溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關JAVA中序列化和反序列化的原理是什么,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
一、基本概念
1、什么是序列化和反序列化
(1)Java序列化是指把Java對象轉換為字節序列的過程,而Java反序列化是指把字節序列恢復為Java對象的過程;
(2)**序列化:**對象序列化的最主要的用處就是在傳遞和保存對象的時候,保證對象的完整性和可傳遞性。序列化是把對象轉換成有序字節流,以便在網絡上傳輸或者保存在本地文件中。序列化后的字節流保存了Java對象的狀態以及相關的描述信息。序列化機制的核心作用就是對象狀態的保存與重建。
(3)**反序列化:**客戶端從文件中或網絡上獲得序列化后的對象字節流后,根據字節流中所保存的對象狀態及描述信息,通過反序列化重建對象。
(4)本質上講,序列化就是把實體對象狀態按照一定的格式寫入到有序字節流,反序列化就是從有序字節流重建對象,恢復對象狀態。
2、為什么需要序列化與反序列化
我們知道,當兩個進程進行遠程通信時,可以相互發送各種類型的數據,包括文本、圖片、音頻、視頻等, 而這些數據都會以二進制序列的形式在網絡上傳送。
那么當兩個Java進程進行通信時,能否實現進程間的對象傳送呢?答案是可以的!如何做到呢?這就需要Java序列化與反序列化了!
換句話說,一方面,發送方需要把這個Java對象轉換為字節序列,然后在網絡上傳送;另一方面,接收方需要從字節序列中恢復出Java對象。
當我們明晰了為什么需要Java序列化和反序列化后,我們很自然地會想Java序列化的好處。其好處一是實現了數據的持久化,通過序列化可以把數據永久地保存到硬盤上(通常存放在文件里),二是,利用序列化實現遠程通信,即在網絡上傳送對象的字節序列。
總的來說可以歸結為以下幾點:
(1)永久性保存對象,保存對象的字節序列到本地文件或者數據庫中;
(2)通過序列化以字節流的形式使對象在網絡中進行傳遞和接收;
(3)通過序列化在進程間傳遞對象;
3、序列化算法一般會按步驟做如下事情:
(1)將對象實例相關的類元數據輸出。
(2)遞歸地輸出類的超類描述直到不再有超類。
(3)類元數據完了以后,開始從最頂層的超類開始輸出對象實例的實際數據值。
(4)從上至下遞歸輸出實例的數據
二、Java如何實現序列化和反序列化
1、JDK類庫中序列化和反序列化API
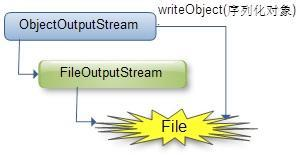
(1)java.io.ObjectOutputStream:表示對象輸出流;
它的writeObject(Object obj)方法可以對參數指定的obj對象進行序列化,把得到的字節序列寫到一個目標輸出流中;
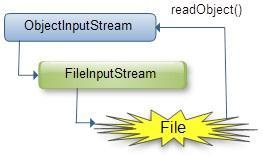
(2)java.io.ObjectInputStream:表示對象輸入流;
它的readObject()方法源輸入流中讀取字節序列,再把它們反序列化成為一個對象,并將其返回;
2、實現序列化的要求
只有實現了Serializable或Externalizable接口的類的對象才能被序列化,否則拋出異常!
