溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Python3爬蟲實戰中爬取豆瓣電影的方法是什么,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
爬蟲又稱為網頁蜘蛛,是一種程序或腳本。
但重點在于,它能夠按照一定的規則,自動獲取網頁信息。
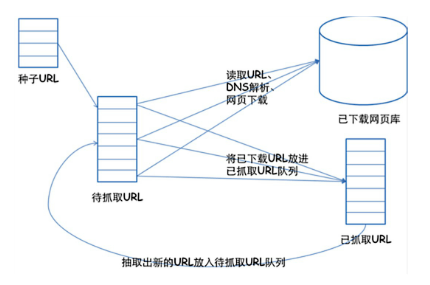
爬蟲的基本原理——通用框架
1.挑選種子URL;
2.講這些URL放入帶抓取的URL列隊;
3.取出帶抓取的URL,下載并存儲進已下載網頁庫中。此外,講這些URL放入帶抓取URL列隊,進入下一循環。
4.分析已抓取列隊中的URL,并且將URL放入帶抓取URL列隊,從而進去下一循環。
爬蟲獲取網頁信息和人工獲取信息,其實原理是一致的。
如我們要獲取電影的“評分”信息

人工操作步驟:
1.獲取電影信息的網頁;
2.定位(找到)要評分信息的位置;
3.復制、保存我們想要的評分數據。
爬蟲操作步驟:
1.請求并下載電影頁面信息;
2.解析并定位評分信息;
3.保存評分數據。
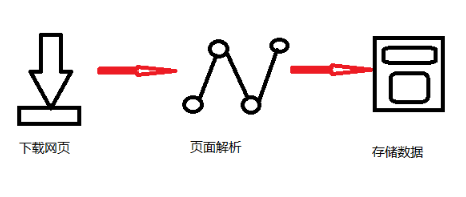
爬蟲的基本流程
簡單來說,我們向服務器發送請求后,會得到返回的頁面,通過解析頁面后,我們可以抽取我們想要的那部分信息,并存儲在指定文檔或數據庫中,這樣,我們想要的信息會被我們“爬”下來了。
python中用于爬蟲的包很多,如bs4,urllib,requests等等。這里我們用requests+xpath的方式,因為簡單易學,像BeautifulSoup還是有點難的。
下面我們就使用requests和xpath來爬取豆瓣電影中的“電影名”、“導演”、“演員”、“評分”等信息。
安裝requests和lxml庫:
pip install requests pip install lxml
一、導入模塊
#-*- coding:utf-8 -*- import requests from lxml import etree import time #這里導入時間模塊,以免豆瓣封你IP
二、獲取豆瓣電影目標網頁并解析
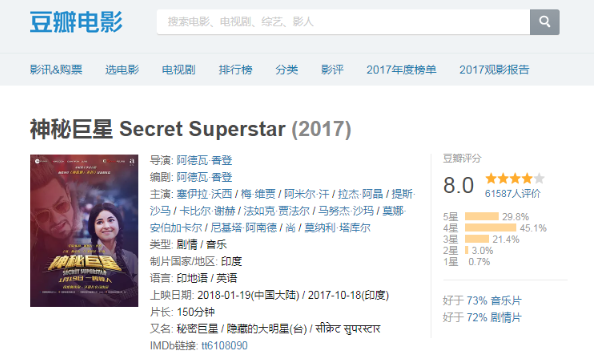
爬取豆瓣電影《神秘巨星》上的一些信息,地址
https://movie.douban.com/subject/26942674/?from=showing
#-*- coding:utf-8 -*- import requests from lxml import etree import time url = 'https://movie.douban.com/subject/26942674/' data = requests.get(url).text s=etree.HTML(data) #給定url并用requests.get()方法來獲取頁面的text,用etree.HTML() #來解析下載的頁面數據“data”。
1.獲取電影名稱。
獲取電影的xpath信息并獲得文本
s.xpath('元素的xpath信息/text()')這里的xpath信息要手動獲取,獲取方式如下:
1.如果你是用谷歌瀏覽器的話,鼠標“右鍵”–>“檢查元素”;
2.Ctrl+Shift+C將鼠標定位到標題;
3.“右鍵”–>“Copy”–>“Copy Xpath”就可以復制xpath。
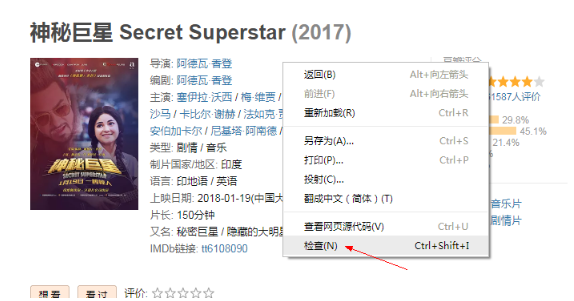
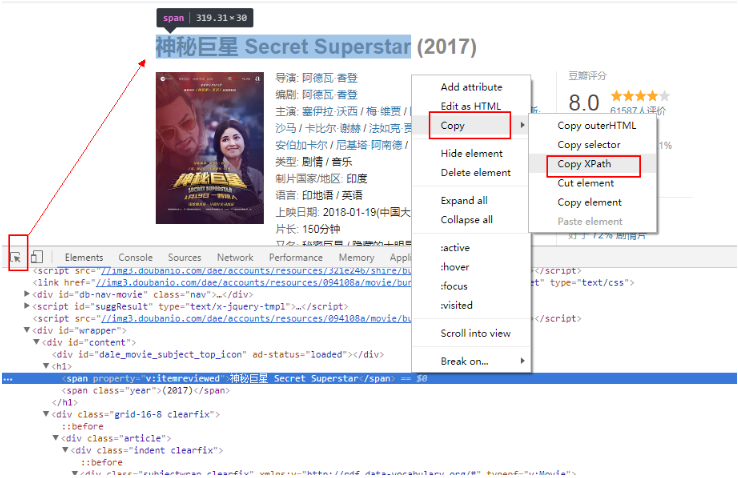
這樣,我們就把電影標題的xpath信息復制下來了。
//*[@id="content"]/h2/span[1]
放到代碼中并打印信息
#-*- coding:utf-8 -*-
import requests
from lxml import etree
import time
url = 'https://movie.douban.com/subject/26942674/'
data = requests.get(url).text
s=etree.HTML(data)
film_name = s.xpath('//*[@id="content"]/h2/span[1]/text()')
print("電影名:",film_name)這樣,我們爬取豆瓣電影中《神秘巨星》的“電影名稱”信息的代碼已經完成了,可以在eclipse中運行代碼。
得到如下結果:
電影名: ['神秘巨星 Secret Superstar']
