溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一、分布式文件系統
分布式文件系統(Distributed File System)是指文件系統管理的物理存儲資源并不直接與本地節點相連,而是分布于計算網絡中的一個或者多個節點的計算機上。目前意義上的分布式文件系統大多都是由多個節點計算機構成,結構上是典型的客戶機/服務器模式。流行的模式是當客戶機需要存儲數據時,服務器指引其將數據分散的存儲到多個存儲節點上,以提供更快的速度,更大的容量及更好的冗余特性。
目前流行的分布式文件系統有許多,如MooseFS、OpenAFS、GoogleFS,具體實現原理我這里不再介紹。
二、GlusterFS概述
GlusterFS系統是一個可擴展的網絡文件系統,相比其他分布式文件系統,GlusterFS具有高擴展性、高可用性、高性能、可橫向擴展等特點,并且其沒有元數據服務器的設計,讓整個服務沒有單點故障的隱患。
術語:
Brick:GFS中的存儲單元,通過是一個受信存儲池中的服務器的一個導出目錄。可以通過主機名和目錄名來標識,如'SERVER:EXPORT'
Client:掛載了GFS卷的設備
Extended Attributes:xattr是一個文件系統的特性,其支持用戶或程序關聯文件/目錄和元數據。
FUSE:Filesystem Userspace是一個可加載的內核模塊,其支持非特權用戶創建自己的文件系統而不需要修改內核代碼。通過在用戶空間運行文件系統的代碼通過FUSE代碼與內核進行橋接。
Geo-Replication
GFID:GFS卷中的每個文件或目錄都有一個唯一的128位的數據相關聯,其用于模擬inode
Namespace:每個Gluster卷都導出單個ns作為POSIX的掛載點
Node:一個擁有若干brick的設備
RDMA:遠程直接內存訪問,支持不通過雙方的OS進行直接內存訪問。
Self-heal:用于后臺運行檢測復本卷中文件和目錄的不一致性并解決這些不一致。
Split-brain:腦裂
Translator:
Volfile:glusterfs進程的配置文件,通常位于/var/lib/glusterd/vols/volname
Volume:一組bricks的邏輯集合
1、無元數據設計
元數據是用來描述一個文件或給定區塊在分布式文件系統中所在的位置,簡而言之就是某個文件或某個區塊存儲的位置。傳統分布式文件系統大都會設置元數據服務器或者功能相近的管理服務器,主要作用就是用來管理文件與數據區塊之間的存儲位置關系。相較其他分布式文件系統而言,GlusterFS并沒有集中或者分布式的元數據的概念,取而代之的是彈性哈希算法。集群中的任何服務器和客戶端都可以利用哈希算法、路徑及文件名進行計算,就可以對數據進行定位,并執行讀寫訪問操作。
