count=0,刪除列表中的指定值;
count=2,從前到后,刪除2個;
count=-2,從后向前,刪除2個
r.lrem('names', count=2, value='Xander')9. lpop 從name里的list獲取最左側的第一個元素,并在列表中移除,返回值是則是第一個元素
lpop(name)
ret = r.lpop('names')
print(ret) # b'Jason'10. rpop 同上,從右側獲取第一個元素
rpop(name)
11. lindex 在name對應的列表 根據索引獲取元素
# 在name對應的列表中根據索引獲取列表元素
lindex(name, index)
ret = r.lindex('names', 0)
print(ret) # b'Gigi'12. ltrim 移除列表內沒有在該索引之內的值(截斷)
# 移除列表內沒有在該索引之內的值
ltrim(name, start, end)
r.ltrim("names",0,2)13. lrange 在name對應的列表 根據索引獲取數據
# 在name對應的列表分片獲取數據
lrange(name, start, end)
name:設置name
start:索引的起始位置
end:索引結束位置
// 先添加點元素
data = ['Jack', 'Eric', 'Koko', 'Jason', 'Alie']
r.rpush('names', *data)
// 獲取列表所有元素
ret = r.lrange('names', 0, -1)
print(ret) # [b'Gigi', b'Alex', b'Jack', b'Eric', b'Koko', b'Jason', b'Alie']
// 獲取列表索引2-5的元素(包含2和5,即 2 3 4 5)
ret = r.lrange('names', 2, 5)
print(ret) # [b'Jack', b'Eric', b'Koko', b'Jason']
// 獲取列表的最后一個元素
ret = r.lrange('names', -1, -1)
print(ret) # [b'Alie']關于Reids數據類型的使用方法就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