OK,邁出了第一步,我們繼續抓取導演、主演、評分;
film_name=s.xpath('//*[@id="content"]/h2/span[1]/text()')#電影名
director=s.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')#編劇
actor1=s.xpath('//*[@id="info"]/span[3]/span[2]/a[1]/text()')#主演1
actor2=s.xpath('//*[@id="info"]/span[3]/span[2]/a[2]/text()')#主演2
actor3=s.xpath('//*[@id="info"]/span[3]/span[2]/a[3]/text()')#主演3
actor4=s.xpath('//*[@id="info"]/span[3]/span[2]/a[4]/text()')#主演4
movie_time=s.xpath('//*[@id="info"]/span[13]/text()')#片長觀察上面的代碼,發現獲取不同主演時,區別只在于“a[x]”中“x”的值不同。實際上,要一次性獲取所有主演信息時,用不加數字的“a”即可獲取。
如下:
actors = s.xpath('//*[@id="info"]/span[3]/span[2]/a/text()')#所有主演所以我們修改好的完整代碼如下:
#-*- coding:utf-8 -*-
import requests
from lxml import etree
import time
url1 = 'https://movie.douban.com/subject/26942674/'
data = requests.get(url1).text
s=etree.HTML(data)
film_name=s.xpath('//*[@id="content"]/h2/span[1]/text()')#電影名
director=s.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')#編劇
actor=s.xpath('//*[@id="info"]/span[3]/span[2]/a/text()')#主演
movie_time=s.xpath('//*[@id="info"]/span[13]/text()')#片長
#由于導演有時候不止一個人,所以我這里以列表的形式輸出
ds = []
for d in director:
ds.append(d)
#由于演員不止一個人,所以我這里以列表的形式輸出
acs = []
for a in actor:
acs.append(a)
print ('電影名:',film_name)
print ('導演:',ds)
print ('主演:',acs)
print ('片長:',movie_time)結果輸出:
電影名: ['神秘巨星 Secret Superstar'] 導演: ['阿德瓦·香登'] 主演: ['塞伊拉·沃西', '梅·維賈', '阿米爾·汗', '拉杰·阿晶', '提斯·沙馬', '卡比爾·謝赫', '法如克·賈法爾', '馬努杰·沙瑪', '莫娜·安伯加卡爾', '尼基塔·阿南德', '尚', '莫納利·塔庫爾'] 片長: ['150分鐘']
怎么樣,是不是很簡單啊。趕快去試試吧~~~
這里順便補充點基礎知識:
Requests常用的七種方法:
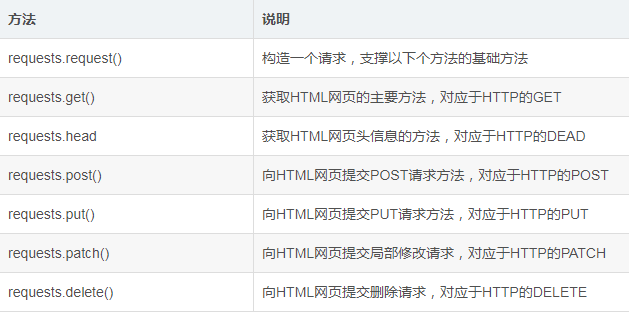
目前,我們只需要掌握最常用的requests.get()方法就好了。
requests.get()的使用方法
import requests url = 'https://www.baidu.com' data = requests.get(url)#使用get方法發送請求,返回汗網頁數據的Response并存儲到對象data 中
Repsonse對象的屬性:
data.status_code:http請求的返回狀態,200表示連接成功;
data.text:返回對象的文本內容;
data.content:猜測返回對象的二進制形式;
data.encoding:返回對象的編碼方式;
data.apparent_encoding:響應內容編碼方式。
關于Python3爬蟲實戰中爬取豆瓣電影的方法是什么就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