這種設計帶來的好處是極大的提高了擴展性,同時也提高了系統的性能和可靠性;另一顯著的特點是如果給定確定的文件名,查找文件位置會非常快。但是如果要列出文件或者目錄,性能會大幅下降,因為列出文件或者目錄時,需要查詢所在節點并對各節點中的信息進行聚合。此時有元數據服務的分布式文件系統的查詢效率反而會提高許多。
2、服務器間的部署
在之前的版本中服務器間的關系是對等的,也就是說每個節點服務器都掌握了集群的配置信息,這樣做的好處是每個節點度擁有節點的配置信息,高度自治,所有信息都可以在本地查詢。每個節點的信息更新都會向其他節點通告,保證節點間信息的一致性。但如果集群規模較大,節點眾多時,信息同步的效率就會下降,節點信息的非一致性概率就會大大提高。因此GlusterFS未來的版本有向集中式管理變化的趨勢。
3、客戶端訪問流程
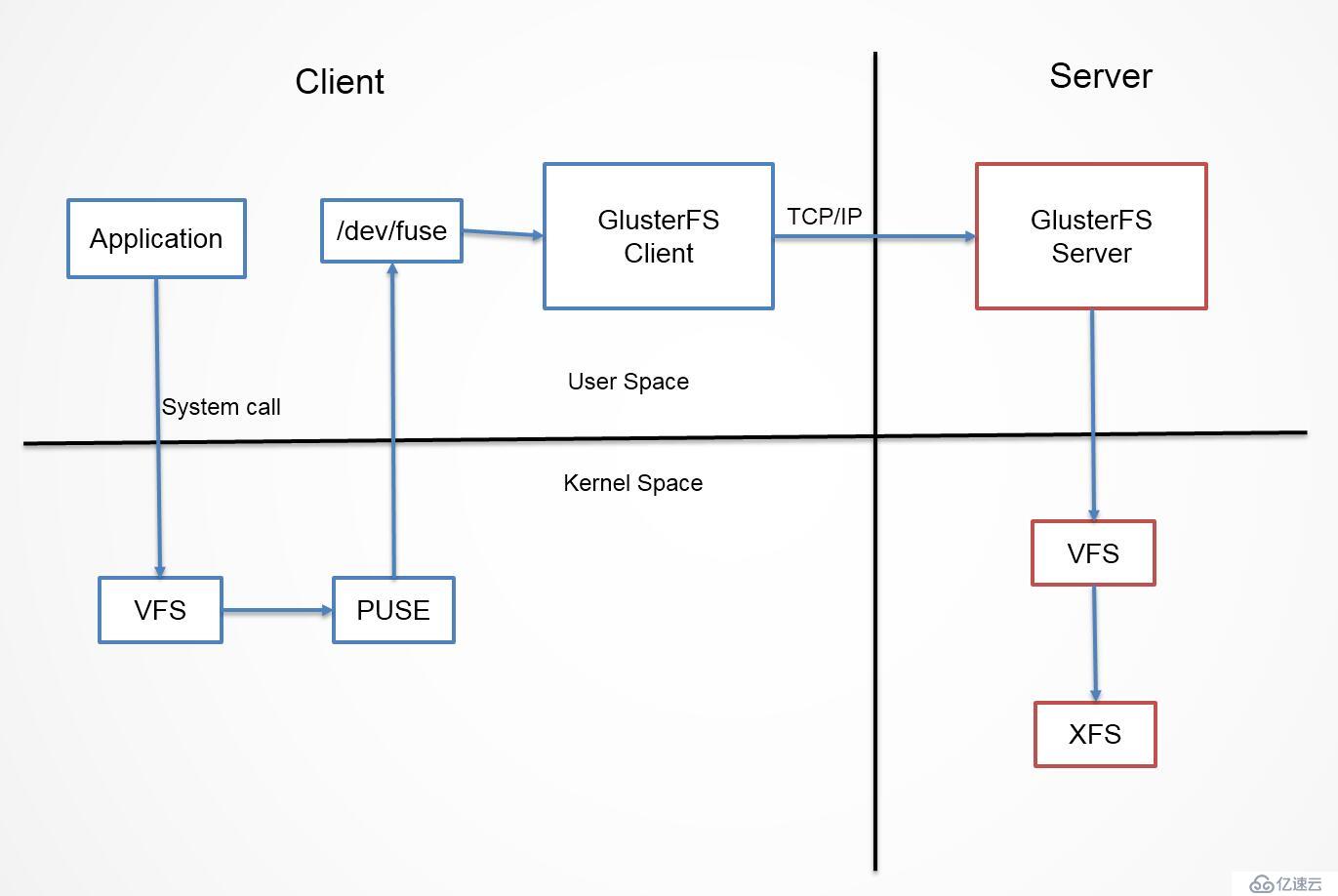
當客戶端訪問GlusterFS存儲時,首先程序通過訪問掛載點的形式讀寫數據,對于用戶和程序而言,集群文件系統是透明的,用戶和程序根本感覺不到文件系統是本地還是在遠程服務器上。讀寫操作將會被交給VFS(Virtual File System)來處理,VFS會將請求交給FUSE內核模塊,而FUSE又會通過設備/dev/fuse將數據交給GlusterFS Client。最后經過GlusterFS Client的計算,并最終經過網絡將請求或數據發送到GlusterFS Server上。
三、GlusterFS集群的模式
GlusterFS 集群的模式只數據在集群中的存放結構,類似于磁盤陣列中的級別。
1、分布式卷(Distributed Volume)
又稱哈希卷,近似于RAID0,文件沒有分片,文件根據hash算法寫入各個節點的硬盤上,優點是容量大,缺點是沒冗余。
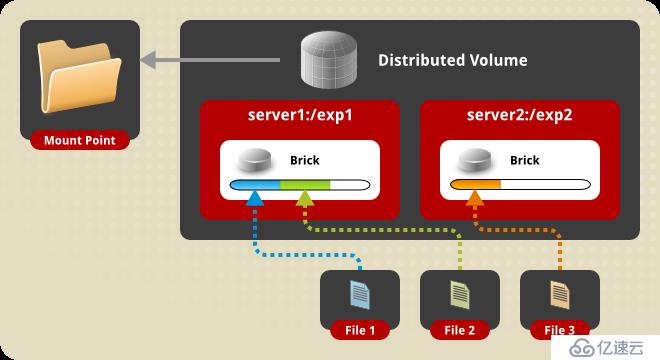
創建卷指令如下:
gluster volume create test-volume server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4
2、復制卷(Replicated Volume)
相當于raid1,復制的份數,決定集群的大小,通常與分布式卷或者條帶卷組合使用,解決前兩種存儲卷的冗余缺陷。缺點是磁盤利用率低。
復本卷在創建時可指定復本的數量,通常為2或者3,復本在存儲時會在卷的不同brick上,因此有幾個復本就必須提供至少多個brick,當其中一臺服務器失效后,可以從另一臺服務器讀取數據,因此復制GlusterFS卷提高了數據可靠性的同事,還提供了數據冗余的功能。
