溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
在CentOS8下搭建PXC集群一文中,演示了如何從零開始搭建一個三節點的PXC集群。但是光搭建了PXC集群還不夠,因為在實際的企業應用中,可能會存在多個PXC集群,每個集群作為一個數據分片存在。因此,在完整的架構下我們還需要為集群引入數據庫中間件,以實現數據分片和負載均衡等功能。
市面上有許多的數據庫中間件,這些中間件主要分為兩種類型,負載均衡型和數據切分型(通常數據切分型會具備負載均衡功能):
負載均衡型中間件的作用:
數據切分型中間件的作用:
以下是對常見的中間件進行的一個比較:
| 名稱 | 是否開源免費 | 負載能力 | 開發語言 | 功能 | 文檔 | 普及率 |
|---|---|---|---|---|---|---|
| MyCat | 開源免費 | 基于阿里巴巴的Corba中間件重構而來,有高訪問量的檢驗 | Java | 功能全面,有豐富的分片算法以及讀寫分離、全局主鍵和分布式事務等功能 | 文檔豐富,不僅有官方的《Mycat權威指南》,還有許多社區貢獻的文檔 | 電信、電商領域均有應用,是國內普及率最高的MySQL中間件 |
| Atlas | 開源免費 | 基于MySQL Proxy,主要用于360產品,有每天承載幾十億次請求的訪問量檢驗 | C語言 | 功能有限,實現了讀寫分離,具有少量的數據切分算法,不支持全局主鍵和分布式事務 | 文檔較少,只有開源項目文檔,無技術社區和出版物 | 普及率低,除了奇虎360外,僅在一些中小型項目在使用,可供參考的案例不多 |
| OneProxy | 分為免費版和企業版 | 基于C語言的內核,性能較好 | C語言 | 功能有限,實現了讀寫分離,具有少量的數據切分算法,不支持全局主鍵和分布式事務 | 文檔較少,官網不提供使用文檔,無技術社區和出版物 | 普及率低,僅僅在一些中小型企業的內部系統中使用過 |
| ProxySQL | 開源免費 | 性能出眾,Percona推薦 | C++ | 功能相對豐富,支持讀寫分離、數據切分、故障轉移及查詢緩存等 | 文檔豐富,有官方文檔和技術社區 | 普及率相比于Mycat要低,但已有許多公司嘗試使用 |
經過上一小節的介紹與比較,可以看出MyCat與ProxySQL是比較理想的數據庫中間件。由于MyCat相對于ProxySQL功能更全面,普及率也更高一些,所以這里采用Mycat來做為PXC集群的中間件。關于Mycat的介紹與安裝,可以參考我的另一篇Mycat 快速入門,這里就不再重復了。
本小節主要介紹如何配置Mycat的數據切分功能,讓Mycat作為前端的數據切分中間件轉發SQL請求到后端的PXC集群分片中。因此,這里我搭建了兩個PXC集群,每個集群就是一個分片,以及搭建了兩個Mycat節點和兩個Haproxy節點用于后面組建雙機熱備。如圖: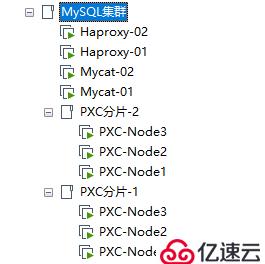
各個節點的信息如下表:
| 角色 | Host | IP |
|---|---|---|
| Haproxy-Master | Haproxy-Master | 192.168.190.140 |
| Haproxy-Backup | Haproxy-Backup | 192.168.190.141 |
| Mycat:Node1 | mycat-01 | 192.168.190.136 |
| Mycat:Node2 | mycat-02 | 192.168.190.135 |
| PXC分片-1:Node1 | PXC-Node1 | 192.168.190.132 |
| PXC分片-1:Node2 | PXC-Node2 | 192.168.190.133 |
| PXC分片-1:Node3 | PXC-Node3 | 192.168.190.134 |
| PXC分片-2:Node1 | PXC-Node1 | 192.168.190.137 |
| PXC分片-2:Node2 | PXC-Node2 | 192.168.190.138 |
| PXC分片-2:Node3 | PXC-Node3 | 192.168.190.139 |
在每個分片里創建一個test庫,并在該庫中創建一張t_user表用作測試,具體的建表SQL如下:
CREATE TABLE `t_user` (
`id` int(11) NOT NULL,
`username` varchar(20) NOT NULL,
`password` char(36) NOT NULL,
`tel` char(11) NOT NULL,
`locked` char(10) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_username` (`username`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;完成以上準備后,接著我們開始配置Mycat,如果你對Mycat的配置文件不了解的話,可以參考我另一篇文章:Mycat 核心配置詳解,本文就不贅述了。
1、編輯server.xml文件,配置Mycat的訪問用戶:
