溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關JDK源碼中實用的小技巧有哪些的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
1 i++ vs i--
String源碼的第985行,equals方法中
while (n--!= 0) {
if (v1[i] != v2[i])
return false;
i++;
}這段代碼是用于判斷字符串是否相等,但有個奇怪地方是用了i--!=0來做判斷,我們通常不是用i++么?為什么用i--呢?而且循環次數相同。原因在于編譯后會多一條指令:
i-- 操作本身會影響CPSR(當前程序狀態寄存器),CPSR常見的標志有N(結果為負), Z(結果為0),C(有進位),O(有溢出)。i > 0,可以直接通過Z標志判斷出來。
i++操作也會影響CPSR(當前程序狀態寄存器),但只影響O(有溢出)標志,這對于i < n的判斷沒有任何幫助。所以還需要一條額外的比較指令,也就是說每個循環要多執行一條指令。
簡單來說,跟0比較會少一條指令。所以,循環使用i--,高端大氣上檔次。
2 成員變量 vs 局部變量
JDK源碼在任何方法中幾乎都會用一個局部變量來接受成員變量,比如
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;因為局部變量初始化后是在該方法線程棧中,而成員變量初始化是在堆內存中,顯然前者更快,所以,我們在方法中盡量避免直接使用成員變量,而是使用局部變量。
3 刻意加載到寄存器 && 將耗時操作放到鎖外部
在ConcurrentHashMap中,鎖segment的操作很有意思,它不是直接鎖,而是類似于自旋鎖,反復嘗試獲取鎖,并且在獲取鎖的過程中,會遍歷鏈表,從而將數據先加載到寄存器中緩存中,避免在鎖的過程中在便利,同時,生成新對象的操作也是放到鎖的外部來做,避免在鎖中的耗時操作
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
/** 在往該 segment 寫入前,需要先獲取該 segment 的獨占鎖
不是強制lock(),而是進行嘗試 */
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);scanAndLockForPut()源碼
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
// 循環獲取鎖
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
//該hash位無值,新建對象,而不用再到put()方法的鎖中再新建
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
//該hash位置key也相同,退化成自旋鎖
else if (key.equals(e.key))
retries = 0;
else
// 循環鏈表,cpu能自動將鏈表讀入緩存
e = e.next;
}
// retries>0時就變成自旋鎖。當然,如果重試次數如果超過 MAX_SCAN_RETRIES(單核1多核64),那么不搶了,進入到阻塞隊列等待鎖
// lock() 是阻塞方法,直到獲取鎖后返回,否則掛起
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
// 這個時候是有大問題了,那就是有新的元素進到了鏈表,成為了新的表頭
// 所以這邊的策略是,相當于重新走一遍這個 scanAndLockForPut 方法
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}4 判斷對象相等可先用==
在判斷對象是否相等時,可先用==,因為==直接比較地址,非常快,而equals的話會最對象值的比較,相對較慢,所以有可能的話,可以用a==b || a.equals(b)來比較對象是否相等
5 關于transient
transient是用來阻止序列化的,但HashMap源碼中內部數組是定義為transient的
/** * The table, resized as necessary. Length MUST Always be a power of two. */ transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
那豈不里面的鍵值對都無法序列化了么,網絡中用hashmap來傳輸豈不是無法傳輸,其實不然。
Effective Java 2nd, Item75, Joshua大神提到:
For example, consider the case of a hash table. The physical
representation is a sequence of hash buckets containing key-value
entries. The bucket that an entry resides in is a function of the hash
code of its key, which is not, in general, guaranteed to be the same
from JVM implementation to JVM implementation. In fact, it isn't even
guaranteed to be the same from run to run. Therefore, accepting the
default serialized form for a hash table would constitute a serious
bug. Serializing and deserializing the hash table could yield an
object whose invariants were seriously corrupt.
怎么理解? 看一下HashMap.get()/put()知道, 讀寫Map是根據Object.hashcode()來確定從哪個bucket讀/寫. 而Object.hashcode()是native方法, 不同的JVM里可能是不一樣的.
打個比方說, 向HashMap存一個entry, key為 字符串"STRING", 在第一個java程序里, "STRING"的hashcode()為1, 存入第1號bucket; 在第二個java程序里, "STRING"的hashcode()有可能就是2, 存入第2號bucket. 如果用默認的串行化(Entry[] table不用transient), 那么這個HashMap從第一個java程序里通過串行化導入第二個java程序后, 其內存分布是一樣的, 這就不對了.
舉個例子,比如向HashMap存一個鍵值對entry, key="方老司", 在第一個java程序里, "方老司"的hashcode()為1, 存入table[1],好,現在傳到另一個在JVM程序里, "方老司" 的hashcode()有可能就是2, 于是到table[2]去取,結果值不存在。
HashMap現在的readObject和writeObject是把內容 輸出/輸入, 把HashMap重新生成出來.
6 不要用char
char在Java中utf-16編碼,是2個字節,而2個字節是無法表示全部字符的。2個字節表示的稱為 BMP,另外的作為high surrogate和 low surrogate 拼接組成由4字節表示的字符。比如String源碼中的indexOf:
//這里用int來接受一個char,方便判斷范圍
public int indexOf(int ch, int fromIndex) {
final int max = value.length;
if (fromIndex < 0) {
fromIndex = 0;
} else if (fromIndex >= max) {
// Note: fromIndex might be near -1>>>1.
return -1;
}
//在Bmp范圍
if (ch < Character.MIN_SUPPLEMENTARY_CODE_POINT) {
// handle most cases here (ch is a BMP code point or a
// negative value (invalid code point))
final char[] value = this.value;
for (int i = fromIndex; i < max; i++) {
if (value[i] == ch) {
return i;
}
}
return -1;
} else {
//否則轉到四個字節的判斷方式
return indexOfSupplementary(ch, fromIndex);
}
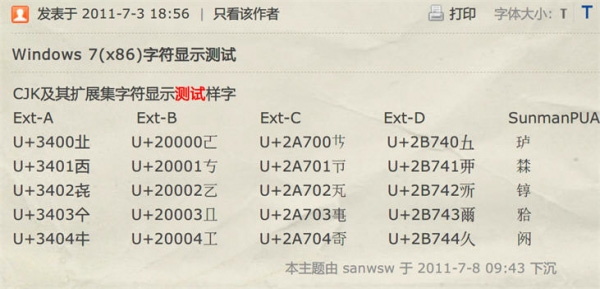
}所以Java的char只能表示utf­16中的bmp部分字符。對于CJK(中日韓統一表意文字)部分擴展字符集則無法表示。
例如,下圖中除Ext-A部分,char均無法表示。
此外還有一種說法是要用char,密碼別用String,String是常量(即創建之后就無法更改),會保存到常量池中,如果有其他進程可以dump這個進程的內存,那么密碼就會隨著常量池被dump出去從而泄露,而char[]可以寫入其他的信息從而改變,即是被dump了也會減少泄露密碼的風險。
但個人認為你都能dump內存了難道是一個char能夠防范的住的?除非是String在常量池中未被回收,而被其它線程直接從常量池中讀取,但恐怕也是非常罕見的吧。
感謝各位的閱讀!關于“JDK源碼中實用的小技巧有哪些”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





