溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關Scrapy爬蟲容易忽視的點,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
scrapy爬蟲注意事項
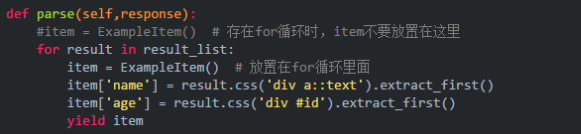
一、item數據只有最后一條
這種情況一般存在于對標簽進行遍歷時,將item對象放置在了for循環的外部。解決方式:將item放置在for循環里面。
二、item字段傳遞后錯誤,混亂
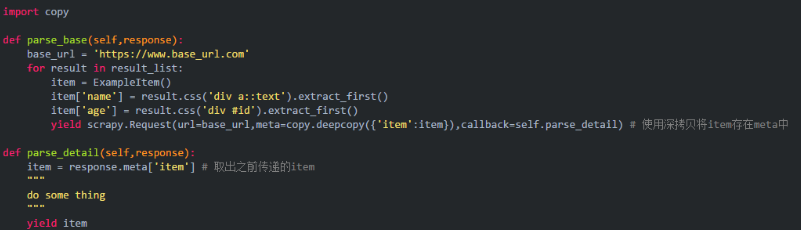
有時候會遇到這樣的情況,item傳遞幾次之后,發現不同頁面的數據被混亂的組合在了一起。這種情況一般存在于item的傳遞過程中,沒有使用深拷貝。解決方式:使用深拷貝來傳遞item。
三、對一個頁面要進行兩種或多種不同的解析
這種情況一般出現在對同一頁面有不同的解析要求時,但默認情況下只能得到第一個parse的結果。產生這個結果的原因是scrapy默認對擁有相同的url,相同的body以及相同的請求方法視為一個請求。解決方式:設置參數dont_filter='True'。

四、xpath中contains的使用
這種情況一般出現在標簽沒有特定屬性值但是文本中包含特定漢字的情況,當然也可以用來包含特定的屬性值來使用(只不過有特定屬性值的時候我也不會用contains了)。
作者:村上春樹
書名:挪威的森林
以上面這兩個標簽為例(自行F12查看),兩個span標簽沒有特定的屬性值,但里面一個包含作者,一個包含書名,就可以考慮使用contains來進行提取。

五、提取不在標簽中的文本
有時候會遇到這樣的情況,文本在兩個標簽之間,但不屬于這兩個標簽的任何一個。此時可以考慮使用xpath的contains和following共同協助完成任務。
示例:
作者:
"村上春樹"
書名
"挪威的森林"

六、使用css、xpath提取倒數第n個標簽
對于很多頁面,標簽的數量有時候無法保證是一致的。如果用正向的下標進行提取,很可能出現數組越界的情況。這種時候可以考慮反向提取,必要時加一些判斷。

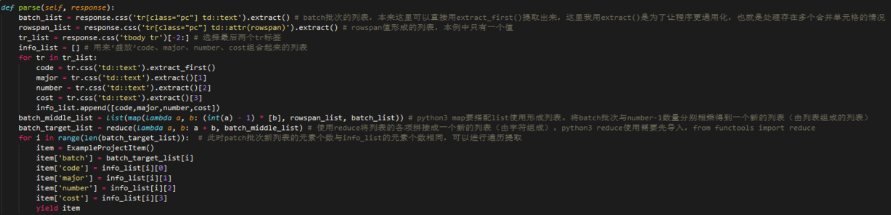
七、提取表格信息
其實對于信息抓取,很多時候我們需要對表格頁面進行抓取。一般的方方正正的表格提取相對簡單,這里不討論。只說下含有合并單元格的情況。
以這個網頁的表格為例,定義5個字段批次,招生代碼,專業,招生數量以及費用,注意到合并單元格的標簽里有個rowspan屬性,可以用來辨識出有幾行被合并。我的思路是有多少行數據,就將batch批次擴展到多少個,形成一個新的列表,然后進行遍歷提取數據。
八、模擬登陸
當頁面數據需要登陸進行抓取時,就需要模擬登陸了。常見的方式有:使用登陸后的cookie來抓取數據;發送表單數據進行登陸;使用自動化測試工具登陸,比如selenium配合chrome、firefox等,不過聽說selenium不再更新,也可以使用chrome的無頭模式。鑒于自動化測試的抓取效率比較低,而且我確實很久沒使用過這個了。本次只討論使用cookie和發送表單兩種方式來模擬登陸。
使用cookie
使用cookie的方式比較簡單,基本思路就是登陸后用抓包工具或者類似chrome的F12調試界面查看cookie值,發送請求時帶上cookie值即可。
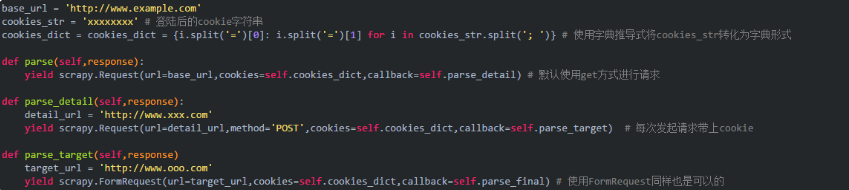
發送表單方式進行登陸
cookie是有有效期的,對于大量數據的抓取,更好的方式是發送表單進行模擬登陸。scrapy有專門的函數scrapy.FormRequest()用來處理表單提交。網上有些人說cookie沒法保持,可以考慮用我下面的方式。

看完上述內容,你們對Scrapy爬蟲容易忽視的點有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





