溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹使用hbase的優點有哪些,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
hbase是運行在Hadoop上的NoSQL數據庫,它是一個分布式的和可擴展的大數據倉庫,也就是說HBase能夠利用HDFS的分布式處理模式,并從Hadoop的MapReduce程序模型中獲益。這意味著在一組商業硬件上存儲許多具有數十億行和上百萬列的大表。除去Hadoop的優勢,HBase本身就是十分強大的數據庫,它能夠融合key/value存儲模式帶來實時查詢的能力,以及通過MapReduce進行離線處理或者批處理的能力。總的來說,Hbase能夠讓你在大量的數據中查詢記錄,也可以從中獲得綜合分析報告。
谷歌曾經面對過一個挑戰的問題:如何能在整個互聯網上提供實時的搜索結果?答案是它本質上需要將互聯網緩存,并重新定義在這樣龐大的緩存上快速查找的新方法。為了達到這個目的,定義如下技術:
·谷歌文件系統GFS:可擴展分布式文件系統,用于大型的、分布式的、數據密集型的應用程序。
·BigTable:分布式存儲系統,用于管理被設計成規模很大的結構化數據:來自數以千計商用服務器的PB級別的數據。
·MapReduce:一個程序模型,用于處理和生成大數據集的相關實現。
在谷歌發布這些技術的文檔之后,不久以后我們就看到了它們的開源實現版本,就在2007年,MikeCafarella發布了BigTable開源實現的代碼,他稱其為HBase,自此,HBase成為Apache的頂級項目,并運行在Facebook,Twitter,Adobe……僅舉幾個例子。
HBase不是一個關系型數據庫,它需要不同的方法定義你的數據模型,HBase實際上定義了一個四維數據模型,下面就是每一維度的定義:
·行鍵:每行都有唯一的行鍵,行鍵沒有數據類型,它內部被認為是一個字節數組。
·列簇:數據在行中被組織成列簇,每行有相同的列簇,但是在行之間,相同的列簇不需要有相同的列修飾符。在引擎中,HBase將列簇存儲在它自己的數據文件中,所以,它們需要事先被定義,此外,改變列簇并不容易。
·列修飾符:列簇定義真實的列,被稱之為列修飾符,你可以認為列修飾符就是列本身。
·版本:每列都可以有一個可配置的版本數量,你可以通過列修飾符的制定版本獲取數據。
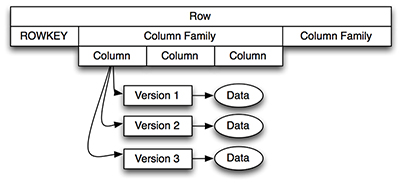
Figure1.HBaseFour-Dimensional Data Model
如圖1中所示,通過行鍵獲取一個指定的行,它由一個或多個列簇構成,每個列簇有一個或多個列修飾符(圖1中稱為列),每列又可以有一個或多個版本。為了獲取指定數據,你需要知道它的行鍵、列簇、列修飾符以及版本。當設計HBase數據模型時,對考慮數據是如何被獲取是十分有幫助的。你可以通過以下兩種方式獲得HBase數據:
·通過他們的行鍵,或者一系列行鍵的表掃描。
·使用map-reduce進行批操作
這種雙重獲取數據的方法使得HBase變得十分強大,典型地,在Hadoop中存儲數據意味著它對離線或批處理方式分析是有益的(尤其是批處理分析),但是,對實時獲取是不必要的。HBase通過key/value存儲來支持實時分析,以及通過map-reduce支持批處理分析。讓我們首先來看實時數據獲取,作為key/value存儲,key是行鍵,value是列簇的集合,如圖2所示。
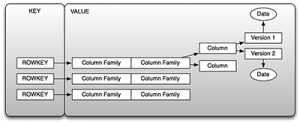
Figure2.HBaseas a Key/Value Store
如你在圖2中看到的,key是我們所提到過的行鍵,value是列簇的集合。你可以通過key檢索到value,或者換句話說,你可以通過行鍵“得到”行,或者你能通過給定起始和終止行鍵檢索一系列行,這就是前面提到的表掃描。你不能實時的查詢一個列的值,這就引出了一個重要的話題:行鍵的設計。
有兩個原因令行鍵的設計十分重要:
·表掃描是對行鍵的操作,所以,行鍵的設計控制著你能夠通過HBase執行的實時/直接獲取量。
·當在生產環境中運行HBase時,它在HDFS上部運行,數據基于行鍵通過HDFS,如果你所有的行鍵都是以user-開頭,那么很有可能你大部分數據都被分配一個節點上(違背了分布式數據的初衷),因此,你的行鍵應該是有足夠的差異性以便分布式地通過整個部署。
你定義行鍵的方式取決于你想怎樣存取那些行。如果你想以用戶為基礎存儲數據,那么一個策略是利用字節隊列在HBase中存儲行鍵,所以我們可以創建一個用戶ID的哈希(例如MD5或SHA-1),然后在哈希后面附上時間(long類型)。使用哈希有兩個重點:(1)是它能夠將value分散開,數據能夠分布式地通過簇,(2)是它確保key的長度是一致的,以更加容易在表掃描中使用。
講了足夠多的理論,下面部分向你展示如何搭建HBase環境,并如何通過命令行使用。
你可以從Apache網站下載HBase,在寫本文時,最新的版本是0.98.5,HBase團隊推薦你在UNIX/Linux環境下安裝HBase,如果你想在Windows下運行,你需要先安裝Cygwin,并在這上運行HBase。當你下載完這些文件,解壓到硬盤上。此外,你還需要安裝Java環境,如果你還沒有,從Oracle網站下載Java環境。在環境配置中添加名為HBASE_HOME的變量,值為你解壓HBase文件的根目錄,隨后,執行bin文件夾下的start-hbase.sh腳本,它會在下面目錄輸出日志文件:
$HBASE_HOME/logs/
你可以在瀏覽器中輸入下面URL測試是否安裝正確:
http://localhost:60010
如果安裝正確,你應該看到下面界面。
Figure3.HBaseManagement Screen
讓我們開始用命令行操作HBase,在HBasebin目錄下執行下面命令:
./hbase shell
你應該看到如下類似的輸出:
HBase Shell; enter'help' for list of supported commands. Type "exit" toleave the HBase Shell Version0.98.5-hadoop2, rUnknown, MonAug4 23:58:06 PDT2014 hbase(main):001:0>
