溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了springboot中如何實現kafa指定offset消費,文中通過示例代碼介紹的非常詳細,對大家的學習或者工作具有一定的參考學習價值,需要的朋友可以參考下
kafka消費過程難免會遇到需要重新消費的場景,例如我們消費到kafka數據之后需要進行存庫操作,若某一時刻數據庫down了,導致kafka消費的數據無法入庫,為了彌補數據庫down期間的數據損失,有一種做法我們可以指定kafka消費者的offset到之前某一時間的數值,然后重新進行消費。
首先創建kafka消費服務
@Service
@Slf4j
//實現CommandLineRunner接口,在springboot啟動時自動運行其run方法。
public class TspLogbookAnalysisService implements CommandLineRunner {
@Override
public void run(String... args) {
//do something
}
}
kafka消費模型建立
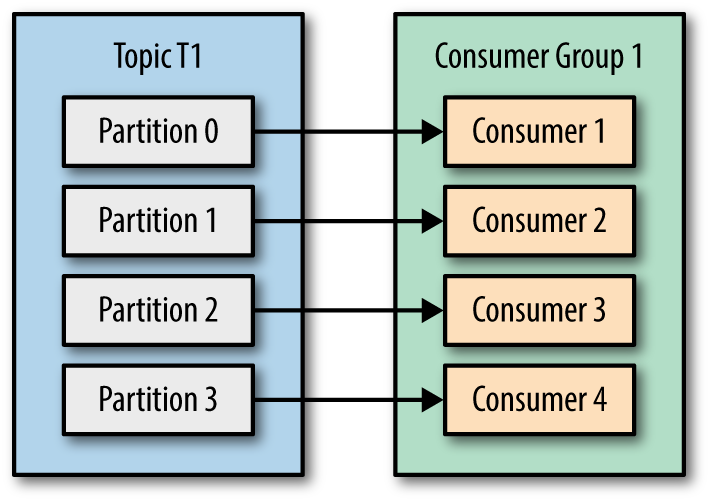
kafka server中每個主題存在多個分區(partition),每個分區自己維護一個偏移量(offset),我們的目標是實現kafka consumer指定offset消費。
在這里使用consumer-->partition一對一的消費模型,每個consumer各自管理自己的partition。
@Service
@Slf4j
public class TspLogbookAnalysisService implements CommandLineRunner {
//聲明kafka分區數相等的消費線程數,一個分區對應一個消費線程
private static final int consumeThreadNum = 9;
//特殊指定每個分區開始消費的offset
private List<Long> partitionOffsets = Lists.newArrayList(1111,1112,1113,1114,1115,1116,1117,1118,1119);
private ExecutorService executorService = Executors.newFixedThreadPool(consumeThreadNum);
@Override
public void run(String... args) {
//循環遍歷創建消費線程
IntStream.range(0, consumeThreadNum)
.forEach(partitionIndex -> executorService.submit(() -> startConsume(partitionIndex)));
}
}
kafka consumer對offset的處理
聲明kafka consumer的配置類
private Properties buildKafkaConfig() {
Properties kafkaConfiguration = new Properties();
kafkaConfiguration.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.GROUP_ID_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"");
kafkaConfiguration.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "");
...更多配置項
return kafkaConfiguration;
}
創建kafka consumer,處理offset,開始消費數據任務#
private void startConsume(int partitionIndex) {
//創建kafka consumer
KafkaConsumer<String, byte[]> consumer = new KafkaConsumer<>(buildKafkaConfig());
try {
//指定該consumer對應的消費分區
TopicPartition partition = new TopicPartition(kafkaProperties.getKafkaTopic(), partitionIndex);
consumer.assign(Lists.newArrayList(partition));
//consumer的offset處理
if (collectionUtils.isNotEmpty(partitionOffsets) && partitionOffsets.size() == consumeThreadNum) {
Long seekOffset = partitionOffsets.get(partitionIndex);
log.info("partition:{} , offset seek from {}", partition, seekOffset);
consumer.seek(partition, seekOffset);
}
//開始消費數據任務
kafkaRecordConsume(consumer, partition);
} catch (Exception e) {
log.error("kafka consume error:{}", ExceptionUtils.getFullStackTrace(e));
} finally {
try {
consumer.commitSync();
} finally {
consumer.close();
}
}
}
消費數據邏輯,offset操作
private void kafkaRecordConsume(KafkaConsumer<String, byte[]> consumer, TopicPartition partition) {
while (true) {
try {
ConsumerRecords<String, byte[]> records = consumer.poll(TspLogbookConstants.POLL_TIMEOUT);
//具體的處理流程
records.forEach((k) -> handleKafkaInput(k.key(), k.value()));
//🌿很重要:日志記錄當前consumer的offset,partition相關信息(之后如需重新指定offset消費就從這里的日志中獲取offset,partition信息)
if (records.count() > 0) {
String currentOffset = String.valueOf(consumer.position(partition));
log.info("current records size is:{}, partition is: {}, offset is:{}", records.count(), consumer.assignment(), currentOffset);
}
//offset提交
consumer.commitAsync();
} catch (Exception e) {
log.error("handlerKafkaInput error{}", ExceptionUtils.getFullStackTrace(e));
}
}
}
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





