溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關將Numpy加速700倍的方法,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
作為 Python 語言的一個擴展程序庫,Numpy 支持大量的維度數組與矩陣運算,為 Python 社區帶來了很多幫助。借助于 Numpy,數據科學家、機器學習實踐者和統計學家能夠以一種簡單高效的方式處理大量的矩陣數據。那么 Numpy 速度還能提升嗎?本文介紹了如何利用 CuPy 庫來加速 Numpy 運算速度。
就其自身來說,Numpy 的速度已經較 Python 有了很大的提升。當你發現 Python 代碼運行較慢,尤其出現大量的 for-loops 循環時,通常可以將數據處理移入 Numpy 并實現其向量化最高速度處理。
但有一點,上述 Numpy 加速只是在 CPU 上實現的。由于消費級 CPU 通常只有 8 個核心或更少,所以并行處理數量以及可以實現的加速是有限的。
這就催生了新的加速工具——CuPy 庫。
何為 CuPy?

CuPy 是一個借助 CUDA GPU 庫在英偉達 GPU 上實現 Numpy 數組的庫。基于 Numpy 數組的實現,GPU 自身具有的多個 CUDA 核心可以促成更好的并行加速。
CuPy 接口是 Numpy 的一個鏡像,并且在大多情況下,它可以直接替換 Numpy 使用。只要用兼容的 CuPy 代碼替換 Numpy 代碼,用戶就可以實現 GPU 加速。
CuPy 支持 Numpy 的大多數數組運算,包括索引、廣播、數組數學以及各種矩陣變換。
如果遇到一些不支持的特殊情況,用戶也可以編寫自定義 Python 代碼,這些代碼會利用到 CUDA 和 GPU 加速。整個過程只需要 C++格式的一小段代碼,然后 CuPy 就可以自動進行 GPU 轉換,這與使用 Cython 非常相似。
在開始使用 CuPy 之前,用戶可以通過 pip 安裝 CuPy 庫:
pip install cupy
使用 CuPy 在 GPU 上運行
為符合相應基準測試,PC 配置如下:
i7–8700k CPU 1080 Ti GPU 32 GB of DDR4 3000MHz RAM CUDA 9.0
CuPy 安裝之后,用戶可以像導入 Numpy 一樣導入 CuPy:
import numpy as np import cupy as cp import time
在接下來的編碼中,Numpy 和 CuPy 之間的切換就像用 CuPy 的 cp 替換 Numpy 的 np 一樣簡單。如下代碼為 Numpy 和 CuPy 創建了一個具有 10 億 1』s 的 3D 數組。為了測量創建數組的速度,用戶可以使用 Python 的原生 time 庫:
### Numpy and CPU s = time.time() *x_cpu = np.ones((1000,1000,1000))* e = time.time() print(e - s)### CuPy and GPU s = time.time() *x_gpu = cp.ones((1000,1000,1000))* e = time.time() print(e - s)
這很簡單!
令人難以置信的是,即使以上只是創建了一個數組,CuPy 的速度依然快得多。Numpy 創建一個具有 10 億 1』s 的數組用了 1.68 秒,而 CuPy 僅用了 0.16 秒,實現了 10.5 倍的加速。
但 CuPy 能做到的還不止于此。
比如在數組中做一些數學運算。這次將整個數組乘以 5,并再次檢查 Numpy 和 CuPy 的速度。
### Numpy and CPU s = time.time() *x_cpu *= 5* e = time.time() print(e - s)### CuPy and GPU s = time.time() *x_gpu *= 5* e = time.time() print(e - s)
果不其然,CuPy 再次勝過 Numpy。Numpy 用了 0.507 秒,而 CuPy 僅用了 0.000710 秒,速度整整提升了 714.1 倍。
現在嘗試使用更多數組并執行以下三種運算:
數組乘以 5
數組本身相乘
數組添加到其自身
### Numpy and CPU s = time.time() *x_cpu *= 5 x_cpu *= x_cpu x_cpu += x_cpu* e = time.time() print(e - s)### CuPy and GPU s = time.time() *x_gpu *= 5 x_gpu *= x_gpu x_gpu += x_gpu* e = time.time() print(e - s)
數組大小(數據點)達到 1000 萬,運算速度大幅度提升
使用 CuPy 能夠在 GPU 上實現 Numpy 和矩陣運算的多倍加速。值得注意的是,用戶所能實現的加速高度依賴于自身正在處理的數組大小。下表顯示了不同數組大小(數據點)的加速差異:
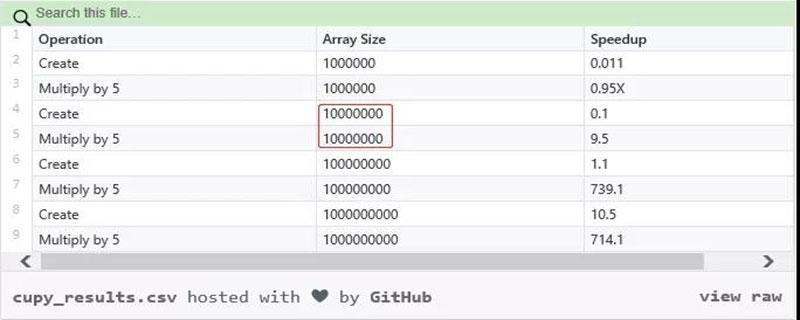
數據點一旦達到 1000 萬,速度將會猛然提升;超過 1 億,速度提升極為明顯。Numpy 在數據點低于 1000 萬時實際運行更快。此外,GPU 內存越大,處理的數據也就更多。所以用戶應當注意,GPU 內存是否足以應對 CuPy 所需要處理的數據。
關于將Numpy加速700倍的方法就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





