溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關java中的Clojure怎樣抽象并發性和共享狀態,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
前言
在所有 Java 下一代語言中,Clojure 擁有最激進的并發性機制和功能。Groovy 和 Scala 都為并發性提供了改善的抽象和語法糖的一種組合,而 Clojure 堅持了它始終在 JVM 上提供獨一無二的行為的強硬立場。在本期 Java 下一代 中,我將介紹 Clojure 中眾多并發性選項的一部分。首先是為 Clojure 中易變的引用提供支撐的基礎抽象:epochal 時間模型。
Epochal 事件模型
或許 Clojure 與其他語言最顯著的區別與易變的狀態和值 密切相關。Clojure 中的值 可以是任何用戶感興趣的數據:數字 42、映射結構 {:first-name "Neal :last-name "Ford"} 或某些更大型的數據結構,比如 Wikipedia。基本來講,Clojure 語言對待所有值就像其他語言對待數字一樣。數字 42 是一個值,您不能重新定義它。但可對該值應用一個函數,返回另一個值。例如,(inc 42) 返回值 43。
在 Java 和其他基于 C 的語言中,變量 同時持有身份和值,這是讓并發性在 Java 語言中如此難以實現的因素之一。語言設計人員在線程抽象之前創建了變量抽象,變量的設計沒有考慮為并發性增加的復雜性。因為 Java 中的變量假設只有單個線程,所以在多線程環境中,需要像同步塊這樣麻煩的機制來保護變量。Clojure 的設計人員 Rich Hickey 讓交織(complect) 這個古老的詞匯恢復了活力(交織這個詞被定義為 “纏繞或編織”),用于描述 Java 變量中的設計缺陷。
Clojure 將值 與引用 分開。在 Clojure 世界觀中,數據以一系列不變的值的形式存在,如圖 1 所示。
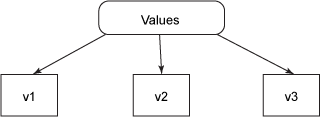
圖 1. epochal 時間模型中的值
圖 1 顯示,像 v1 這樣的獨立的值表示 42 或 Wikipedia 等數據,使用方框表示。與值獨立的是函數,它們獲取值作為參數并生成新值,如圖 2 所示。
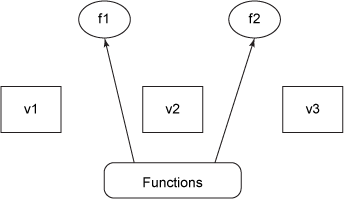
圖 2. epochal 時間模型中的函數
圖 2 將函數顯示為與值獨立的圓圈。函數調用會生成新值,使用值作為參數和結果。一連串的值保存在一個引用 中,它表示變量的身份。隨著時間的推移,此身份可能指向不同的值(由于函數應用),但身份從不更改,如圖 3 中的虛線所示。
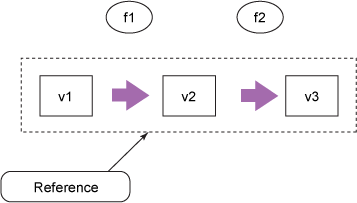
圖 3. epochal 時間模型中的引用
在圖 3 中,整幅圖表示一個引用隨時間的變化。虛線是一個引用,它持有其生存期內的一連串的值。可在某個時刻向引用分配一個新的不變值;引用指向的目標可更改,而無需更改該引用。
在引用的生存期中,一個或多個觀察者(其他程序、用戶界面、任何對該引用持有的值感興趣的對象)將解除引用它,查看它的值(或許還執行某種操作),如圖 4 所示。
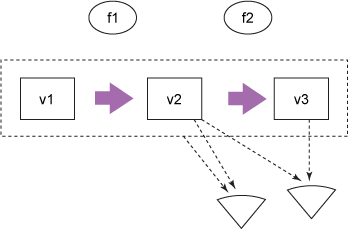
圖 4. 解除引用
在圖 4 中,觀察者(有兩種楔形表示)可持有引用本身(由來自虛線引用的箭頭表示),或者可解除引用它,檢索它的值(由來自該值的箭頭表示)。例如,您可能有一個函數,它以一個傳遞給您的數據庫連接作為參數,您進而將該參數傳遞給一個更低級的持久性函數。在此情況下,您持有該引用,但從不需要它的值;持久性函數可能會解除引用它,以獲取它的值來連接到一個數據庫。
請注意,圖 4 中的觀察者不會進行協調 — 它們完全不依賴彼此。此結構使得 Clojure 運行時能夠在整個語言中保證了一些有用的屬性,比如決不允許讀取程序阻塞,這使得讀取操作變得非常高效。如果您希望更改一個引用(也就是說,將它指向一個不同的值),可使用 Clojure 的一個 API 來執行更新,這會采用 epochal 時間模型。