<user name="admin" defaultAccount="true">
<property name="password">Abc_123456</property>
<property name="schemas">test</property>
<property name="defaultSchema">test</property>
</user>2、編輯schema.xml文件,配置Mycat的邏輯庫、邏輯表以及集群節點的連接信息:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 配置邏輯庫 -->
<schema name="test" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<!-- 配置邏輯表 -->
<table name="t_user" dataNode="dn1,dn2" rule="mod-long"/>
</schema>
<!-- 配置數據分片,每個分片都會有一個索引值,從0開始。例如,dn1索引值為0,dn2的索引值為1,以此類推 -->
<!-- 分片的索引與分片算法有關,分片算法計算得出的值就是分片索引 -->
<dataNode name="dn1" dataHost="pxc-cluster1" database="test" />
<dataNode name="dn2" dataHost="pxc-cluster2" database="test" />
<!-- 配置集群節點的連接信息 -->
<dataHost name="pxc-cluster1" maxCon="1000" minCon="10" balance="2"
writeType="1" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="W1" url="192.168.190.132:3306" user="admin"
password="Abc_123456">
<readHost host="W1-R1" url="192.168.190.133:3306" user="admin" password="Abc_123456"/>
<readHost host="W1-R2" url="192.168.190.134:3306" user="admin" password="Abc_123456"/>
</writeHost>
<writeHost host="W2" url="192.168.190.133:3306" user="admin"
password="Abc_123456">
<readHost host="W2-R1" url="192.168.190.132:3306" user="admin" password="Abc_123456"/>
<readHost host="W2-R2" url="192.168.190.134:3306" user="admin" password="Abc_123456"/>
</writeHost>
</dataHost>
<dataHost name="pxc-cluster2" maxCon="1000" minCon="10" balance="2"
writeType="1" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="W1" url="192.168.190.137:3306" user="admin" password="Abc_123456">
<readHost host="W1-R1" url="192.168.190.138:3306" user="admin" password="Abc_123456"/>
<readHost host="W1-R2" url="192.168.190.139:3306" user="admin" password="Abc_123456"/>
</writeHost>
<writeHost host="W2" url="192.168.190.138:3306" user="admin" password="Abc_123456">
<readHost host="W2-R1" url="192.168.190.137:3306" user="admin" password="Abc_123456"/>
<readHost host="W2-R2" url="192.168.190.138:3306" user="admin" password="Abc_123456"/>
</writeHost>
</dataHost>
</mycat:schema>3、編輯rule.xml文件,修改mod-long分片算法的求模基數,由于只有兩個集群作為分片,所以這里需要將基數改為2:
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property>
</function>id列的值對求模基數進行求模以得出數據分片的索引完成以上三個文件的配置后,啟動Mycat:
[root@mycat-01 ~]# mycat start
Starting Mycat-server...
