溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關怎樣搭建Hadoop2.8.1完全分布式環境的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
實驗過程
1、基礎集群的搭建
目的:獲得一個可以互相通信的三節點集群
下載并安裝VMware WorkStation Pro(支持快照,方便對集群進行保存)下載地址,產品激活序列號網上自行查找。
下載CentOS7鏡像,下載地址。
使用VMware安裝master節點(稍后其他兩個節點可以通過復制master節點的虛擬機文件創建)。
三個節點存儲均為30G默認安裝,master節點內存大小為2GB,雙核,slave節點內存大小1GB,單核
2、集群網絡配置
目的:為了使得集群既能互相之間進行通信,又能夠進行外網通信,需要為節點添加兩張網卡(可以在虛擬機啟動的時候另外添加一張網卡,即網絡適配器,也可以在節點創建之后,在VMware設置中添加)。
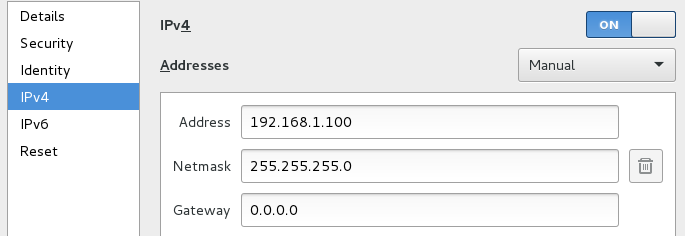
兩張網卡上網方式均采用橋接模式,外網IP設置為自動獲取(通過此網卡進行外網訪問,配置應該按照你當前主機的上網方式進行合理配置,如果不與主機通信的話可以采用NAT上網方式,這樣選取默認配置就行),內網IP設置為靜態IP。
本文中的集群網絡環境配置如下:
master內網IP:192.168.1.100
slave1內網IP:192.168.1.101
slave2內網IP:192.168.1.102
設置完后,可以通過ping進行網絡測試
注意事項:通過虛擬機文件復制,在VMware改名快速創建slave1和slave2后,可能會產生網卡MAC地址重復的問題,需要在VMware網卡設置中重新生成MAC,在虛擬機復制后需要更改內網網卡的IP。
每次虛擬機重啟后,網卡可能沒有自動啟動,需要手動重新連接。
3、集群SSH免密登陸設置
目的:創建一個可以ssh免密登陸的集群
3.1 創建hadoop用戶
為三個節點分別創建相同的用戶hadoop,并在以后的操作均在此用戶下操作,操作如下:
$su -
#useradd -m hadoop
#passwd hadoop
為hadoop添加sudo權限
#visudo
在該行root ALL=(ALL) ALL下添加hadoop ALL=(ALL) ALL保存后退出,并切換回hadoop用戶
#su hadoop
注意事項:三個節點的用戶名必須相同,不然以后會對后面ssh及hadoop集群搭建產生巨大影響
3.2 hosts文件設置
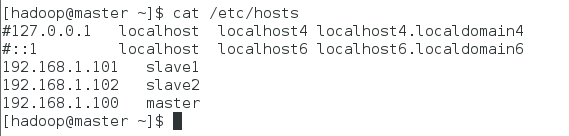
為了不直接使用IP,可以通過設置hosts文件達到ssh slave1這樣的的效果(三個節點設置相同)
$sudo vim /etc/hosts
在文件尾部添加如下行,保存后退出:
192.168.1.100 master
192.168.1.101 slave1
192.168.1.102 slave2
注意事項:不要在127.0.0.1后面添加主機名,如果加了master,會造成后面hadoop的一個很坑的問題,在slave節點應該解析出masterIP的時候解析出127.0.0.1,造成hadoop搭建完全正確,但是系統顯示可用節點一直為0。
3.3 hostname修改
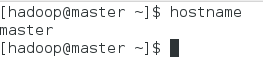
centos7默認的hostname是localhost,為了方便將每個節點hostname分別修改為master、slave1、slave2(以下以master節點為例)。
$sudo hostnamectl set-hostname master
重啟terminal,然后查看:$hostname
3.3 ssh設置
設置master節點和兩個slave節點之間的雙向ssh免密通信,下面以master節點ssh免密登陸slave節點設置為例,進行ssh設置介紹(以下操作均在master機器上操作):
首先生成master的rsa密鑰:$ssh-keygen -t rsa
設置全部采用默認值進行回車
將生成的rsa追加寫入授權文件:$cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
給授權文件權限:$chmod 600 ~/.ssh/authorized_keys
進行本機ssh測試:$ssh maste r正常免密登陸后所有的ssh第一次都需要密碼,此后都不需要密碼
將master上的authorized_keys傳到slave1
sudo scp ~/.ssh/id_rsa.pubhadoop@slave1:~/
登陸到slave1操作:$ssh slave1輸入密碼登陸
$cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
修改authorized_keys權限:$chmod 600 ~/.ssh/authorized_keys
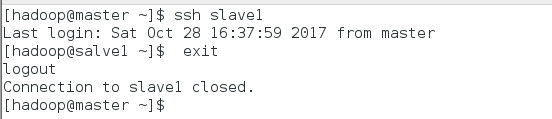
退出slave1:$exit
進行免密ssh登陸測試:$ssh slave1
4、java安裝
目的:hadoop是基于Java的,所以要安裝配置Java環境(三個節點均需要操作,以下以master節點為例)
下載并安裝:$sudo yum install java-1.8.0-openjdkjava-1.8.0-openjdk-devel
驗證是否安裝完成:$java -version
配置環境變量,修改~/.bashrc文件,添加行: export JAVA_HOME=/usr/lib/jvm/java-1.8.0
使環境變量生效:$source ~/.bashrc

