溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
前言
自動伸縮是每個人都想要的,尤其是在微服務領域。讓我們看看如何在基于Spring Boot的應用程序中實現。
我們決定使用Kubernetes、Pivotal Cloud Foundry或HashiCorp's Nomad等工具的一個更重要的原因是為了讓系統可以自動伸縮。當然,這些工具也提供了許多其他有用的功能,在這里,我們只是用它們來實現系統的自動伸縮。乍一看,這似乎很困難,但是,如果我們使用Spring Boot來構建應用程序,并使用Jenkins來實現CI,那么就用不了太多工作。
今天,我將向您展示如何使用以下框架/工具實現這樣的解決方案:
它是如何工作的
每一個包含Spring Boot Actuator庫的Spring Boot應用程序都可以在/actuator/metrics端點下公開metric。許多有價值的metric都可以提供應用程序運行狀態的詳細信息。在討論自動伸縮時,其中一些metric可能特別重要:JVM、CPU metric、正在運行的線程數和HTTP請求數。有專門的Jenkins流水線通過按一定頻率輪詢/actuator/metrics 端點來獲取應用程序的指標。如果監控的任何metric【指標】低于或高于目標范圍,則它會啟動新實例或使用另一個Actuator端點/actuator/shutdown來關閉一些正在運行的實例。在此之前,我們需要知道當前有那些實踐在提供服務,只有這樣我們才能在需要的時候關閉空閑的實例或啟動新的新例。

在討論了系統架構之后,我們就可以繼續開發了。這個應用程序需要滿足以下要求:它必須有公開的可以優雅地關閉應用程序和用來獲取應用程序運行狀態metric【指標】的端點,它需要在啟動完成的同時就完成在Eureka的注冊,在關閉時取消注冊,最后,它還應該能夠從空閑端口池中隨機獲取一個可用的端口。感謝Spring Boot,只需要約五分鐘,我們可以輕松地實現所有這些機制。
動態端口分配
由于可以在一臺機器上運行多個應用程序實例,所以我們必須保證端口號不沖突。幸運的是,Spring Boot為應用程序提供了這樣的機制。我們只需要將application.yml中的server.port屬性設置為0。因為我們的應用程序會在Eureka中注冊,并且發送唯一的標識instanceId,默認情況下這個唯一標識是將字段spring.cloud.client.hostname, spring.application.name和server.port拼接而成的。
示例應用程序的當前配置如下所示。
可以看到,我通過將端口號替換為隨機生成的數字來改變了生成instanceId字段值的模板。
spring:
application:
name: example-service
server:
port: ${PORT:0}
eureka:
instance:
instanceId: ${spring.cloud.client.hostname}:${spring.application.name}:${random.int[1,999999]}
啟用Actuator的Metric
為了啟用Spring Boot Actuator,我們需要將下面的依賴添加到pom.xml。
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency>
我們還必須通過HTTP API將屬性management.endpoints.web.exposure.include設置為'*'來暴露Actuator的端點。現在,所有可用的指標名稱列表都可以在/actuator/metrics端點中找到,每個指標的詳細信息可以通過/actuator/metrics/{metricName}端點查看。
優雅地停止應用程序
除了查看metric端點外,Spring Boot Actuator還提供了停止應用程序的端點。然而,與其他端點不同的是,缺省情況下,此端點是不可用的。我們必須把management.endpoint.shutdown.enabled設為true。在那之后,我們就可以通過發送一個POST請求到/actuator/shutdown端點來停止應用程序了。
這種停止應用程序的方法保證了服務在停止之前從Eureka服務器注銷。
啟用Eureka自動發現
Eureka是最受歡迎的發現服務器,特別是使用Spring Cloud來構建微服務的架構。所以,如果你已經有了微服務,并且想要為他們提供自動伸縮機制,那么Eureka將是一個自然的選擇。它包含每個應用程序注冊實例的IP地址和端口號。為了啟用Eureka客戶端,您只需要將下面的依賴項添加到pom.xml中。
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency>
正如之前提到的,我們還必須保證通過客戶端應用程序發送到Eureka服務器的instanceId的唯一性。在“動態端口分配”中已經描述了它。
下一步需要創建一個包含內嵌Eureka服務器的應用程序。為了實現這個功能,首先我們需要在pom.xml中添加下面這個依賴:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-server</artifactId> </dependency>
這個main類需要添加@EnableEurekaServer注解。
@SpringBootApplication
@EnableEurekaServer
public class DiscoveryApp {