[root@mycat-01 ~]# more /usr/local/mycat/logs/wrapper.log |grep successfully
# 日志輸出了 successfully 代表啟動成功
INFO | jvm 1 | 2020/01/19 15:09:02 | MyCAT Server startup successfully. see logs in logs/mycat.log啟動完成后,進入Mycat中執行一條insert語句,測試下是否能將該SQL轉發到正確的集群分片上。具體步驟如下:
[root@mycat-01 ~]# mysql -uadmin -P8066 -h227.0.0.1 -p
mysql> use test;
mysql> insert into t_user(id, username, password, tel, locked)
-> values(1, 'Jack', hex(AES_ENCRYPT('123456', 'Test')), '13333333333', 'N');上面這條insert語句插入的是一條id為1的記錄,而我們采用的是對id列求模的分片算法,配置的求模基數為2。因此,根據id的值和求模基數進行求模計算的結果為:1 % 2 = 1。得出來的1就是分片的索引,所以正常情況下Mycat會將該insert語句轉發到分片索引為1的集群上。
根據schema.xml文件中的配置,索引為1的分片對應的集群是pxc-cluster2,即第二個PXC集群分片。接下來,我們可以通過對比這兩個集群中的數據,以驗證Mycat是否按照預期正確地轉發了該SQL。
從下圖中可以看到,Mycat正確地將該insert語句轉發到了第二個分片上,此時第一個分片是沒有數據的: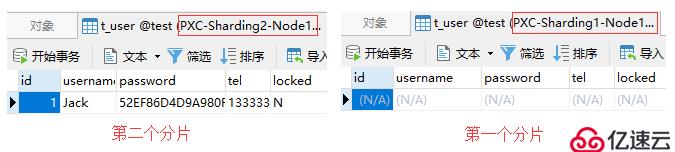
接著我們再測試當id為2時,Mycat是否能將該SQL轉發到第一個分片上。具體的SQL如下:
insert into t_user(id, username, password, tel, locked)
values(2, 'Jon', hex(AES_ENCRYPT('123456', 'Test')), '18888888888', 'N');測試結果如圖: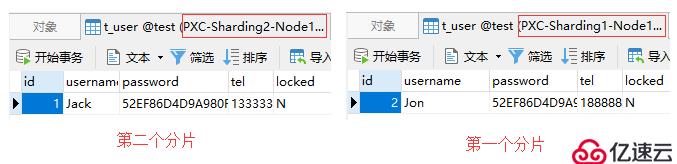
在完成以上的測試后,此時在Mycat上是能夠查詢出所有分片中的數據的: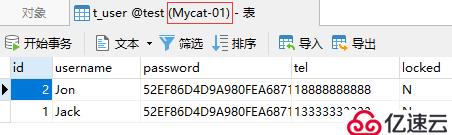
上一小節的示例中,使用的就是主鍵求模切分,其特點如下:
mapFile配置的映射關系來切分數據在Mycat 核心配置詳解一文中,也介紹過枚舉值切分算法。該算法相對于其他算法來說要用到一個額外的映射文件(mapFile),所以這里就針對該算法的使用進行一個簡單的演示。
需求:用戶表中有一個存儲用戶所在區號的列,要求將該列作為分片列,實現讓不同區號下的用戶數據被分別存儲到不同的分片中
