溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關iOS中如何實現自帶超強中文分詞器的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
效果如下:
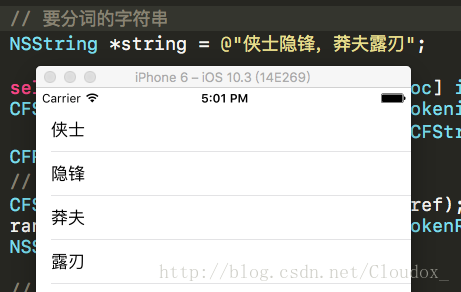
實現
其實蘋果給出了完整的API,想要全面了解的可以直接看文檔:CFStringTokenizer Reference
這里說說簡單的一個實現:
// 要分詞的字符串
NSString *string = @"俠士隱鋒,莽夫露刃";
self.keywords = [[NSMutableArray alloc] init];
CFStringTokenizerRef ref = CFStringTokenizerCreate(NULL, (__bridge CFStringRef)string, CFRangeMake(0, string.length), kCFStringTokenizerUnitWord, NULL);// 創建分詞器
CFRange range;// 當前分詞的位置
// 獲取第一個分詞的范圍
CFStringTokenizerAdvanceToNextToken(ref);
range = CFStringTokenizerGetCurrentTokenRange(ref);
// 循環遍歷獲取所有分詞并記錄到數組中
NSString *keyWord;
while (range.length>0) {
keyWord = [string substringWithRange:NSMakeRange(range.location, range.length)];
[self.keywords addObject:keyWord];
CFStringTokenizerAdvanceToNextToken(ref);
range = CFStringTokenizerGetCurrentTokenRange(ref);
}其實邏輯很簡單:創建分詞器–>一個個地一次獲取分詞后的每個詞的起始位置和長度,從而取出詞。
示例里我用列表顯示每個分詞,比較清楚,列表的實現就不說明了,可以直接看工程代碼。
值得一提的是,其分詞速度很快,甚至一些網絡詞匯比如“木有”,一些成語等等都能夠識別出,能看出這是分詞的什么嗎:

感謝各位的閱讀!關于“iOS中如何實現自帶超強中文分詞器”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