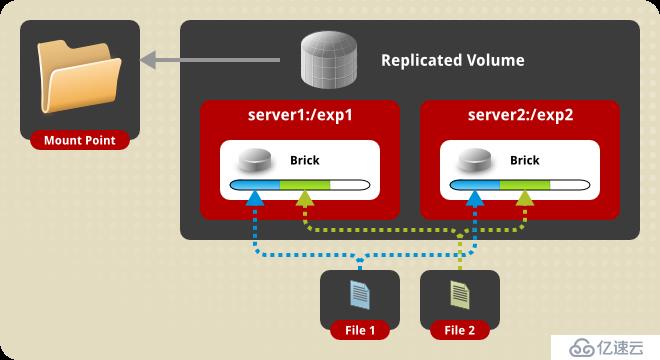
創建卷指令如下:
gluster volume create test-volume replica 2 transport tcp server1:/exp1 server2:/exp2
3、分布式復制卷(Distributed Replicated Volume)
分布式復制GlusterFS卷結合了分布式和復制Gluster卷的特點,看起來類似RAID10,但其實不同,RAID10其實質是條帶化,但分布式復制GlusterFS卷則沒有。
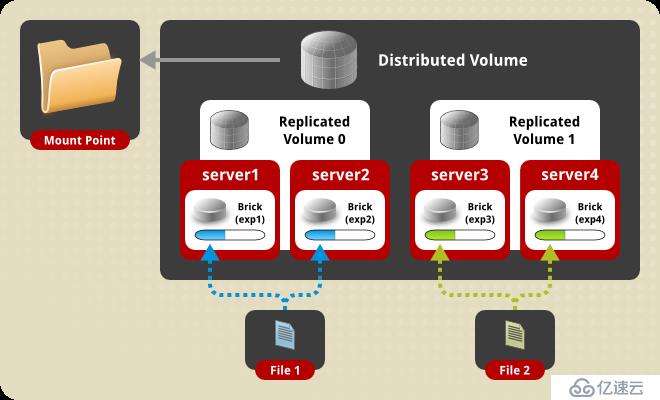
創建卷指令如下:
gluster volume create test-volume replica 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4
4、條帶卷(Striped Volume)
相當于raid0,文件是分片均勻寫在各個節點的硬盤上的,優點是分布式讀寫,性能整體較好。缺點是沒冗余,分片隨機讀寫可能會導致硬盤IOPS飽和。
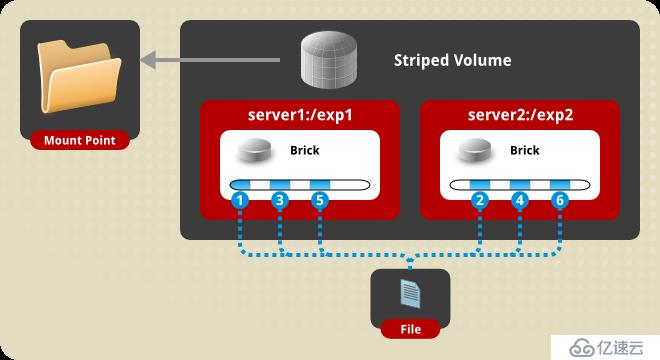
創建卷指令如下:
gluster volume create test-volume stripe 2 transport tcp server1:/exp1 server2:/exp2
5、分布式條帶卷(Distributed Striped Volume)
當單個文件的體型十分巨大,客戶端數量更多時,條帶卷已經無法滿足需求,此時將分布式與條帶化結合起來是一個比較好的選擇。其性能與服務器數量有關。

創建卷指令如下:
gluster volume create test-volume stripe 4 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 server5:/exp5 server6:/exp6 server7:/exp7 server8:/exp8
參考文檔:http://gluster.readthedocs.io/en/latest/Quick-Start-Guide/Architecture/
四、GlusterFS 的安裝與應用,請點擊查看
http://wzlinux.blog.51cto.com/8021085/1949619

免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