epochal 時間模型為整個 Clojure 中的引用更新提供了支持。因為運行時控制所有更新,所以它可防御線程沖突,開發人員在不太復雜的語言中必須爭用線程。
Clojure 擁有廣泛的方式來更新引用,具體依賴于您想要何種特征。接下來,我將討論兩種方式:簡單的原子 和復雜的軟件事務內存。
原子
Clojure 中的原子 是對數據一個原子部分的引用,無論該部分有多大。您創建一個 atom 并初始化它,然后應用一個突變函數。這里,我為一個原子創建了一個稱為 counter 的引用,將它初始化為 0。如果我希望將引用更新到一個新值,我可使用 (swap!) 這樣的函數,它原子化地為該引用換入一個新值:
(def counter (atom 0)) (swap! counter + 10)
根據 Clojure 中的慣例,突變函數的名稱以一個感嘆號結尾。(swap!) 函數接受該引用、要應用的函數(在本例中為 + 運算符)和任何其他參數。
Clojure 原子持有任何大小的數據,而不只是原始值。例如,我可圍繞一個 person 映射創建一個原子引用,并使用 map 函數更新它。使用 (create-person) 函數(未顯示),我在一個原子中創建一個 person 記錄,然后使用 (swap!) 和 (assoc ) 更新該引用,這會更新一個映射關聯:
(def person (atom (create-person))) (swap! person assoc :name "John")
原子還會通過 (compare-and-set!) 函數,使用原子實現一個通用的樂觀鎖定模式:
(compare-and-set! a 0 42) => false (compare-and-set! a 1 7) = true
(compare-and-set!) 函數接受 3 個參數:原子引用、想要的現有值和新值。如果原子的值與想要的值不匹配,更新不會發生,函數會返回 false。
Clojure 有各種各樣的機制都遵循引用語義。例如,promise(是一種不同的引用)承諾在以后提供一個值。這里,我創建對一個名為 number-later 的 promise 的引用。此代碼不會生成任何值,就像它對最終會這么做的承諾一樣。調用 (deliver ) 函數時,一個值會綁定到 number-later:
(def number-later (promise)) (deliver number-later 42)
盡管此示例使用了 Clojure 中的 futures 庫,但引用語義與簡單的原子保持一致。
軟件事務內存
沒有其他任何 Clojure 特性獲得了比軟件事務內存 (STM) 更多的關注,這是 Clojure 以 Java 語言封裝垃圾收集的方式來封裝并發性的內部機制。換句話說,您可編寫高性能的多線程 Clojure 應用程序,而從不考慮同步塊、死鎖、線程庫等。
Clojure 封裝并發性的方式是,通過 STM 控制引用的所有突變。更新一個引用(惟一的易變抽象)時,必須在一個事務中執行,以使 Clojure 運行時能夠管理更新。考慮一個經典的銀行問題:向一個帳戶中存款,同時向另一個帳戶貸款。清單 1 顯示了一個簡單的 Clojure 解決方案。
清單 1. 銀行交易
(defn transfer [from to amount] (dosync (alter from - amount) (alter to + amount)))
在 清單 1 中,我定義了一個 (transfer ) 函數,它接受 3 個參數:from 和 to 帳戶 — 二者都是引用 — 以及金額。我從 from 帳戶中減去該金額,將它添加到 to 帳戶中,但此操作必須與 (dosync ) 事務一起發生。如果我在事務塊的外部嘗試一個 (alter ) 調用,更新會失敗并拋出一個 IllegalStateException:
(alter from - 1) =>> IllegalStateException No transaction running