1、首先,在Mycat的rule.xml文件中,增加如下配置:
<!-- 定義分片規則 -->
<tableRule name="sharding-by-areafile">
<rule>
<!-- 定義使用哪個列作為分片列 -->
<columns>area_id</columns>
<algorithm>area-int</algorithm>
</rule>
</tableRule>
<!-- 定義分片算法 -->
<function name="area-int" class="io.mycat.route.function.PartitionByFileMap">
<!-- 定義mapFile的文件名,位于conf目錄下 -->
<property name="mapFile">area-hash-int.txt</property>
</function>2、在conf目錄下創建area-hash-int.txt文件,定義區號與分片索引的對應關系:
[root@mycat-01 /usr/local/mycat]# vim conf/area-hash-int.txt
020=0
0755=0
0757=0
0763=1
0768=1
0751=13、配置schema.xml,增加一個邏輯表,并將其分片規則設置為sharding-by-areafile:
<schema name="test" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="t_user" dataNode="dn1,dn2" rule="mod-long"/>
<table name="t_customer" dataNode="dn1,dn2" rule="sharding-by-areafile"/>
</schema>4、進入Mycat中執行熱加載語句,該語句的作用可以使Mycat不用重啟就能應用新的配置:
[root@mycat-01 ~]# mysql -uadmin -P9066 -h227.0.0.1 -p
mysql> reload @@config_all;完成以上配置后,我們來建個表測試一下,在所有的集群中創建t_customer表。具體的建表SQL如下:
create table t_customer(
id int primary key,
username varchar(20) not null,
area_id int not null
);進入Mycat中插入一條area_id為020的記錄:
[root@mycat-01 ~]# mysql -uadmin -P8066 -h227.0.0.1 -p
mysql> use test;
mysql> insert into t_customer(id, username, area_id)
-> values(1, 'Jack', 020);根據映射文件中的配置,area_id為020的數據會被存儲到第一個分片中,如下圖: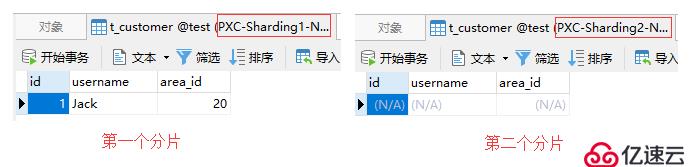