3、實現Java對象序列化與反序列化的方法
假定一個User類,它的對象需要序列化,可以有如下三種方法:
(1)若User類僅僅實現了Serializable接口,則可以按照以下方式進行序列化和反序列化
ObjectOutputStream采用默認的序列化方式,對User對象的非transient的實例變量進行序列化。
ObjcetInputStream采用默認的反序列化方式,對對User對象的非transient的實例變量進行反序列化。
(2)若User類僅僅實現了Serializable接口,并且還定義了readObject(ObjectInputStream in)和writeObject(ObjectOutputSteam out),則采用以下方式進行序列化與反序列化。
ObjectOutputStream調用User對象的writeObject(ObjectOutputStream out)的方法進行序列化。
ObjectInputStream會調用User對象的readObject(ObjectInputStream in)的方法進行反序列化。
(3)若User類實現了Externalnalizable接口,且User類必須實現readExternal(ObjectInput in)和writeExternal(ObjectOutput out)方法,則按照以下方式進行序列化與反序列化。
ObjectOutputStream調用User對象的writeExternal(ObjectOutput out))的方法進行序列化。
ObjectInputStream會調用User對象的readExternal(ObjectInput in)的方法進行反序列化。
4、JDK類庫中序列化的步驟
步驟一:創建一個對象輸出流,它可以包裝一個其它類型的目標輸出流,如文件輸出流:
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("D:\\object.out"));步驟二:通過對象輸出流的writeObject()方法寫對象:
oos.writeObject(new User("xuliugen", "123456", "male"));5、JDK類庫中反序列化的步驟
步驟一:創建一個對象輸入流,它可以包裝一個其它類型輸入流,如文件輸入流:
ObjectInputStream ois= new ObjectInputStream(new FileInputStream("object.out"));步驟二:通過對象輸出流的readObject()方法讀取對象:
User user = (User) ois.readObject();
說明:為了正確讀取數據,完成反序列化,必須保證向對象輸出流寫對象的順序與從對象輸入流中讀對象的順序一致。
6、序列化和反序列化的示例
為了更好地理解Java序列化與反序列化,舉一個簡單的示例如下:
public class SerialDemo {
public static void main(String[] args) throws IOException, ClassNotFoundException {
//序列化
FileOutputStream fos = new FileOutputStream("object.out");
ObjectOutputStream oos = new ObjectOutputStream(fos);
User user1 = new User("xuliugen", "123456", "male");
oos.writeObject(user1);
oos.flush();
oos.close();
//反序列化
FileInputStream fis = new FileInputStream("object.out");
ObjectInputStream ois = new ObjectInputStream(fis);
User user2 = (User) ois.readObject();
System.out.println(user2.getUserName()+ " " +
user2.getPassword() + " " + user2.getSex());
//反序列化的輸出結果為:xuliugen 123456 male
}
}
public class User implements Serializable {
private String userName;
private String password;
private String sex;
//全參構造方法、get和set方法省略
}object.out文件如下(使用UltraEdit打開):

注:上圖中0000000h-000000c0h表示行號;0-f表示列;行后面的文字表示對這行16進制的解釋;對上述字節碼所表述的內容感興趣的可以對照相關的資料,查閱一下每一個字符代表的含義,這里不在探討!
類似于我們Java代碼編譯之后的.class文件,每一個字符都代表一定的含義。序列化和反序列化的過程就是生成和解析上述字符的過程!
序列化圖示:
反序列化圖示:
三、相關注意事項
1、序列化時,只對對象的狀態進行保存,而不管對象的方法;
2、當一個父類實現序列化,子類自動實現序列化,不需要顯式實現Serializable接口;
3、當一個對象的實例變量引用其他對象,序列化該對象時也把引用對象進行序列化;
4、并非所有的對象都可以序列化,至于為什么不可以,有很多原因了,比如:
安全方面的原因,比如一個對象擁有private,public等field,對于一個要傳輸的對象,比如寫到文件,或者進行RMI傳輸等等,在序列化進行傳輸的過程中,這個對象的private等域是不受保護的;
資源分配方面的原因,比如socket,thread類,如果可以序列化,進行傳輸或者保存,也無法對他們進行重新的資源分配,而且,也是沒有必要這樣實現;
5、聲明為static和transient類型的成員數據不能被序列化。因為static代表類的狀態,transient代表對象的臨時數據。
6、序列化運行時使用一個稱為 serialVersionUID 的版本號與每個可序列化類相關聯,該序列號在反序列化過程中用于驗證序列化對象的發送者和接收者是否為該對象加載了與序列化兼容的類。為它賦予明確的值。顯式地定義serialVersionUID有兩種用途:
在某些場合,希望類的不同版本對序列化兼容,因此需要確保類的不同版本具有相同的serialVersionUID;
在某些場合,不希望類的不同版本對序列化兼容,因此需要確保類的不同版本具有不同的serialVersionUID。
7、Java有很多基礎類已經實現了serializable接口,比如String,Vector等。但是也有一些沒有實現serializable接口的;
8、如果一個對象的成員變量是一個對象,那么這個對象的數據成員也會被保存!這是能用序列化解決深拷貝的重要原因;
看完上述內容,你們對JAVA中序列化和反序列化的原理是什么有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





