溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
1,什么是Prometheus?
Prometheus是最初在SoundCloud上構建的開源系統監視和警報工具包,自2012年成立以來,許多公司和組織都采用了Prometheus,該項目擁有非常活躍的開發人員和用戶社區。現在,它是一個獨立的開源項目,并且獨立與任何公司維護。為了強調這一點并闡明項目的治理結構,Prometheus在2016年加入了 Cloud Native Computing Foundation(云原生計算基金會(CNCF)),這是繼kubernetes之后的第二個托官項目。
2,Prometheus的優勢
Prometheus 的主要優勢有:
- 由指標名稱和鍵/值識別時間序列數據組成的多維數據模型。
- 強大的查詢語言 (PromQL)
- 不依賴分布式存儲;單個服務節點具有自治能力。
- 通過基于HTTP的拉取方式采集時間序列數據。
- 可以通過中間網關來推送時間序列數據。
- 可以通過靜態配置文件或服務發現來獲取監控目標。
- 支持多種類型的圖標和儀表盤,比如Grafana等。
3,Prometheus的核心組件
Prometheus生態系統有多個組件組成,其中有許多組件是可選的:
- Prometheus Server:用于收集指標和存儲時間序列數據,并提供查詢接口。
- client Library:客戶端庫(例如Go,python,java等),為需要監控的服務產生相應的/metrics(服務指標度量)并暴露給Prometheus server。
- push gateway:推送網關,主要用于臨時性的jobs。由于這類jobs存在時間較短,可能在Prometheus來pull之前就消失了,對此jobs定時將指標push到pushgateway,再由Prometheus server從pushgateway上pull。
- Exporter:用于暴露已有的第三方服務的 metrics 給Prometheus。
- alertmanager:用來處理告警,從Prometheus server端接收警告后,會進行去除重復數據,分組,并路由到對收的接收方式,發出報警。最常見的接收方式:電子郵件。
4,Prometheus的架構
Prometheus 的整體架構以及生態系統組件如下圖所示: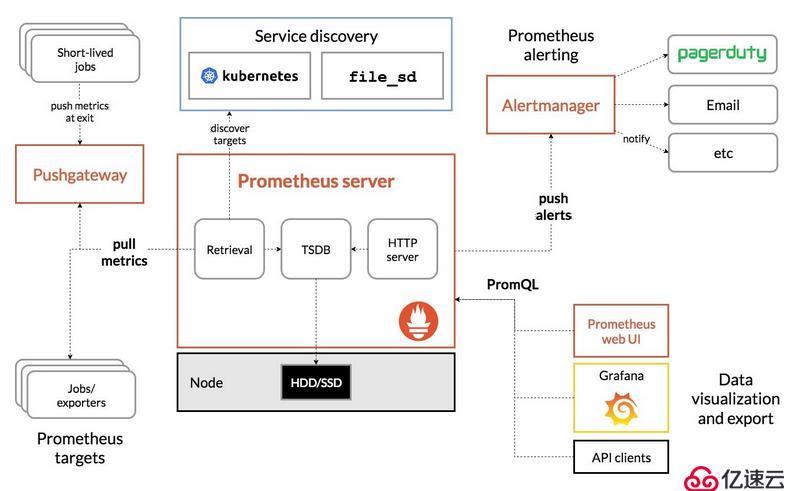
Prometheus server直接從監控目標中或者間接通過推送網關來拉取監控指標,它在本地存儲所有抓取到的樣本數據,并對此數據執行一系列規則,以匯總和記錄現有數據的新時間序列和生成告警。可以通過Grafana或者其他工具來實現監控數據的可視化。
5,Prometheus的優缺點
Prometheus對于采集純數字值的時間序列非常在行,所以它適合以物理機為中心的監控,也適合監控高度動態的面向服務的架構體。在微服務領域,它的多維數據采集以及查詢非常獨到且很有競爭力。
Prometheus最大的價值在于可靠性,用戶可以再任何時候看到整個被監控系統的統計信息,即使在系統有問題的是時候。但它不能做到100%的精確,比如如果你要按請求數據計費,那么Prometheus不太適合你,因為它收集的數據可能不夠詳細完整。這種情況下你最好使用其他系統來收集和分析數據以進行計費,并使用Prometheus來監控系統的其余部分。
部署環境:
| 節點名 | 主機ip | 操作系統 |
|---|---|---|
| master | 172.16.1.30 | Centos7 |
| node01 | 172.16.1.31 | Centos7 |
| node02 | 172.16.1.32 | Centos7 |
1,獲得Prometheus的git項目:
1)安裝git工具包:
[root@master ~]# yum install git -y2)獲取Prometheus的git項目:
[root@master prometheus]# git clone https://github.com/coreos/kube-prometheus.git

#執行git pull命令進行更新,確保克隆到本地的是最新的:
[root@master kube-prometheus]# git pull
Already up-to-date.2,導入部署Prometheus所需組件鏡像:
1)在集群中的所有node上進行上傳鏡像包(包括master)
2)分別在集群中的node上進行load操作:
#注意:確定在當前路徑下執行
[root@master images]# for i in `ls`; do docker load < $i; done
[root@node01 images]# for i in `ls`; do docker load < $i; done
[root@node02 images]# for i in `ls`; do docker load < $i; done以上鏡像都是我通過國內阿里云鏡像站下載好的(已修改tag),我已上傳至網盤,大家可以去進行下載:鏈接:https://pan.baidu.com/s/1c8pP3vAS9qHCQqc-XaYRXQ
提取碼:8zk2
注意:
考慮到以上組件的鏡像版本在git項目上會經常的更新,所以大家就得根據最新版本去下載相對應的鏡像;yaml文件中默認是從quay.io和gcr.io進行鏡像拉取(其他的國內可直接拉取),我們知道,國內訪問外網是被屏蔽的,我們無法直接將鏡像下載下來,所以可以分別通過 quay-mirror.qiniu.com 和 registry.aliyuncs.com鏡像站去拉取。
###例如:
拉取鏡像:quay.io/coreos/prometheus-operator:v0.36.0
可以改為:quay-mirror.qiniu.com/coreos/prometheus-operator:v0.36.0
拉取鏡像:gcr.io/google_containers/kube-proxy
可以改為:registry.aliyuncs.com/google_containers//kube-proxy
3,修改訪問模式為nodeport
1)修改grafana-service文件:
[root@master kube-prometheus]# cd manifests/
[root@master manifests]# vim grafana-service.yaml 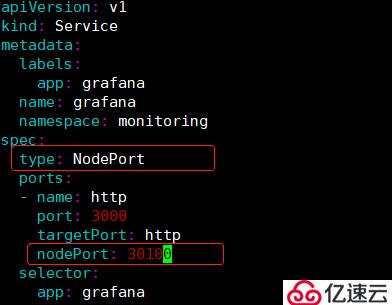
2)修改Prometheus-service文件:
[root@master manifests]# vim prometheus-service.yaml 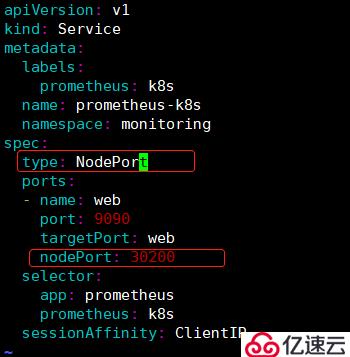
3)修改alertmanager-service文件: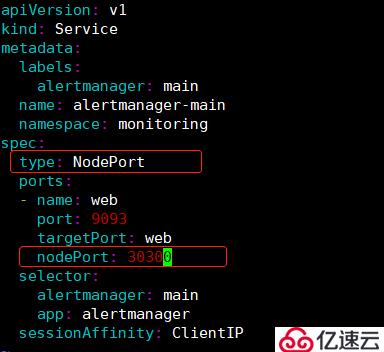
4,執行安裝操作
1)先安裝Prometheus所需要的資源(在manifests/setup目錄下的yaml文件):
[root@master manifests]# kubectl apply -f setup/2)安裝Prometheus(在manifests/路徑下的yaml文件):
[root@master manifests]# cd ..