area_id是int類型的,所以前面的0會被去掉然后再插入一條area_id為0763的記錄:
insert into t_customer(id, username, area_id)
values(2, 'Tom', 0763);根據映射文件中的配置,area_id為0763的數據會被存儲到第二個分片中,如下圖: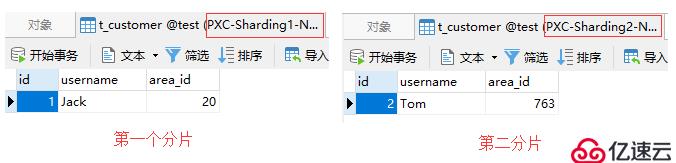
完成以上測試后,此時在Mycat中應能查詢到所有分片中的數據: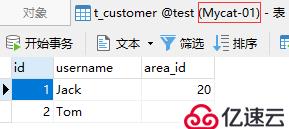
當有關聯的數據存儲在不同的分片時,就會遇到表連接的問題,在Mycat中是不允許跨分片做表連接查詢的。為了解決跨分片表連接的問題,Mycat提出了父子表這種解決方案。
父子表規定父表可以有任意的切分算法,但與之關聯的子表不允許有切分算法,即子表的數據總是與父表的數據存儲在一個分片中。父表不管使用什么切分算法,子表總是跟隨著父表存儲。
例如,用戶表與訂單表是有關聯關系的,我們可以將用戶表作為父表,訂單表作為子表。當A用戶被存儲至分片1中,那么A用戶產生的訂單數據也會跟隨著存儲在分片1中,這樣在查詢A用戶的訂單數據時就不需要跨分片了。如下圖所示:
了解了父子表的概念后,接下來我們看看如何在Mycat中配置父子表。首先,在schema.xml文件中配置父子表關系:
<schema name="test" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="t_customer" dataNode="dn1,dn2" rule="sharding-by-areafile">
<!-- 配置子表 -->
<childTable name="t_orders" joinKey="customer_id" parentKey="id"/>
</table>
</schema>childTable標簽說明:
joinKey屬性:定義子表中用于關聯父表的列parentKey屬性:定義父表中被關聯的列childTable標簽內還可以繼續添加childTable標簽完成以上配置后,讓Mycat重新加載配置文件:
reload @@config_all;接著在所有分片中創建t_orders表,具體的建表SQL如下:
create table t_orders(
id int primary key,
customer_id int not null,
create_time datetime default current_timestamp
);現在分片中有兩個用戶,id為1的用戶存儲在第一個分片,id為2的用戶存儲在第二個分片。此時,通過Mycat插入一條訂單記錄:
insert into t_orders(id, customer_id)
values(1, 1);由于該訂單記錄關聯的是id為1的用戶,根據父子表的規定,會被存儲至第一個分片中。如下圖: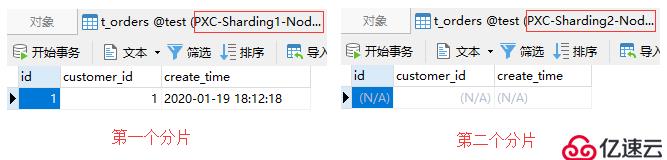