創建一個名為PageViews的表,并具有名為info的列簇:
hbase(main):002:0> create'PageViews', 'info' 0 row(s) in 5.3160seconds => Hbase::Table- PageViews
每張表至少要有一個列簇,因此我們創建了info,現在,看看我們的表,執行下面list命令:
hbase(main):002:0>list TABLE PageViews 1 row(s) in 0.0350seconds =>["PageViews"]
如你所見,list命令返回一個名為PageViews的表,我們可以通過describe命令得到表的更多信息:
hbase(main):003:0> describe'PageViews'
DESCRIPTIONENABLED
'PageViews',{NAME => 'info', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER=> 'ROW',
REPLICATION_SCOPE=> '0', VERSIONS => '1', COMPRESSION => 'NONEtrue
',MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS=> 'false',
BLOCKSIZE=> '65536', IN_MEMORY => 'false', BLOCKCACHE =>'true'}
1 row(s) in 0.0480secondsDescribe命令返回表的詳細信息,包括列簇的列表,這里我們創建的僅有一個:info,現在為表添加以下數據,下面命令是在info中添加新的行:
hbase(main):004:0> put'PageViews', 'rowkey1', 'info:page', '/mypage' 0 row(s) in 0.0850seconds
Put命令插入一條行鍵為rowkey1的新紀錄,指定在info下的page列,插入值為/mypage的記錄,我們隨后可以通過get命令通過行鍵rowkey1查詢到這條記錄:
hbase(main):005:0> get'PageViews', 'rowkey1' COLUMNCELL info:pagetimestamp=1410374788088, value=/mypage 1 row(s) in 0.0250seconds
你可以看到列info:page,或者更多具體的列,其值為/mypage,并帶有時間戳表明該條記錄是什么時候插入的。讓我們在做表掃描之前再添加一行:
hbase(main):006:0> put'PageViews', 'rowkey2', 'info:page', '/myotherpage' 0 row(s) in 0.0050seconds
現在我們有兩行記錄了,讓我們查詢出PageViews表的所有記錄:
hbase(main):007:0> scan'PageViews' ROWCOLUMN+CELL rowkey1column=info:page, timestamp=1410374788088, value=/mypage rowkey2column=info:page, timestamp=1410374823590,value=/myotherpage 2 row(s) in 0.0350seconds
如前面所提到的,我們不能查詢本身,但是我們可以對表進行scan操作,如果你執行scantable命令,它會返回表中所有行,這很有可能不是你想要做的。你可以給出行的范圍來限制返回的結果,讓我們插入一帶有s開頭行鍵的新記錄:
hbase(main):012:0> put'PageViews', 'srowkey2', 'info:page', '/myotherpage'
現在,如果我增加點限制,想查詢行鍵在r和s之間的記錄,可以使用如下結構:
hbase(main):014:0> scan'PageViews', { STARTROW => 'r', ENDROW => 's' }
ROWCOLUMN+CELL
rowkey1column=info:page, timestamp=1410374788088, value=/mypage
rowkey2column=info:page, timestamp=1410374823590,value=/myotherpage
2 row(s) in 0.0080seconds這個scan返回了僅有s開頭的記錄,這個類比是基于全行鍵上的,所以rowkey1比r大,所有它被返回了。另外,scan的結果包含了所指范圍的STARTROW,但不包含ENDROW,注意,ENDROW不是必須指定的,如果我們執行相同查詢只給出了STARTROW,那么我們會得到行鍵比r大的所有記錄。
hbase(main):013:0> scan'PageViews', { STARTROW => 'r' }
ROWCOLUMN+CELL
rowkey1column=info:page, timestamp=1410374788088, value=/mypage
rowkey2column=info:page, timestamp=1410374823590,value=/myotherpage
srowkey2column=info:page,timestamp=1410375975965, value=/myotherpage
3 row(s) in 0.0120secondsHBase是一種NoSQL,通常被稱為Hadoop Database,它是開源并基于Google BigTable白皮書,HBase運行在HDFS之上,因此使它具有高度可擴展性,并支持Hadoopmap-reduce程序設計模型。HBase有兩種訪問方式:通過行鍵進行隨機訪問;通過map-reduce脫機或批訪問。
關于使用hbase的優點有哪些就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