public static void main(String[] args) {
new SpringApplicationBuilder(DiscoveryApp.class).run(args);
}
}
默認情況下,客戶端應用程序嘗試使用8761端口連接Eureka服務器。我們只需要單獨的、獨立的Eureka節點,因此我們將禁用注冊,并嘗試從另一個Eureka服務器實例中獲取服務列表。
spring:
application:
name: discovery-service
server:
port: ${PORT:8761}
eureka:
instance:
hostname: localhost
client:
registerWithEureka: false
fetchRegistry: false
serviceUrl:
defaultZone: http://localhost:8761/eureka/
我們將使用Docker容器來測試上面的自動伸縮系統,因此需要使用Eureka服務器來準備和構建image。
Dockerfile和image的定義如下所示。
我們可以使用命令docker build -t piomin/discovery-server:2.0來進行構建。
FROM openjdk:8-jre-alpine ENV APP_FILE discovery-service-1.0-SNAPSHOT.jar ENV APP_HOME /usr/apps EXPOSE 8761 COPY target/$APP_FILE $APP_HOME/ WORKDIR $APP_HOME ENTRYPOINT ["sh", "-c"] CMD ["exec java -jar $APP_FILE"]
為彈性伸縮構建一個Jenkins流水線
第一步是準備Jenkins流水線,負責自動伸縮。我們將創建Jenkins聲明式流水線,它每分鐘運行一次。可以使用triggers指令配置執行周期,它定義了自動化觸發流水線的方法。我們的流水線將與Eureka服務器和每個使用Spring Boot Actuator的微服務中公開的metric端點進行通信。
測試服務的名稱是EXAMPLE-SERVICE,它和定義在application.yml文件spring.application.name的屬性值(大寫字母)相同。被監控的metric是運行在Tomcat容器中的HTTP listener線程數。這些線程負責處理客戶端的HTTP請求。
pipeline {
agent any
triggers {
cron('* * * * *')
}
environment {
SERVICE_NAME = "EXAMPLE-SERVICE"
METRICS_ENDPOINT = "/actuator/metrics/tomcat.threads.busy?tag=name:http-nio-auto-1"
SHUTDOWN_ENDPOINT = "/actuator/shutdown"
}
stages { ... }
}
使用Eureka整合Jenkins流水線
流水線的第一個階段負責獲取在discovery服務器上注冊的服務列表。Eureka發現了幾個HTTP API端點。其中一個是GET /eureka/apps/{serviceName},它返回一個給定服務名稱的所有活動實例列表。我們正在保存運行實例的數量和每個實例metric端點的URL。這些值將在流水線的下一個階段中被訪問。
下面的流水線片段可以用來獲取活動應用程序實例列表。stage名稱是Calculate。我們使用HTTP請求插件 來發起HTTP連接。
stage('Calculate') {
steps {
script {
def response = httpRequest "http://192.168.99.100:8761/eureka/apps/${env.SERVICE_NAME}"
def app = printXml(response.content)
def index = 0
env["INSTANCE_COUNT"] = app.instance.size()
app.instance.each {
if (it.status == 'UP') {
def address = "http://${it.ipAddr}:${it.port}"
env["INSTANCE_${index++}"] = address
}
}
}
}
}
@NonCPS
def printXml(String text) {
return new XmlSlurper(false, false).parseText(text)
}
下面是Eureka API對我們的微服務的示例響應。響應content-type是XML。

使用Spring Boot Actuator整合Jenkins流水線
Spring Boot Actuator使用metric來公開端點,這使得我們可以通過名稱和選擇性地使用標簽找到metric。在下面可見的流水線片段中,我試圖找到metric低于或高于閾值的實例。如果有這樣的實例,我們就停止循環,以便進入下一個階段,它執行向下或向上的伸縮。應用程序的IP地址是從帶有INSTANCE_前綴的流水線環境變量獲取的,這是在前一階段中被保存了下來的。
stage('Metrics') {
steps {
script {
def count = env.INSTANCE_COUNT
for(def i=0;i 100)
return "UP"
else if (value.toInteger() < 20)
return "DOWN"
else
return "NONE"