同樣,如果訂單記錄關聯的是id為2的用戶,那么就會被存儲至第二個分片中:
insert into t_orders(id, customer_id)
values(2, 2);測試結果如下: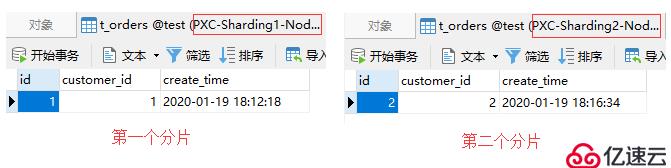
由于父子表的數據都是存儲在同一個分片,所以在Mycat上進行關聯查詢也是沒有問題的: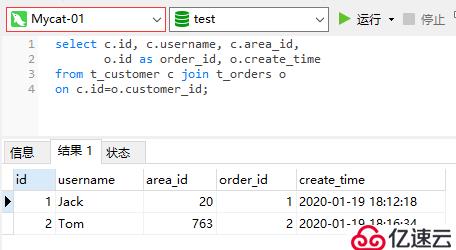
在以上小節的示例中,我們可以看到對后端數據庫集群的讀寫操作都是在Mycat上進行的。Mycat作為一個負責接收客戶端請求,并將請求轉發到后端數據庫集群的中間件,不可避免的需要具備高可用性。否則,如果Mycat出現單點故障,那么整個數據庫集群也就無法使用了,這對整個系統的影響是十分巨大的。
所以本小節將演示如何去構建一個高可用的Mycat集群,為了搭建Mycat高可用集群,除了要有兩個以上的Mycat節點外,還需要引入Haproxy和Keepalived組件。
其中Haproxy作為負載均衡組件,位于最前端接收客戶端的請求并將請求分發到各個Mycat節點上,用于保證Mycat的高可用。而Keepalived則用于實現雙機熱備,因為Haproxy也需要高可用,當一個Haproxy宕機時,另一個備用的Haproxy能夠馬上接替。也就說同一時間下只會有一個Haproxy在運行,另一個Haproxy作為備用處于等待狀態。當正在運行中的Haproxy因意外宕機時,Keepalived能夠馬上將備用的Haproxy切換到運行狀態。
Keepalived是讓主機之間爭搶同一個虛擬IP(VIP)來實現高可用的,這些主機分為Master和Backup兩種角色,并且Master只有一個,而Backup可以有多個。最開始Master先獲取到VIP處于運行狀態,當Master宕機后,Backup檢測不到Master的情況下就會自動獲取到這個VIP,此時發送到該VIP的請求就會被Backup接收到。這樣Backup就能無縫接替Master的工作,以實現高可用。
引入這些組件后,最終我們的集群架構將演變成這樣子: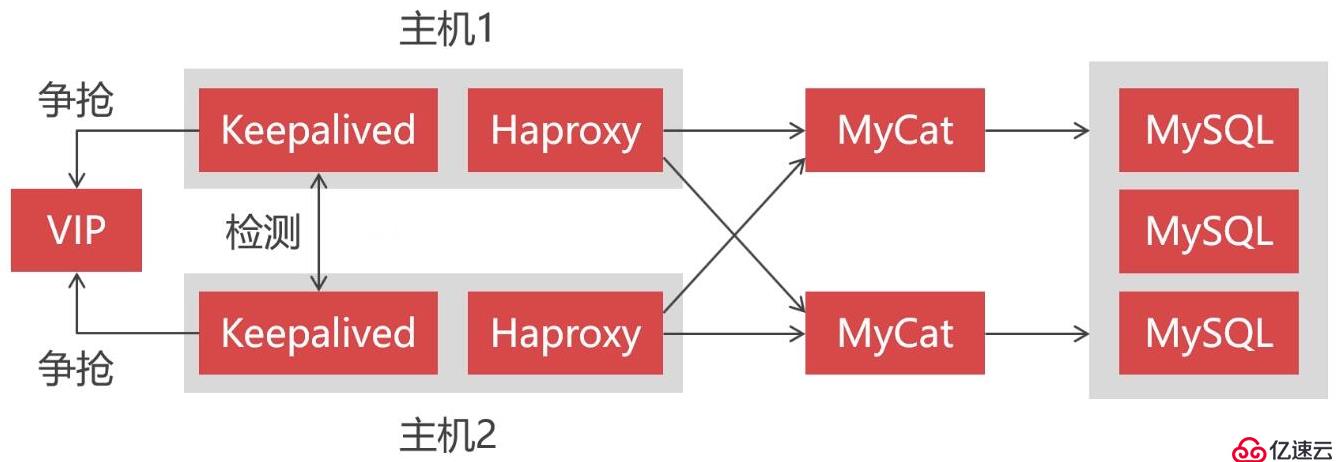
Haproxy由于是老牌的負載均衡組件了,所以CentOS的yum倉庫中自帶有該組件的安裝包,安裝起來就非常簡單。安裝命令如下:
[root@Haproxy-Master ~]# yum install -y haproxy配置Haproxy:
[root@Haproxy-Master ~]# vim /etc/haproxy/haproxy.cfg
# 在文件的末尾添加如下配置項
# 監控界面配置
listen admin_stats
# 綁定的ip及監聽的端口
bind 0.0.0.0:4001
# 訪問協議
mode http
# URI 相對地址
stats uri /dbs
# 統計報告格式
stats realm Global\ statistics
