溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關Java中怎么讀寫字符流文件,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
基類 Reader/Writer
在正式學習字符流基類之前,我們需要知道 Java 中是如何表示一個字符的。
首先,Java 中的默認字符編碼為:UTF-8,而我們知道 UTF-8 編碼的字符使用 1 到 4 個字節進行存儲,越常用的字符使用越少的字節數。
而 char 類型被定義為兩個字節大小,也就是說,對于通常的字符來說,一個 char 即可存儲一個字符,但對于一些增補字符集來說,往往會使用兩個 char 來表示一個字符。
Reader 作為讀字符流的基類,它提供了最基本的字符讀取操作,我們一起看看。
先看看它的構造器:
protected Object lock;
protected Reader() {
this.lock = this;
}
protected Reader(Object lock) {
if (lock == null) {
throw new NullPointerException();
}
this.lock = lock;
}Reader 是一個抽象類,所以毋庸置疑的是,這些構造器是給子類調用的,用于初始化 lock 鎖對象,這一點我們后續會詳細解釋。
public int read() throws IOException {
char cb[] = new char[1];
if (read(cb, 0, 1) == -1)
return -1;
else
return cb[0];
}
public int read(char cbuf[]) throws IOException {
return read(cbuf, 0, cbuf.length);
}
abstract public int read(char cbuf[], int off, int len)基本的讀字符操作都在這了,第一個方法用于讀取一個字符出來,如果已經讀到了文件末尾,將返回 -1,同樣的以 int 作為返回值類型接收,為什么不用 char?原因是一樣的,都是由于 -1 這個值的解釋不確定性。
第二個方法和第三個方法是類似的,從文件中讀取指定長度的字符放置到目標數組當中。第三個方法是抽象方法,需要子類自行實現,而第二個方法卻又是基于它的。
還有一些方法也是類似的:
public long skip(long n):跳過 n 個字符
public boolean ready():下一個字符是否可讀
public boolean markSupported():見 reset 方法
public void mark(int readAheadLimit):見 reset 方法
public void reset():用于實現重復讀操作
abstract public void close():關閉流
這些個方法其實都見名知意,并且和我們的 InputStream 大體上都差不多,都沒有什么核心的實現,這里不再贅述,你大致知道它內部有些個什么東西即可。
Writer 是寫的字符流,它用于將一個或多個字符寫入到文件中,當然具體的 write 方法依然是一個抽象的方法,待子類來實現,所以我們這里亦不再贅述了。
適配器 InpustStramReader/OutputStreamWriter
適配器字符流繼承自基類 Reader 或 Writer,它們算是字符流體系中非常重要的成員了。主要的作用就是,將一個字節流轉換成一個字符流,我們先以讀適配器為例。
首先就是它最核心的成員:
private final StreamDecoder sd;
StreamDecoder 是一個解碼器,用于將字節的各種操作轉換成字符的相應操作,關于它我們會在后續的介紹中不間斷的提到它,這里不做統一的解釋。
然后就是構造器:
public InputStreamReader(InputStream in) {
super(in);
try {
sd = StreamDecoder.forInputStreamReader(in, this, (String)null);
} catch (UnsupportedEncodingException e) {
throw new Error(e);
}
}
public InputStreamReader(InputStream in, String charsetName)
throws UnsupportedEncodingException
{
super(in);
if (charsetName == null)
throw new NullPointerException("charsetName");
sd = StreamDecoder.forInputStreamReader(in, this, charsetName);
}這兩個構造器的目的都是為了初始化這個解碼器,都調用的方法 forInputStreamReader,只是參數不同而已。我們不妨看看這個方法的實現:
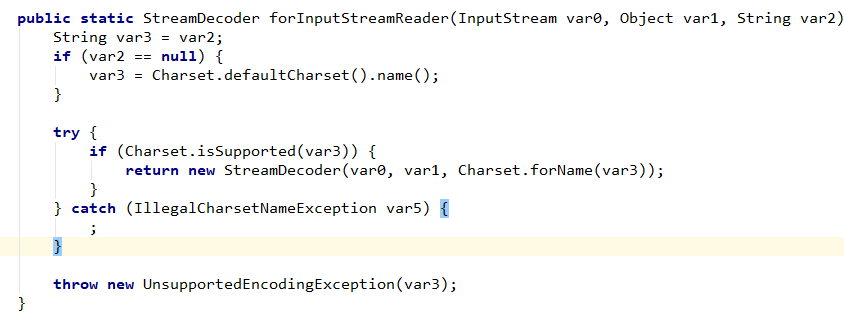
這是一個典型的靜態工廠模式,三個參數,var0 和 var1 沒什么好說的,分別代表的是字節流實例和適配器實例。
而參數 var2 其實代表的是一種字符編碼的名稱,如果為 null,那么將使用系統默認的字符編碼:UTF-8 。
最終我們能夠得到一個解碼器實例。
接著介紹的所有方法幾乎都是依賴的這個解碼器而實現的。
public String getEncoding() {
return sd.getEncoding();
}
public int read() throws IOException {
return sd.read();
}
public int read(char cbuf[], int offset, int length){
return sd.read(cbuf, offset, length);
}
public void close() throws IOException {
sd.close();
}解碼器中相關的方法的實現代碼還是相對復雜的,這里我們不做深入的研究,但大體上的實現思路就是:「字節流讀取 + 解碼」的過程。
當然了,OutputStreamWriter 中必然也存在一個相反的 StreamEncoder 實例用于編碼字符。
除了這一點外,其余的操作并沒有什么不同,或是通過字符數組向文件中寫入,或是通過字符串向文件中寫入,又或是通過 int 的低 16 位向文件中寫入。
文件字符流 FileReader/Writer
文件的字符流可以說非常簡單了,除了構造器,就不存在任何其他方法了,完全依賴文件字節流。
我們以 FileReader 為例,
FileReader 繼承自 InputStreamReader,有且僅有以下三個構造器:
public FileReader(String fileName) throws FileNotFoundException {
super(new FileInputStream(fileName));
}
public FileReader(File file) throws FileNotFoundException {
super(new FileInputStream(file));
}
public FileReader(FileDescriptor fd) {
super(new FileInputStream(fd));
}理論上來說,所有的字符流都應當以我們的適配器為基類,因為只有它提供了字符到字節之間的轉換,無論你是寫或是讀都離不開它。
而我們的 FileReader 并沒有擴展任何一個自己的方法,父類 InputStreamReader 中預實現的字符操作方法對他來說已經足夠,只需要傳入一個對應的字節流實例即可。
FileWriter 也是一樣的,這里不再贅述了。
字符數組流 CharArrayReader/Writer
字符數組和字節數組流是類似的,都是用于解決那種不確定文件大小,而需要讀取其中大量內容的情況。
由于它們內部提供動態擴容機制,所以既可以完全容納目標文件,也可以控制數組大小,不至于分配過大內存而浪費了大量內存空間。
先以 CharArrayReader 為例
protected char buf[];
public CharArrayReader(char buf[]) {
this.buf = buf;
this.pos = 0;
this.count = buf.length;
}
public CharArrayReader(char buf[], int offset, int length){
//....