5、Hadoop安裝配置
目的:獲得正確配置的完全分布式Hadoop集群(以下操作均在master主機下操作)
安裝前三臺節點都需要需要關閉防火墻和selinux
$sudo systemctl stop firewalld.service $sudo systemctl disable firewalld.service $sudo vim /usr/sbin/sestatus
將SELinux status參數設定為關閉狀態
SELinux status: disabled
5.1 Hadoop安裝
首先在master節點進行hadoop安裝配置,之后使用scp傳到slave1和slave2。
下載Hadoop二進制源碼至master,下載地址,并將其解壓在~/ 主目錄下
$tar -zxvf ~/hadoop-2.8.1.tar.gz -C ~/
$mv~/hadoop-2.8.1/* ~/hadoop/
注意事項:hadoop有32位和64位之分,官網默認二進制安裝文件是32位的,但是本文操作系統是64位,會在后面hadoop集群使用中產生一個warning但是不影響正常操作。
5.2 Hadoop的master節點配置
配置hadoop的配置文件core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml slaves(都在~/hadoop/etc/hadoop文件夾下)
$cd ~/hadoop/etc/hadoop
$vimcore-site.xml其他文件相同,以下為配置文件內容:
1.core-site.xml
<configuration> <property> <name>fs.default.name</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop/hadoop/tmp</value> </property> </configuration>
2.hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/hadoop/tmp/dfs/data</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:9001</value> </property> </configuration>
3.mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
4.yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration>
5.slaves
slave1
slave2
5.3 Hadoop的其他節點配置
此步驟的所有操作仍然是在master節點上操作,以master節點在slave1節點上配置為例
復制hadoop文件至slave1:$scp -r ~/hadoop hadoop@slave1:~/
5.4 Hadoop環境變量配置
配置環境變量,修改~/.bashrc文件,添加行(每個節點都需要此步操作,以master節點為例):
#hadoop environment vars export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
使環境變量生效:$source ~/.bashrc

6、Hadoop啟動
格式化namenode:$hadoop namenode -format
啟動hadoop:$start-all.sh
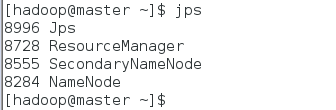
master節點查看啟動情況:$jps
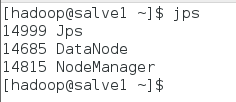
slave1節點查看啟動情況:$jps
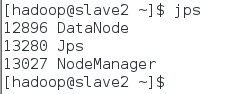
slave2節點查看啟動情況:$jps
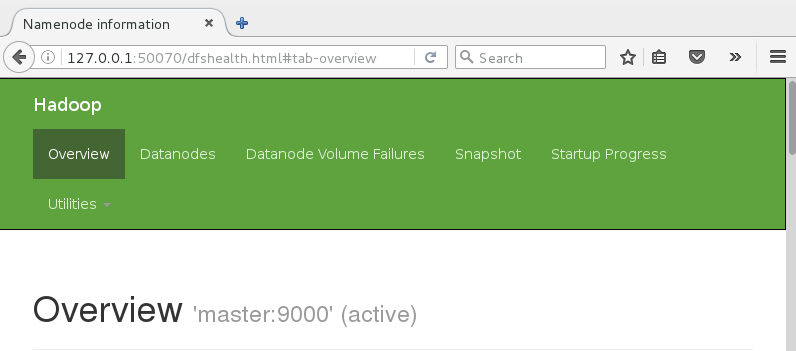
Web瀏覽器輸入127.0.0.1:50070,查看管理界面

7、Hadoop集群測試
目的:驗證當前hadoop集群正確安裝配置
本次測試用例為利用MapReduce實現wordcount程序
生成文件testWordCount:$echo "My name is Xie PengCheng. This is a example program called WordCount, run by Xie PengCheng " >>testWordCount
創建hadoop文件夾wordCountInput:$hadoop fs -mkdir /wordCountInput
將文件testWordCount上傳至wordCountInput文件夾:$hadoop fs -puttestWordCount/wordCountInput
執行wordcount程序,并將結果放入wordCountOutput文件夾:$hadoop jar ~/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.1.jar wordcount /wordCountInput /wordCountOutput
注意事項:/wordCountOutput文件夾必須是沒有創建過的文件夾
查看生成文件夾下的文件:$hadoop fs -ls /wordCountOutput

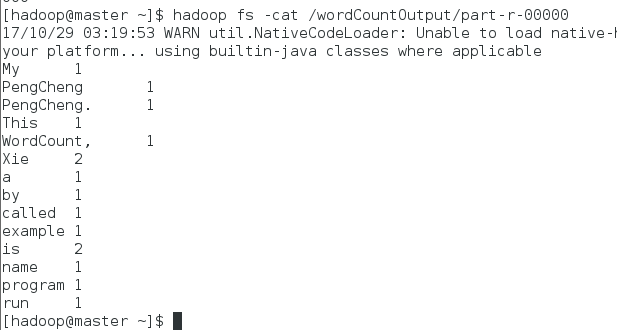
在output/part-r-00000可以看到程序執行結果:$hadoop fs -cat /wordCountOutpart-r-00000
感謝各位的閱讀!關于“怎樣搭建Hadoop2.8.1完全分布式環境”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