[root@master kube-prometheus]# kubectl apply -f manifests/5,查看Prometheus資源(確保以下pod都達到所期望的狀態值)[root@master kube-prometheus]# kubectl get pod -n monitoring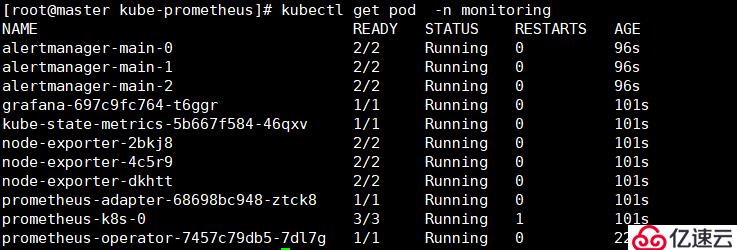
[root@master kube-prometheus]# kubectl get svc -n monitoring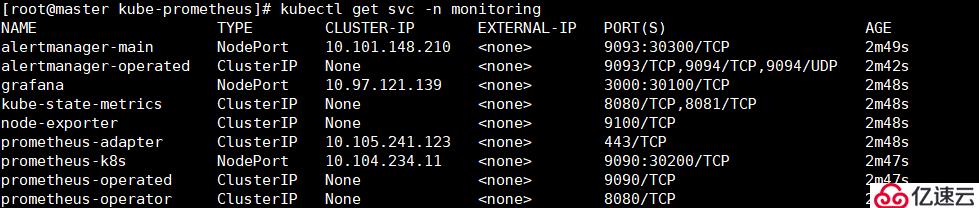
以上各組件說明:
- MerticServer: k8s集群資源使用情況的聚合器,收集數據給k8s集群內使用;如kubectl,hpa,scheduler等。
- PrometheusOperator:是一個系統監測和警報工具箱,用來存儲監控數據。
- NodeExPorter:用于各個node的關鍵度量指標狀態數據。
- kubeStateMetrics:收集k8s集群內資源對象數據,指定告警規則。
- Prometheus:采用pull方式收集apiserver,scheduler,control-manager,kubelet組件數據,通過http協議傳輸。
- Grafana:是可視化數據統計和監控平臺。
6,Prometheus監控頁面展示
1)訪問Prometheus web頁面:
訪問url:http://172.16.1.30:30200/ 
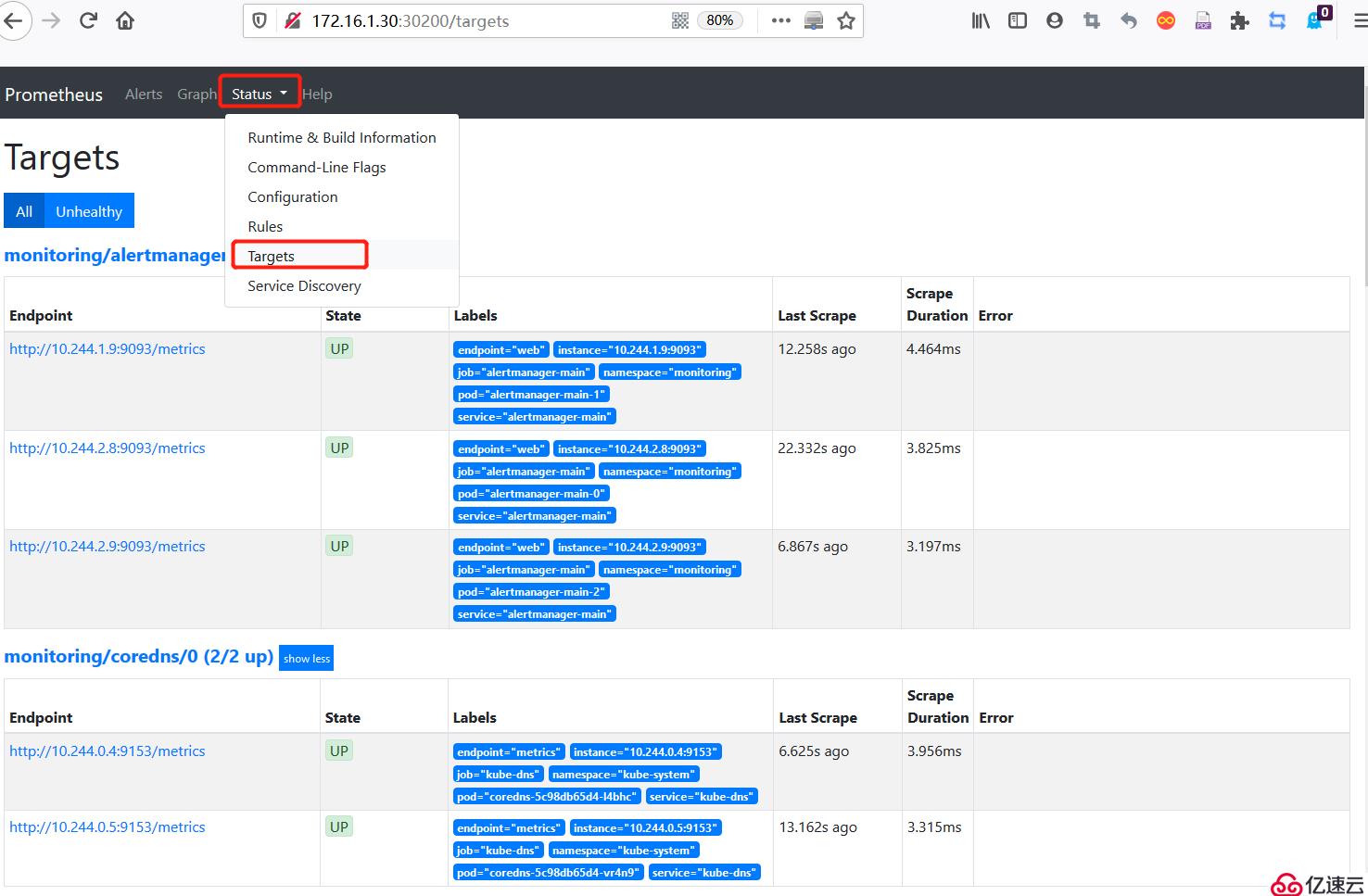
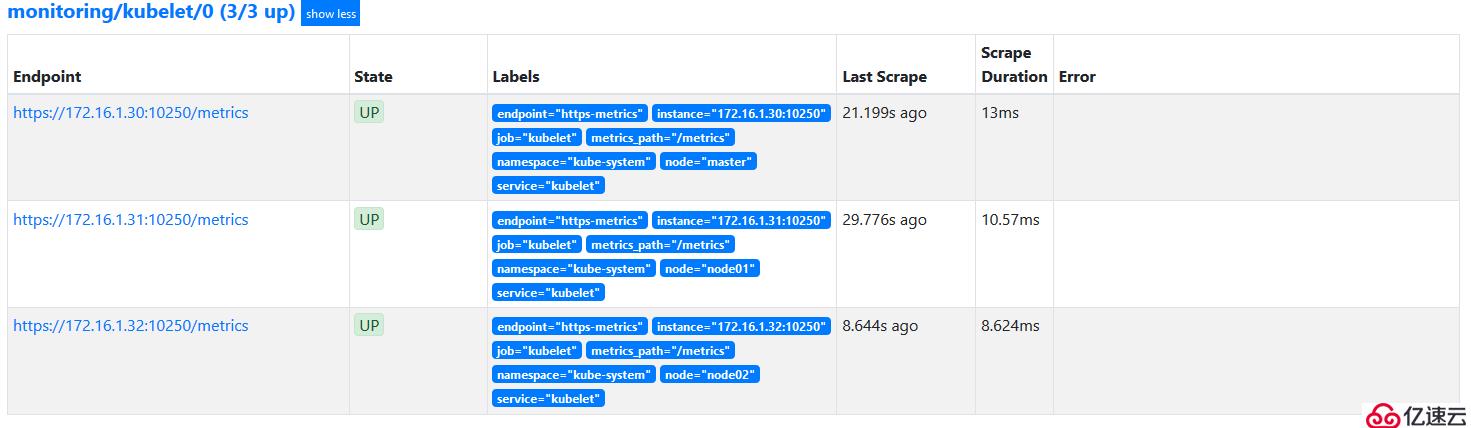
#部署成功后,會顯示集群節點各個組件的詳細信息,并且狀態為up。
2)訪問alertmanager web頁面:
訪問url: http://172.16.1.30:30300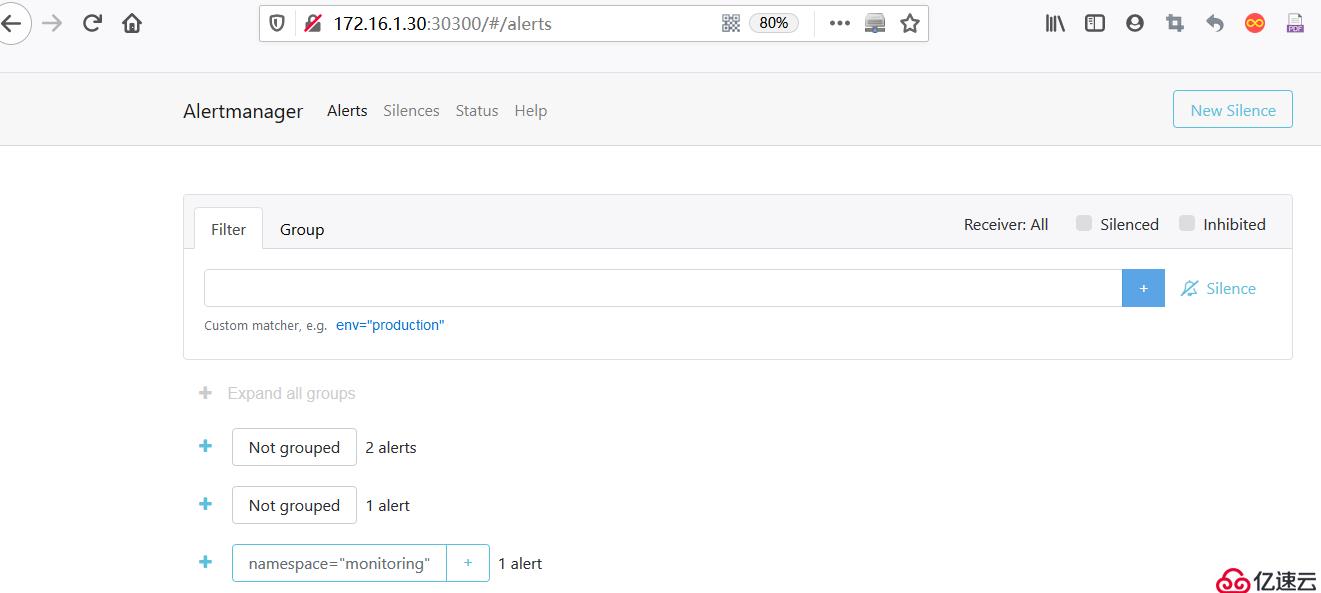
3)訪問Grafana 圖形化界面:
訪問url: http://172.16.1.30:30100 , 初始用戶名和密碼都為:admin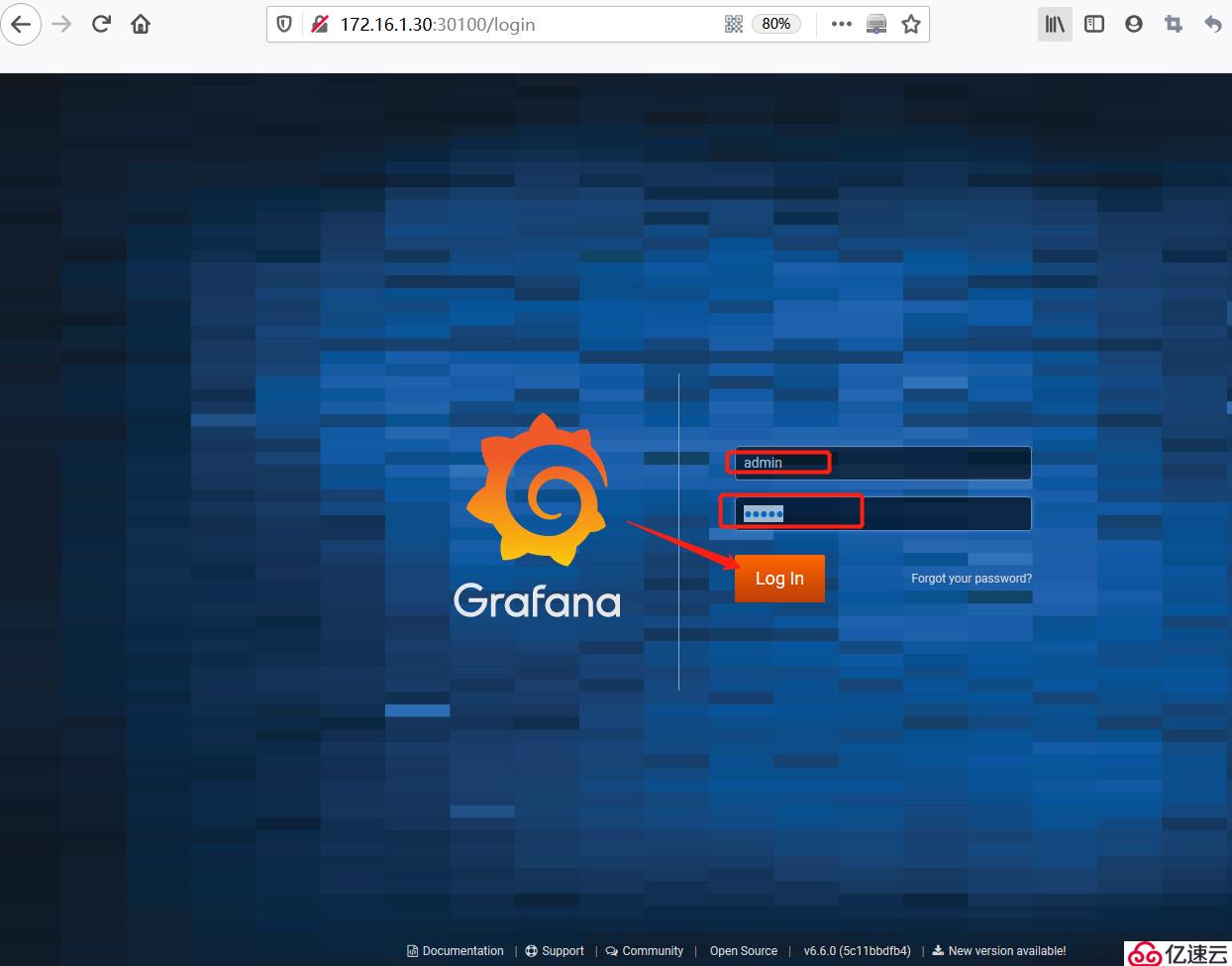