# 用于登錄監控界面的賬戶密碼
stats auth admin:abc123456
# 數據庫負載均衡配置
listen proxy-mysql
# 綁定的ip及監聽的端口
bind 0.0.0.0:3306
# 訪問協議
mode tcp
# 負載均衡算法
# roundrobin:輪詢
# static-rr:權重
# leastconn:最少連接
# source:請求源ip
balance roundrobin
# 日志格式
option tcplog
# 需要被負載均衡的主機
server mycat_01 192.168.190.136:8066 check port 8066 weight 1 maxconn 2000
server mycat_02 192.168.190.135:8066 check port 8066 weight 1 maxconn 2000
# 使用keepalive檢測死鏈
option tcpka由于配置了3306端口用于TCP轉發,以及4001作為Haproxy監控界面的訪問端口,所以在防火墻上需要開放這兩個端口:
[root@Haproxy-Master ~]# firewall-cmd --zone=public --add-port=3306/tcp --permanent
[root@Haproxy-Master ~]# firewall-cmd --zone=public --add-port=4001/tcp --permanent
[root@Haproxy-Master ~]# firewall-cmd --reload完成以上步驟后,啟動Haproxy服務:
[root@Haproxy-Master ~]# systemctl start haproxy然后使用瀏覽器訪問Haproxy的監控界面,初次訪問會要求輸入用戶名密碼,這里的用戶名密碼就是配置文件中所配置的:
登錄成功后,就會看到如下頁面: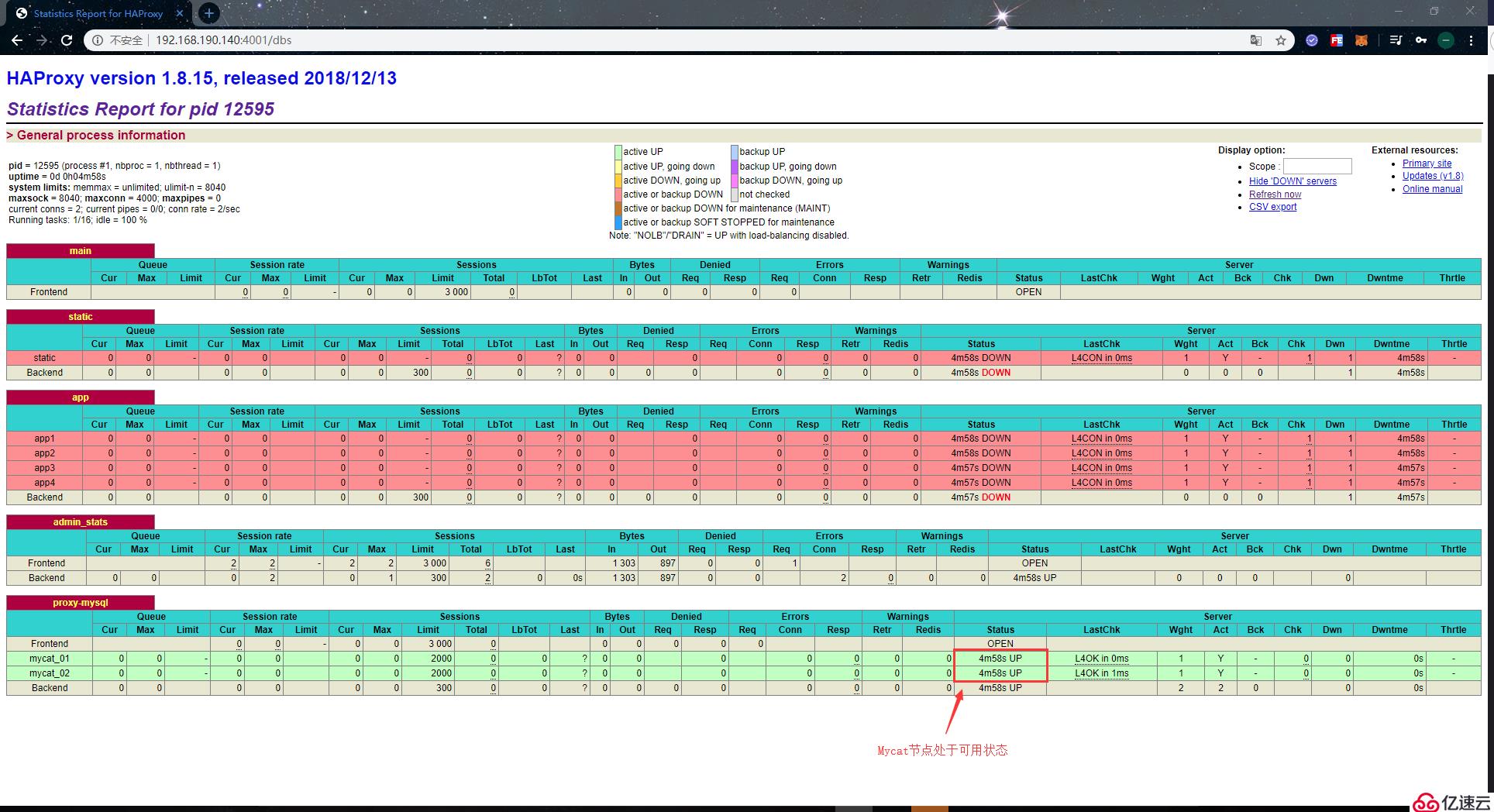
Haproxy的監控界面提供的監控信息也比較全面,在該界面下,我們可以看到每個主機的連接信息及其自身狀態。當主機無法連接時,Status一欄會顯示DOWN,并且背景色也會變為紅色。正常狀態下的值則為UP,背景色為綠色。
另一個Haproxy節點也是使用以上的步驟進行安裝和配置,這里就不再重復了。
Haproxy服務搭建起來后,我們來使用遠程工具測試一下能否通過Haproxy正常連接到Mycat。如下: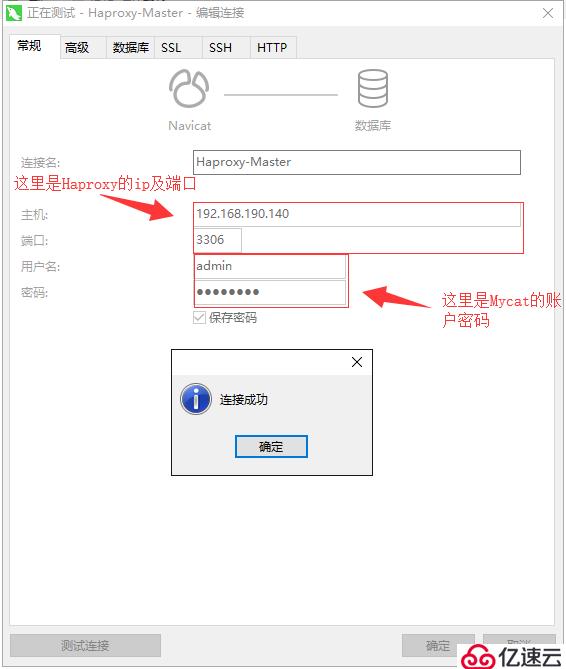
連接成功后,在Haproxy上執行一些SQL語句,看看能否正常插入數據和查詢數據: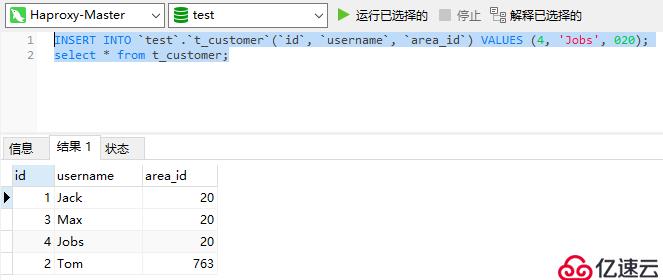
我們搭建Haproxy是為了讓Mycat具備高可用的,所以最后測試一下Mycat是否已具備有高可用性,首先將一個Mycat節點給停掉:
[root@mycat-01 ~]# mycat stop
Stopping Mycat-server...