}構造器核心任務就是初始化一個字符數組到內部的 buf 屬性中,以后所有對該字符數組流實例的讀操作都基于 buf 這個字符數組。
關于 CharArrayReader 的其他方法以及 CharArrayWriter,這里不再贅述了,和上篇的字節數組流基本類似。
除此之外,這里還涉及一個 StringReader 和 StringWriter,其實本質上和字符數組流是一樣的,畢竟 String 的本質就是 char 數組。
緩沖數組流 BufferedReader/Writer
同樣的,BufferedReader/Writer 作為一種緩沖流,也是裝飾者流,用于提供緩沖功能。大體上類似于我們的字節緩沖流,這里我們簡單介紹下。
private Reader in;
private char cb[];
private static int defaultCharBufferSize = 8192;
public BufferedReader(Reader in, int sz){..}
public BufferedReader(Reader in) {
this(in, defaultCharBufferSize);
}cb 是一個字符數組,用于緩存從文件流中讀取出來的部分字符,你可以在構造器中初始化這個數組的長度,否則將使用默認值 8192 。
public int read() throws IOException {..}
public int read(char cbuf[], int off, int len){...}關于 read,它依賴成員屬性 in 的讀方法,而 in 作為一個 Reader 類型,內部往往又依賴的某個 InputStream 實例的讀方法。
所以說,幾乎所有的字符流都離不開某個字節流實例。
關于 BufferedWriter,這里也不再贅述了,大體上都是類似的,只不過一個是讀一個是寫而已,都圍繞著內部的字符數組進行。
標準打印輸出流
打印輸出流主要有兩種,PrintStream 和 PrintWriter,前者是字節流,后者是字符流。
這兩個流算是對各自類別下的流做了一個集成,內部封裝有豐富的方法,但實現也稍顯復雜,我們先來看這個 PrintStream 字節流:
主要的構造器有這么幾個:
public PrintStream(OutputStream out)
public PrintStream(OutputStream out, boolean autoFlush)
public PrintStream(OutputStream out, boolean autoFlush, String encoding)
public PrintStream(String fileName)
顯然,簡單的構造器會依賴復雜的構造器,這已經算是 jdk 設計「老套路」了。區別于其他字節流的一點是,PrintStream 提供了一個標志 autoFlush,用于指定是否自動刷新緩存。
接著就是 PrintStream 的寫方法:
public void write(int b)
public void write(byte buf[], int off, int len)
除此之外,PrintStream 還封裝了大量的 print 的方法,寫入不同類型的內容到文件中,例如:
public void print(boolean b)
public void print(char c)
public void print(int i)
public void print(long l)
public void print(float f)
等等
當然,這些方法并不會真正的將數值的二進制寫入文件,而只是將它們所對應的字符串寫入文件,例如:
print(123);
最終寫入文件的不是 123 所對應的二進制表述,而僅僅是 123 這個字符串,這就是打印流。
PrintStream 使用的緩沖字符流實現所有的打印操作,如果指明了自動刷新,則遇到換行符號「\n」會自動刷新緩沖區。
所以說,PrintStream 集成了字節流和字符流中所有的輸出方法,其中 write 方法是用于字節流操作,print 方法用于字符流操作,這一點需要明確。
至于 PrintWriter,它就是全字符流,完全針對字符進行操作,無論是 write 方法也好,print 方法也好,都是字符流操作。
總結一下,我們花了三篇文章講解了 Java 中的字節流和字符流操作,字節流基于字節完成磁盤和內存之間的數據傳輸,最典型的就是文件字符流,它的實現都是本地方法。有了基本的字節傳輸能力后,我們還能夠通過緩沖來提高效率。
而字符流的最基本實現就是,InputStreamReader 和 OutputStreamWriter,理論上它倆就已經能夠完成基本的字符流操作了,但也僅僅局限于最基本的操作,而構造它們的實例所必需的就是「一個字節流實例」+「一種編碼格式」。
所以,字符流和字節流的關系也就如上述的等式一樣,你寫一個字符到磁盤文件中所必需的步驟就是,按照指定編碼格式編碼該字符,然后使用字節流將編碼后的字符二進制寫入文件中,讀操作是相反的。
上述就是小編為大家分享的Java中怎么讀寫字符流文件了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