#修改用戶名和密碼后點擊登錄: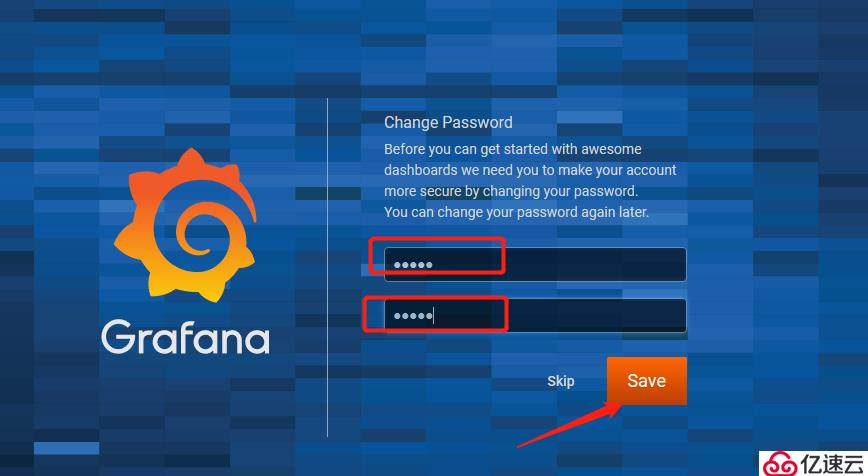
1,為grafana添加Prometheus數據源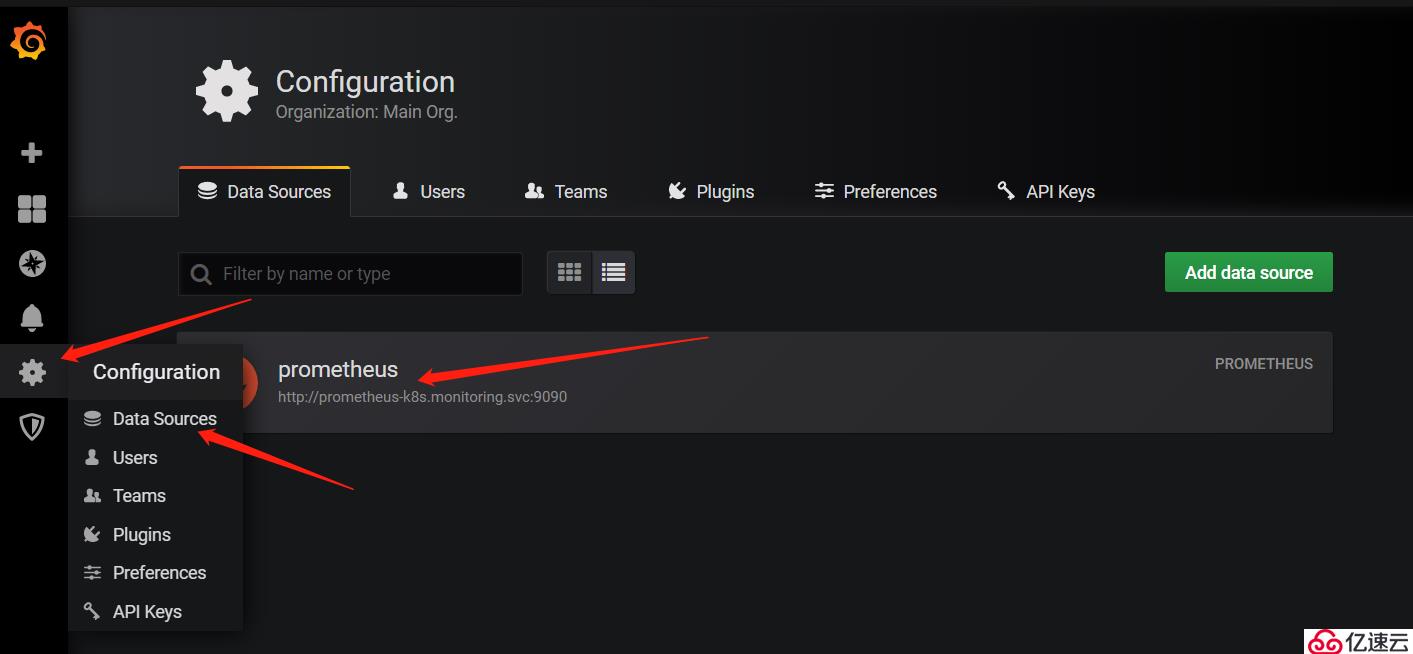
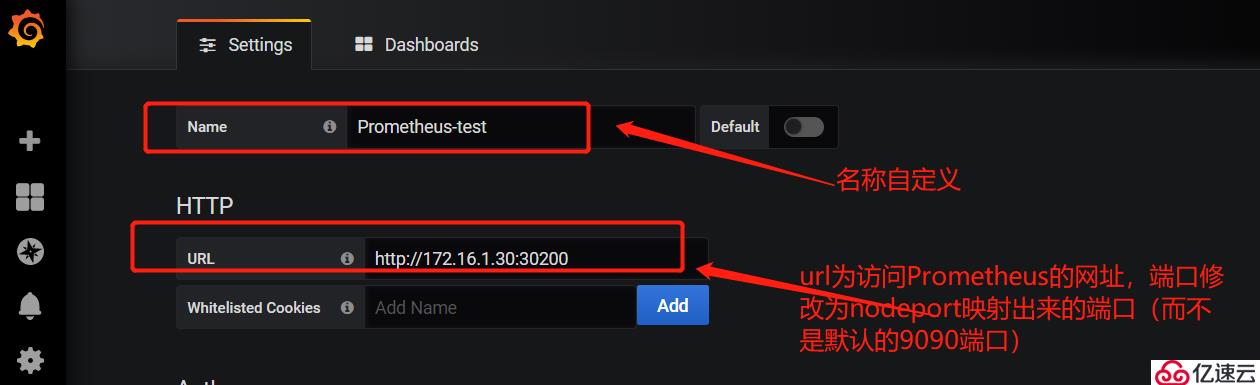
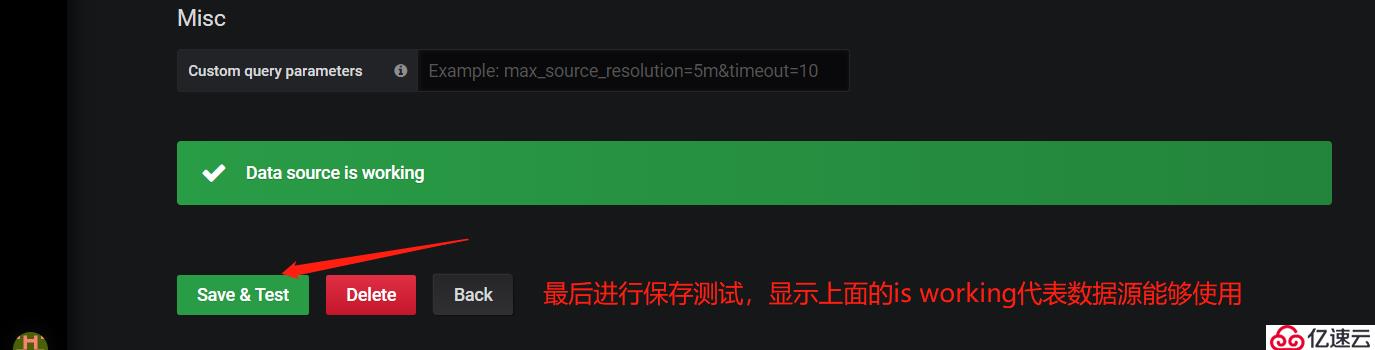
上圖所示,可以看到當部署完Prometheus后默認已經為我們添加了一個Prometheus數據源,大家也可以點擊右上角的"Add data source"選項自定義添加所需要的數據源。