在 清單 1 中,(alter ) 函數仍然遵守 epochal 時間模型,但使用 STM 來確保兩個操作都完成或都未完成。為此,STM — 非常像一個數據庫服務器 — 臨時重試阻塞的操作,所以您的更新函數在更新之外不應有任何副作用。例如,如果您的函數還寫入一個日志,由于不斷重試,您可能會看到多個日志條目。STM 還會隨未解決事務的時長增長而逐步提高它們的優先級,顯示數據庫引擎中的其他更常見的行為。
STM 的使用很簡單,但底層機制很復雜。從名稱可以看出,STM 是一個事務系統。STM 實現了 ACID 事務標準的 ACI 部分:所有更改都是原子性、一致 和隔離的。ACID 的耐久 部分在這里不適用,因為 STM 在內存中操作。很少看到將像 STM 這樣的高性能機制內置于一種語言的核心中;Haskell 是惟一認真實現了 STM 的另一種主流語言 — 不要奇怪,因為 Haskell(像 Clojure 一樣)非常喜歡不變性。(.NET 生態系統曾嘗試構建一個 STM 管理器,但最終放棄了,因為處理事務和不變性變得太復雜了。)
縮減程序(reducer)和數字分類
如果不討論 上一期 中的數字分類器問題的替代實現,并行性介紹都是不完整的。清單 2 顯示了一個沒有并行性的原子版本。
清單 2. Clojure 中的數字分類器
(defn classify [num] (let [facts (->> (range 1 (inc num)) (filter #(= 0 (rem num %)))) sum (reduce + facts) aliquot-sum (- sum num)] (cond (= aliquot-sum num) :perfect (> aliquot-sum num) :abundant (< aliquot-sum num) :deficient)))
清單 2 中的分類器版本濃縮為單個函數,它返回一個 Clojure 關鍵字(由一個前導冒號表示)。(let ) 塊使我能夠建立局部綁定。為了確定因數,我使用 thread-last 運算符來過濾數字范圍,讓代碼更有序。sum 和 aliquot-sum 的計算都很簡單;一個數字的真因數和 是它的因數之和減去它本身,這使我的比較代碼更簡單。該函數的最后一行是 (cond ) 語句,它針對計算的值來計算 aliquot-sum,返回合適的關鍵字枚舉。此代碼的一個有趣之處是,我以前的實現中的方法在這個版本中折疊為簡單的賦值。在計算足夠簡單和簡潔時,您通常需要創建的函數更少。
Clojure 包含一個稱為 縮減程序 的強大的并發性庫。(有關縮減程序庫的開發過程的解釋 — 包括為利用最新的 JVM 原生的 fork/join 工具而進行的優化 — 是一個吸引人的故事。)縮減程序庫提供了常見運算的就地替換,比如 map、filter 和 reduce,使這些預算能夠自動利用多個線程。例如,將標準的 (map ) 替換為 (r/map )(r/ 是縮減程序的命名空間),會導致您的映射操作自動被運行時并行化。
清單 3 給出了一個利用了縮減程序的數字分類器版本。
清單 3. 使用了縮減程序庫的分類器
(ns pperfect.core (:require [clojure.core.reducers :as r])) (defn classify-with-reducer [num] (let [facts (->> (range 1 (inc num)) (r/filter #(= 0 (rem num %)))) sum (r/reduce + facts) aliquot-sum (- sum num)] (cond (= aliquot-sum num) :perfect (> aliquot-sum num) :abundant (< aliquot-sum num) :deficient)))
必須仔細觀察,才能找出 清單 2 和 清單 3 之間的區別。惟一的區別是引入了縮減程序命名空間和別名,向 filter 和 reduce 都添加了 r/。借助這些細微的更改,我的過濾和縮減操作現在可自動使用多個線程。
關于“java中的Clojure怎樣抽象并發性和共享狀態”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