}
關閉應用程序實例
在流水線的最后一個階段,我們將關閉運行的實例,或者根據在前一階段保存的結果啟動新的實例。通過調用Spring Boot Actuator端點可以很容易執行停止操作。在接下來的流水線片段中,首先選擇了Eureka實例。然后我們將發送POST請求到那個ip地址。
如果需要擴展應用程序,我們將調用另一個流水線,它負責構建fat JAR并讓這個應用程序在機器上跑起來。
stage('Scaling') {
steps {
script {
if (env.SCALE_TYPE == 'DOWN') {
def ip = env["INSTANCE_0"] + env.SHUTDOWN_ENDPOINT
httpRequest url: ip, contentType: 'APPLICATION_JSON', httpMode: 'POST'
} else if (env.SCALE_TYPE == 'UP') {
build job: 'spring-boot-run-pipeline'
}
currentBuild.description = env.SCALE_TYPE
}
}
}
下面是spring-boot-run-pipeline流水線的完整定義,它負責啟動應用程序的新實例。它先從git倉庫中拉取源代碼,然后使用Maven命令編譯并構建二進制的jar文件,最后通過在java -jar命令中添加Eureka服務器地址來運行應用程序。
pipeline {
agent any
tools {
maven 'M3'
}
stages {
stage('Checkout') {
steps {
git url: 'https://github.com/piomin/sample-spring-boot-autoscaler.git', credentialsId: 'github-piomin', branch: 'master'
}
}
stage('Build') {
steps {
dir('example-service') {
sh 'mvn clean package'
}
}
}
stage('Run') {
steps {
dir('example-service') {
sh 'nohup java -jar -DEUREKA_URL=http://192.168.99.100:8761/eureka target/example-service-1.0-SNAPSHOT.jar 1>/dev/null 2>logs/runlog &'
}
}
}
}
}
擴展到多個機器
在前幾節中討論的算法只適用于在單個機器上啟動的微服務。如果希望將它擴展到更多的機器上,我們將不得不修改我們的架構,如下所示。每臺機器都有Jenkins代理運行并與Jenkins master通信。如果想在選定的機器上啟動一個微服務的新實例,我們就必須使用運行在該機器上的代理來運行流水線。此代理僅負責從源代碼構建應用程序并將其啟動到目標機器上。這個實例的關閉仍然是通過調用HTTP端點來完成。
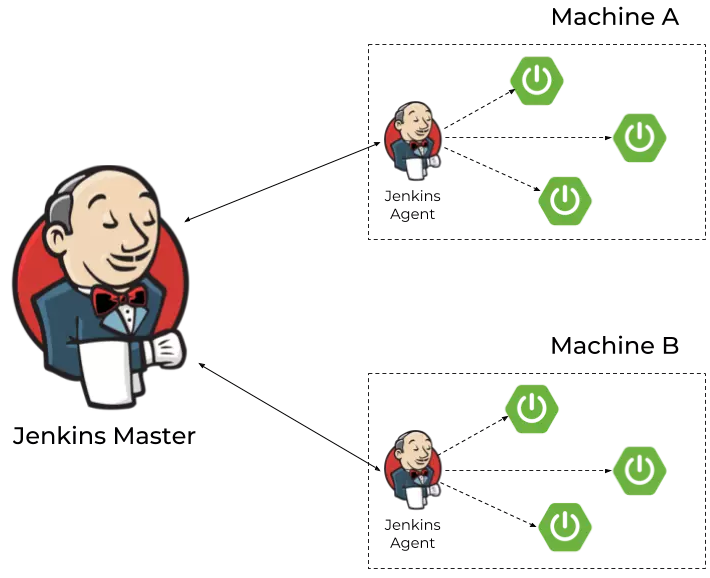
假設我們已經成功地在目標機器上啟動了一些代理,我們需要對流水線進行參數化,以便能夠動態地選擇代理(以及目標機器)。
當擴容應用程序時,我們必須將代理標簽傳遞給下游流水線。
build job:'spring-boot-run-pipeline', parameters:[string(name: 'agent', value:"slave-1")]
調用流水線具體由那個標簽下的代理運行,是由"${params.agent}"決定的。
pipeline {
agent {
label "${params.agent}"
}
stages { ... }
}
如果有一個以上的代理連接到主節點,我們就可以將它們的地址映射到標簽中。由于這一點,我們能夠將從Eureka服務器獲取的微服務實例的IP地址映射到與Jenkins代理的目標機器上。
pipeline {
agent any
triggers {
cron('* * * * *')
}
environment {
SERVICE_NAME = "EXAMPLE-SERVICE"
METRICS_ENDPOINT = "/actuator/metrics/tomcat.threads.busy?tag=name:http-nio-auto-1"
SHUTDOWN_ENDPOINT = "/actuator/shutdown"
AGENT_192.168.99.102 = "slave-1"
AGENT_192.168.99.103 = "slave-2"
}
stages { ... }
}
總結
在本文中,我演示了如何使用Spring Boot Actuato metric來自動伸縮Spring Boot應用程序。使用Spring Boot提供的特性以及Spring Cloud Netflix Eureka和Jenkins,您就可以實現系統的自動伸縮,而無需借助于任何其他第三方工具。本文也假設遠程服務器上也是使用Jenkins代理來啟動新的實例,但是您也可以使用Ansible這樣的工具來啟動。如果您決定從Jenkins運行Ansible腳本,那么將不需要在遠程機器上啟動Jenkins代理。
好了,以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作具有一定的參考學習價值,如果有疑問大家可以留言交流,謝謝大家對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