如下圖所示: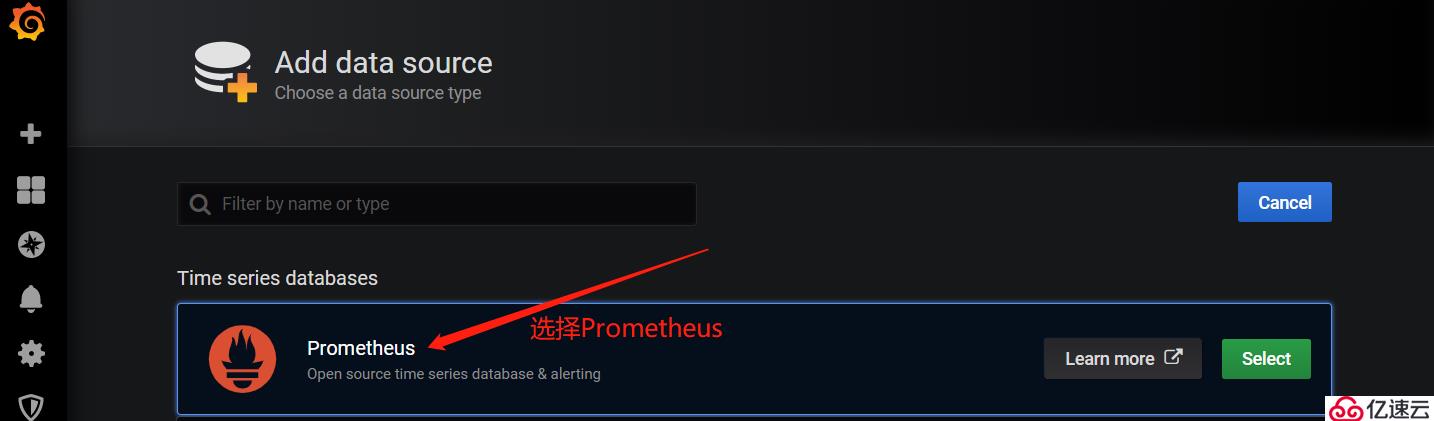
2,為grafana添加dashboard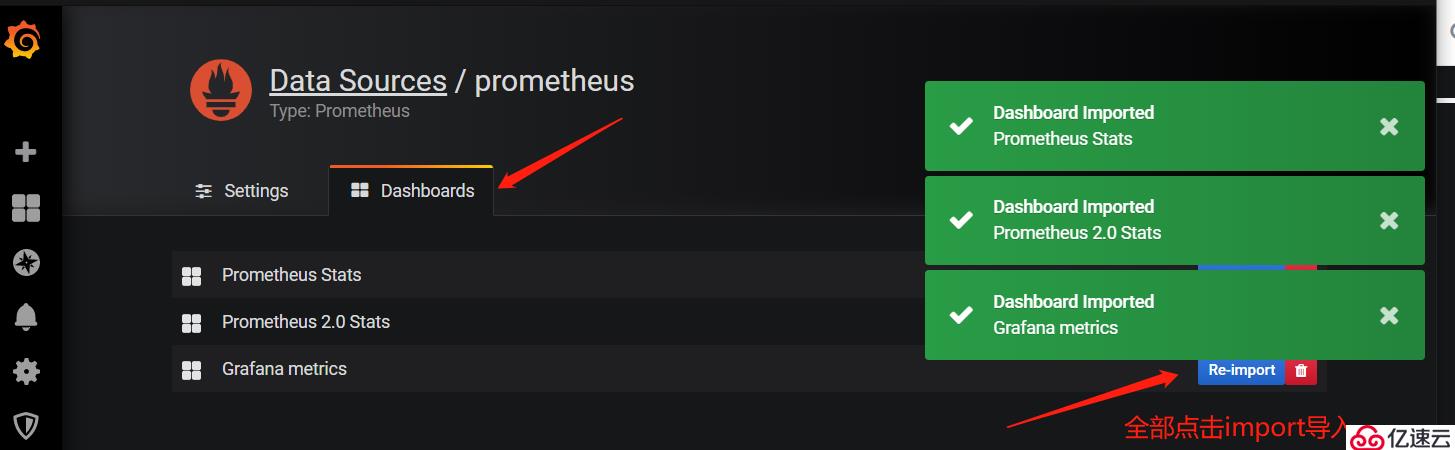
3,監控集群資源
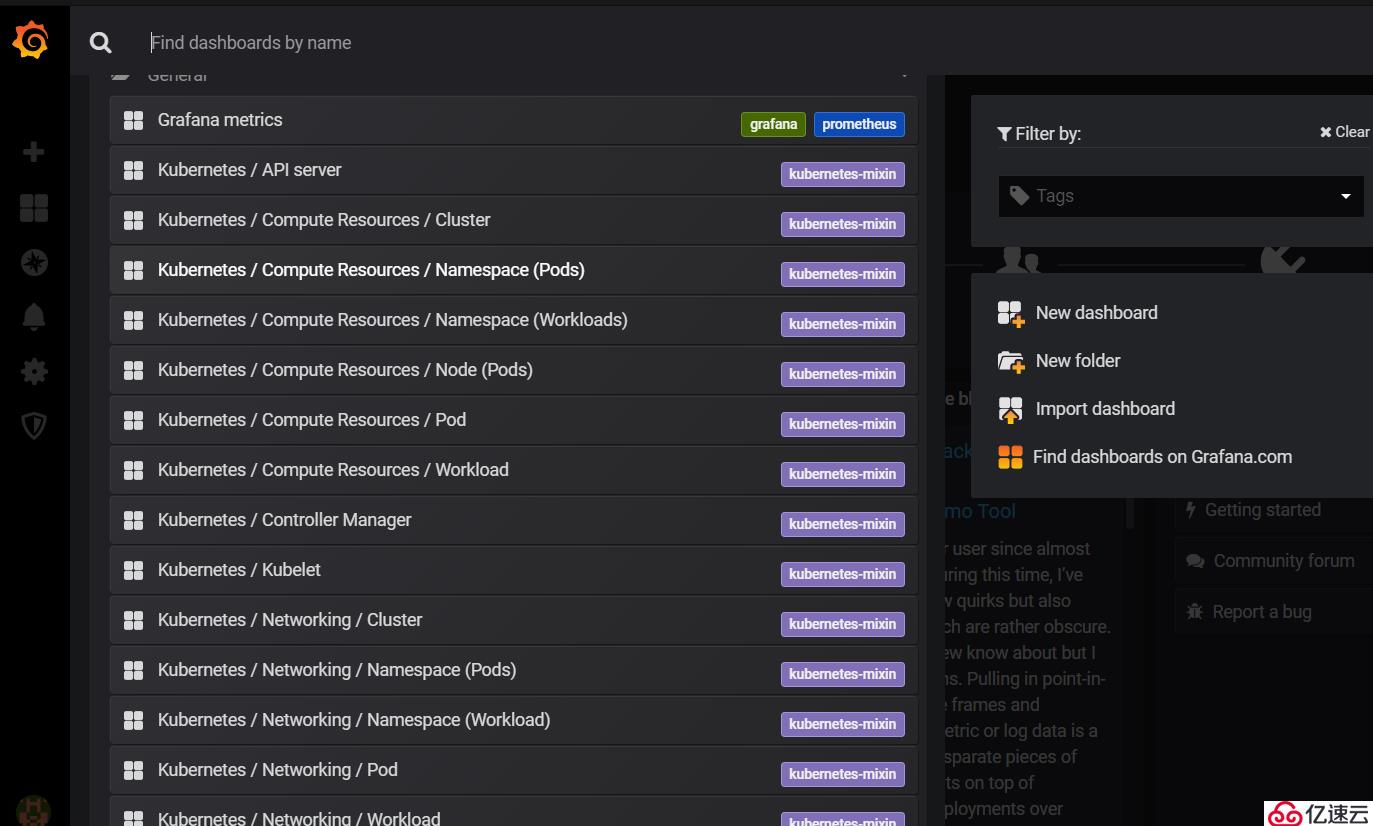
如上圖所示,已為我們提供了一些內置資源監控模板,大家可以選擇查看需要監控的資源。下面將展示幾個重要監控的資源對象信息:
1)查看集群資源信息:
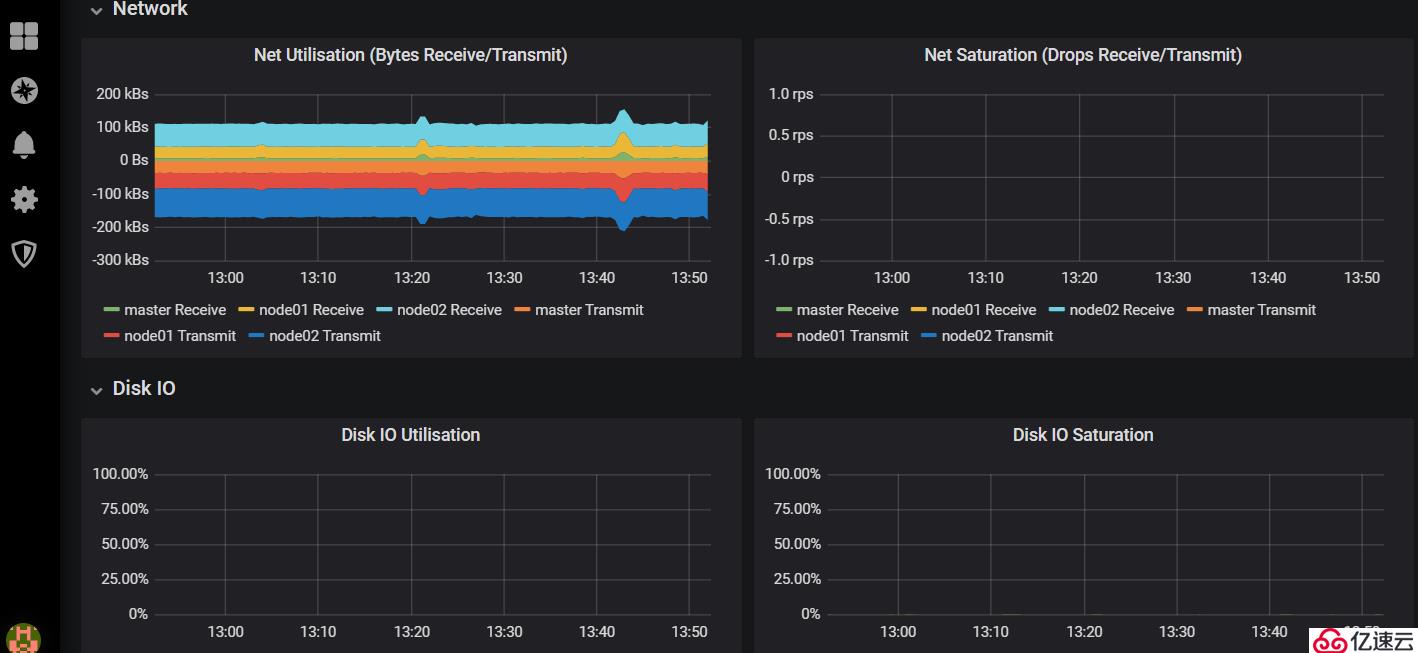
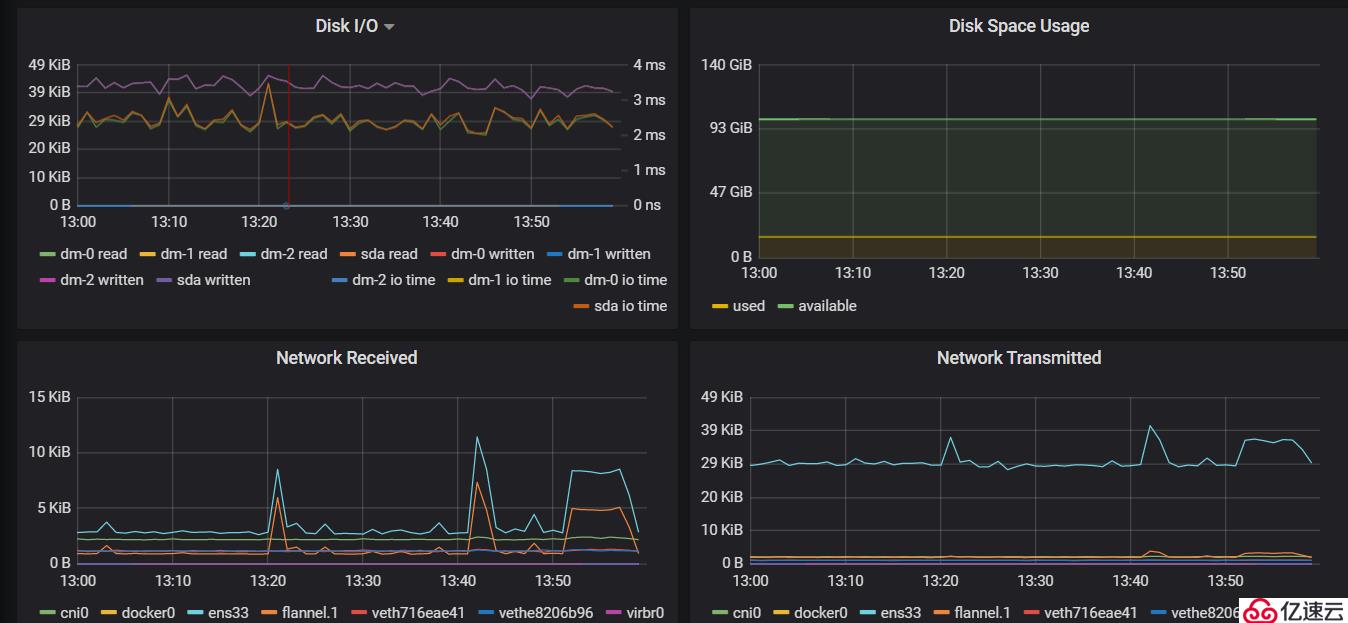
#可以看到集群中cpu,memory,network以及磁盤IO等使用信息的展示。
2)查看各個節點資源的使用情況: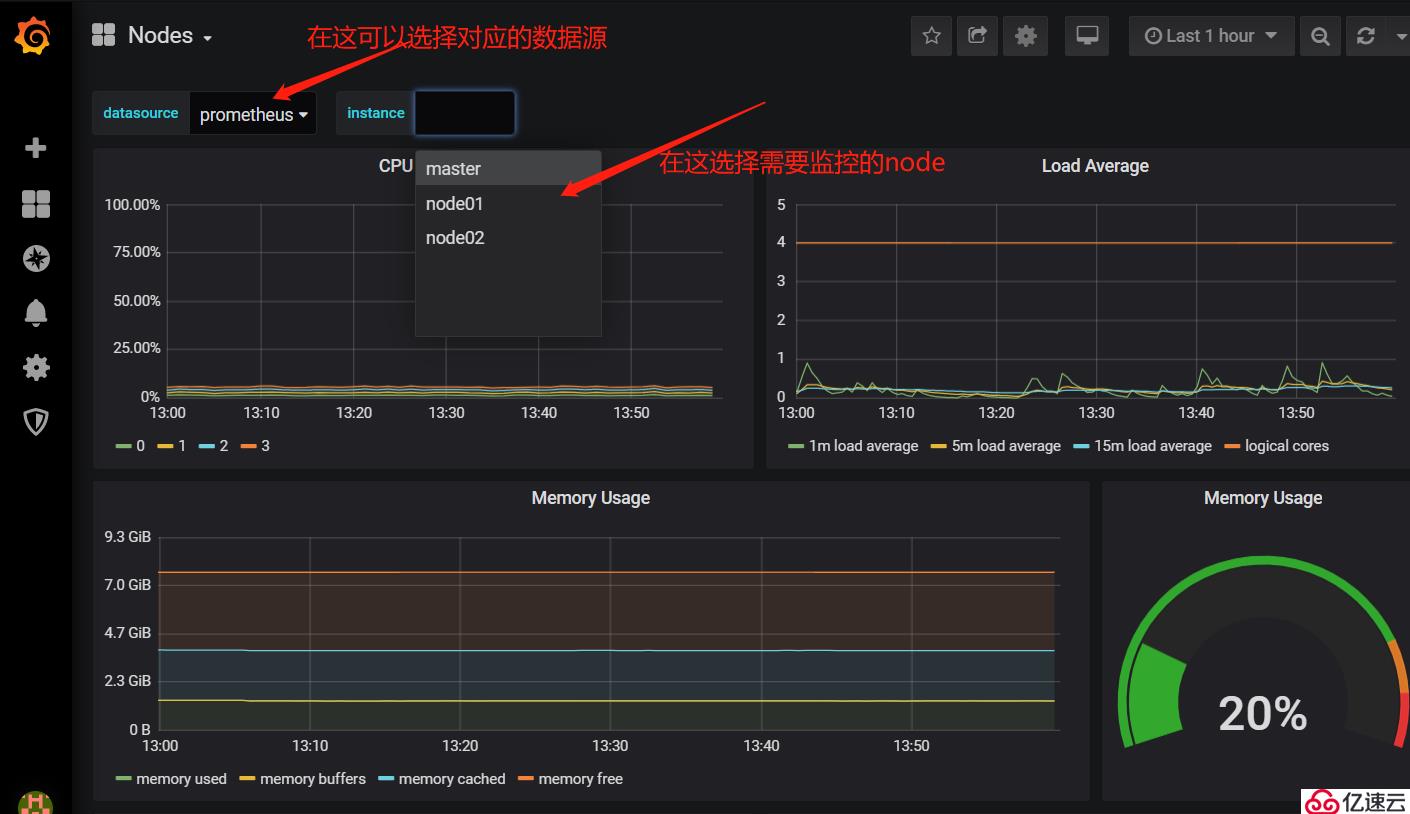
3)Pod資源查看: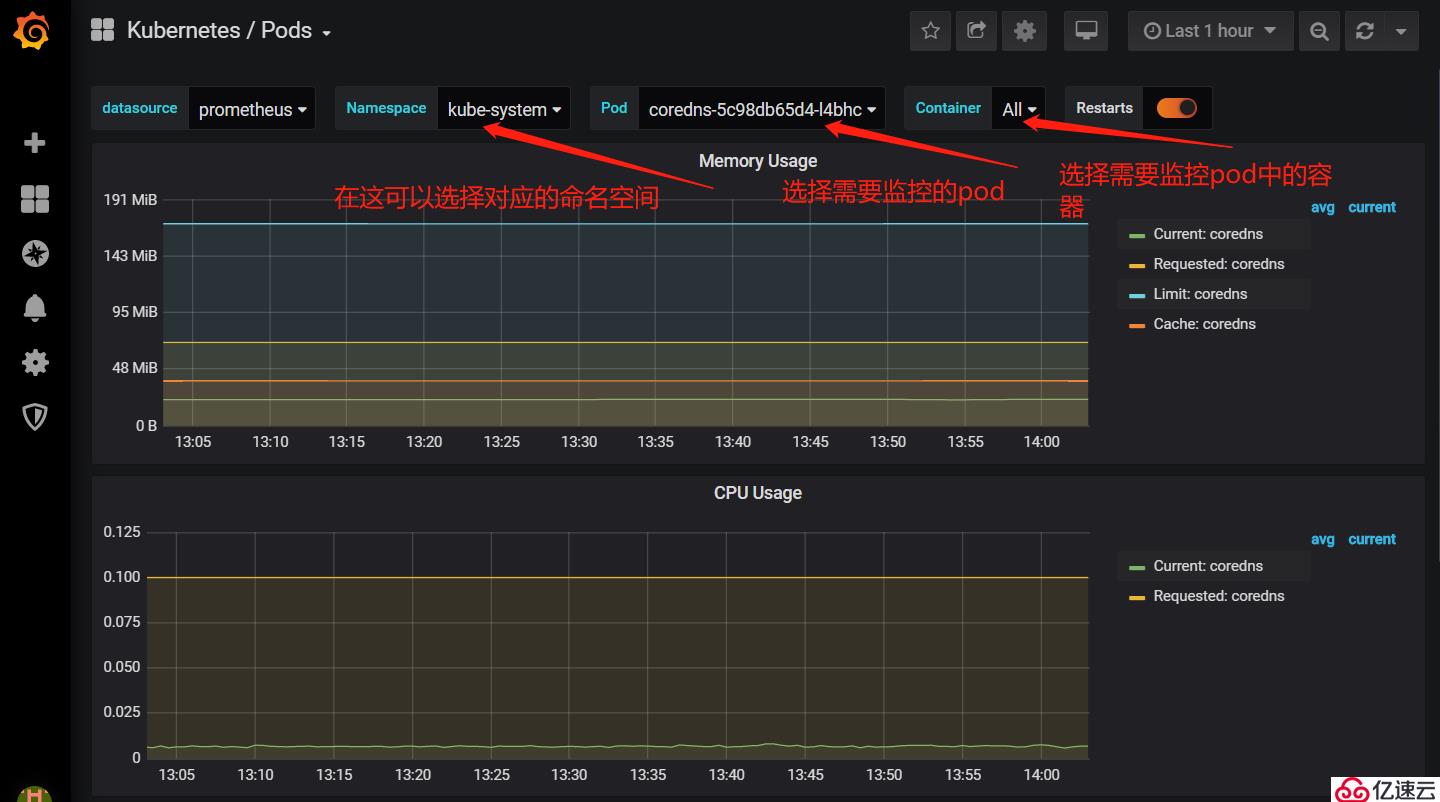
#如上所示,可以看到Prometheus為我們提供的資源監控項還是非常全面的。其他資源監控項大家可以自行查看。
4,其他監控模板
grafana提供自帶的監控模板是非常豐富的,不過我們也可以進入Grafana官網下載其他監控模板。
1)下載監控模板,如下圖所示:
比如,我們選擇Node Exporter for Prometheus 模板:
2)在Grafana web界面上導入模板: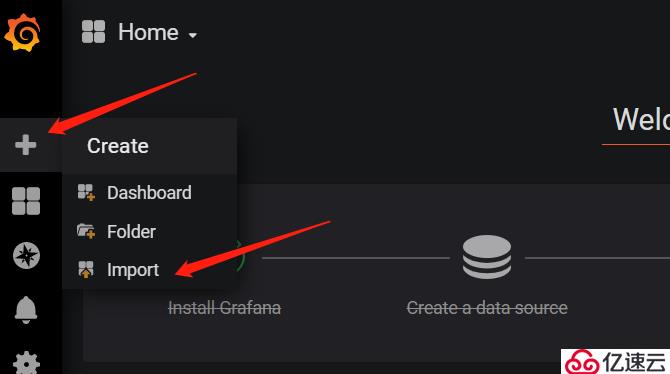
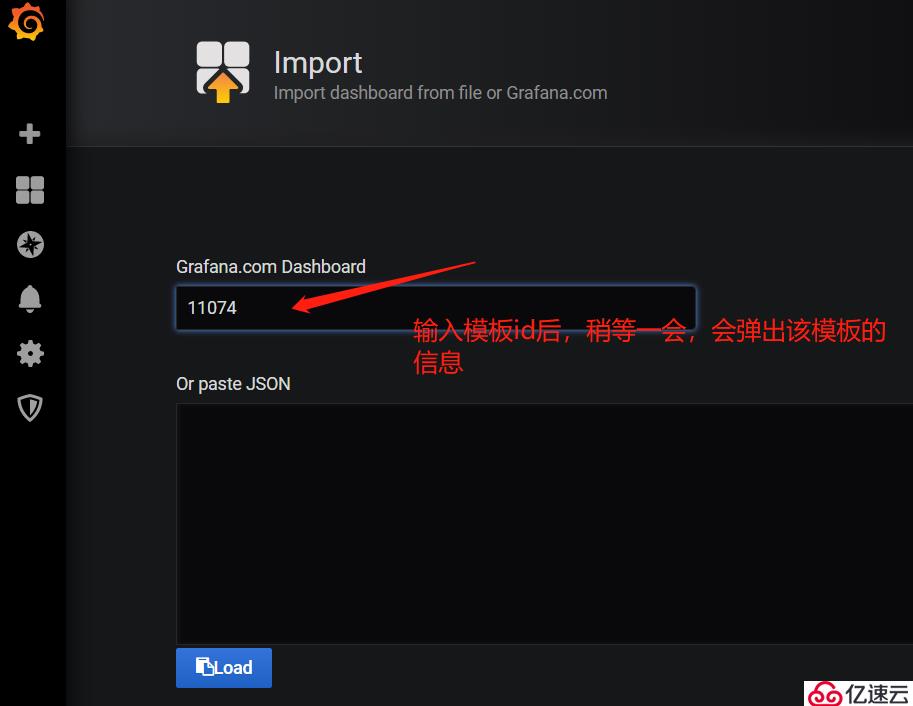
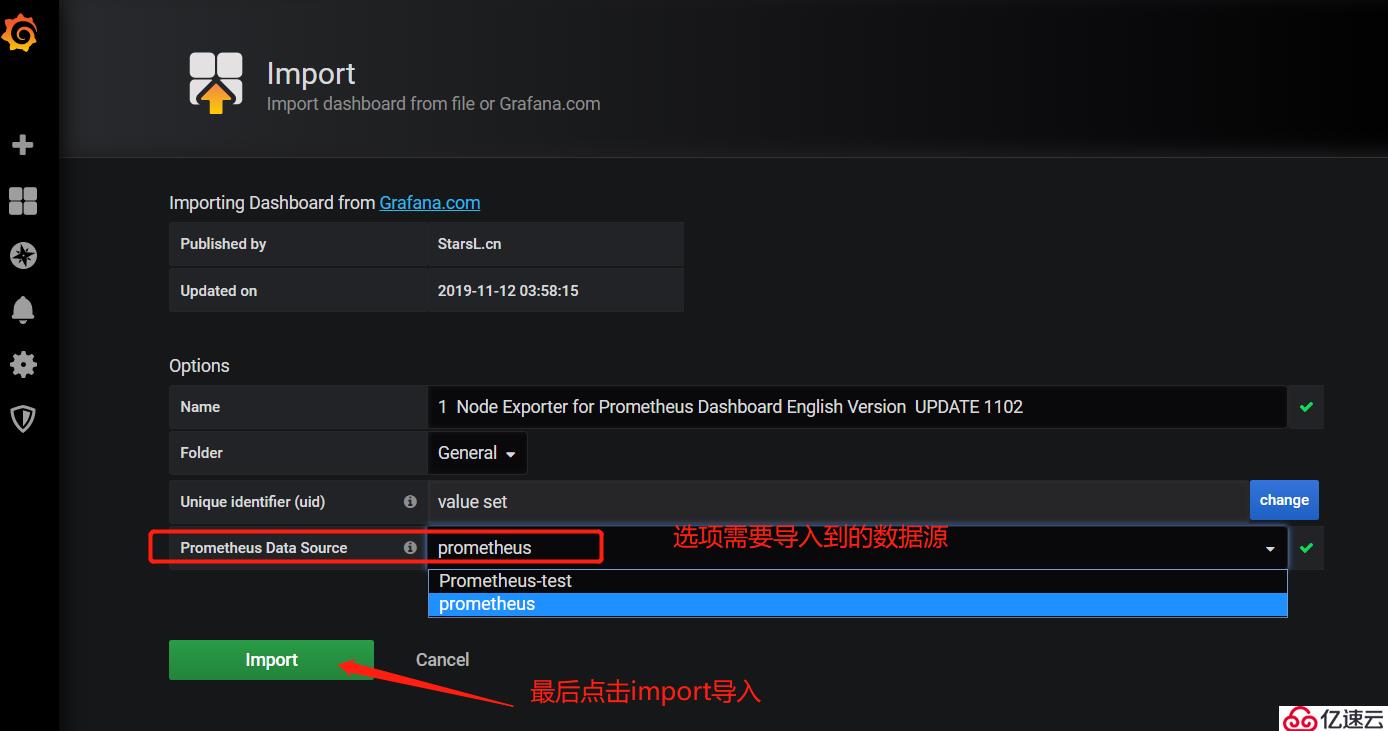
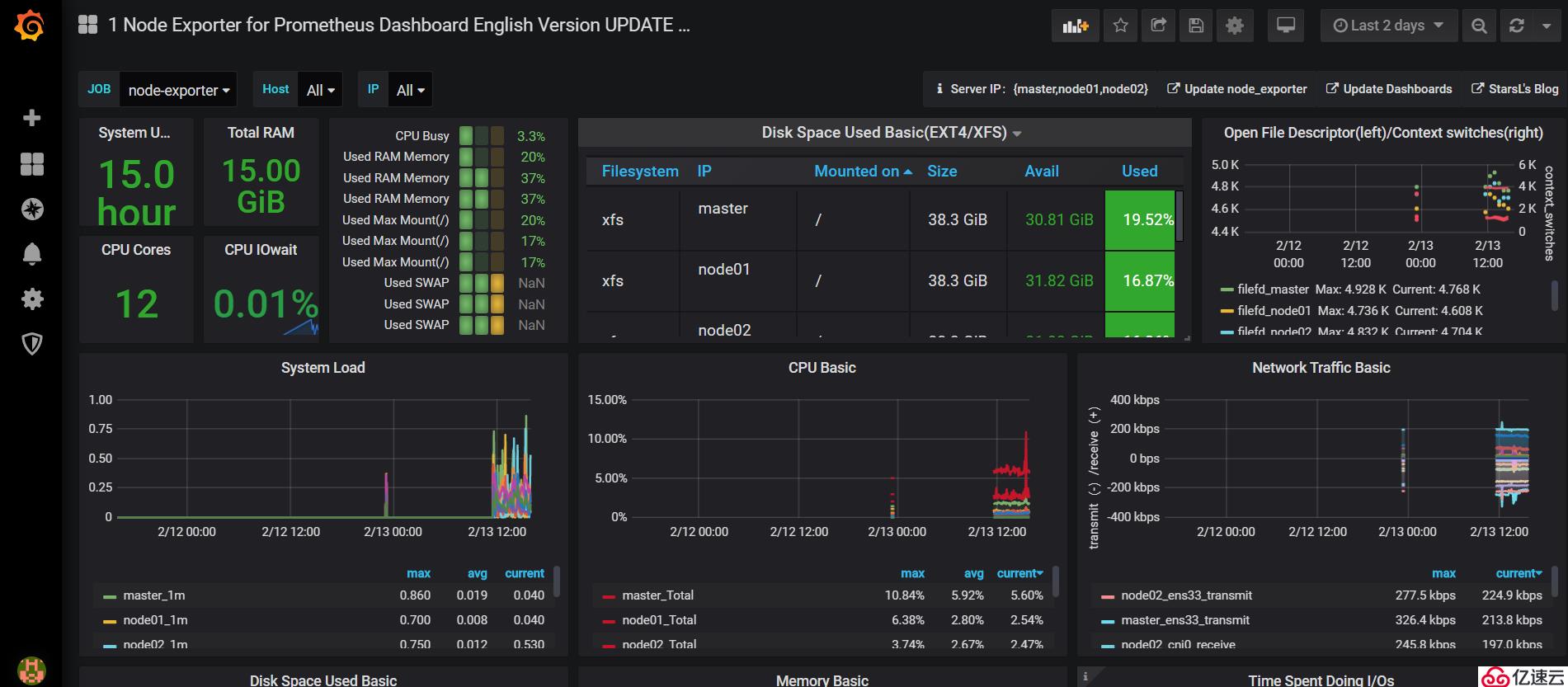
模板導入成功,其他類型的監控模板大家可以自己在Grafana官網上去下載。
Alertmanager實現郵箱告警可參考博文:監控利器-Prometheus安裝與部署+實現郵箱報警
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