Stopped Mycat-server.
[root@mycat-01 ~]#此時,從Haproxy的監控界面中,可以看到mycat_01這個節點已經處于下線狀態了:
現在集群中還剩一個Mycat節點,然后我們到Haproxy上執行一些SQL語句,看看是否還能正常插入數據和查詢數據: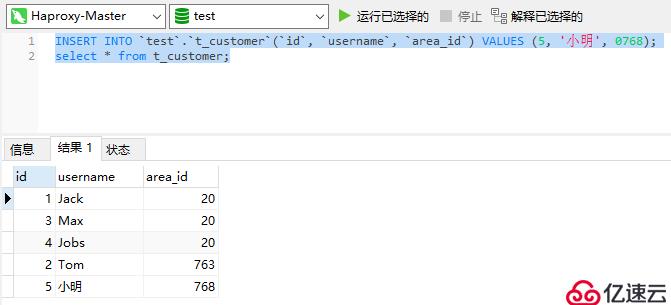
從測試結果可以看到,插入和查詢語句依舊是能正常執行的。也就是說即便此時關掉一個Mycat節點整個數據庫集群還能夠正常使用,說明現在Mycat集群是具有高可用性了。
實現了Mycat集群的高可用之后,我們還得實現Haproxy的高可用,因為現在的架構已經從最開始的Mycat面向客戶端變為了Haproxy面向客戶端。
而同一時間只需要存在一個可用的Haproxy,否則客戶端就不知道該連哪個Haproxy了。這也是為什么要采用VIP的原因,這種機制能讓多個節點互相接替時依舊使用同一個IP,客戶端至始至終只需要連接這個VIP。所以實現Haproxy的高可用就要輪到Keepalived出場了,在安裝Keepalived之前需要開啟防火墻的VRRP協議:
[root@Haproxy-Master ~]# firewall-cmd --direct --permanent --add-rule ipv4 filter INPUT 0 --protocol vrrp -j ACCEPT
[root@Haproxy-Master ~]# firewall-cmd --reload然后就可以使用yum命令安裝Keepalived了,需要注意Keepalived是安裝在Haproxy節點上的:
[root@Haproxy-Master ~]# yum install -y keepalived安裝完成后,編輯keepalived的配置文件:
[root@Haproxy-Master ~]# mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak # 不使用自帶的配置文件
[root@Haproxy-Master ~]# vim /etc/keepalived/keepalived.conf
vrrp_instance VI_1 {
state MASTER
interface ens32
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
192.168.190.100
}
}配置說明:
state MASTER:定義節點角色為master,當角色為master時,該節點無需爭搶就能獲取到VIP。集群內允許有多個master,當存在多個master時,master之間就需要爭搶VIP。為其他角色時,只有master下線才能獲取到VIPinterface ens32:定義可用于外部通信的網卡名稱,網卡名稱可以通過ip addr命令查看virtual_router_id 51:定義虛擬路由的id,取值在0-255,每個節點的值需要唯一,也就是不能配置成一樣的priority 100:定義權重,權重越高就越優先獲取到VIPadvert_int 1:定義檢測間隔時間為1秒authentication:定義心跳檢查時所使用的認證信息
auth_type PASS:定義認證類型為密碼auth_pass 123456:定義具體的密碼virtual_ipaddress:定義虛擬IP(VIP),需要為同一網段下的IP,并且每個節點需要一致完成以上配置后,啟動keepalived服務:
[root@Haproxy-Master ~]# systemctl start keepalived當keepalived服務啟動成功,使用ip addr命令可以查看到網卡綁定的虛擬IP: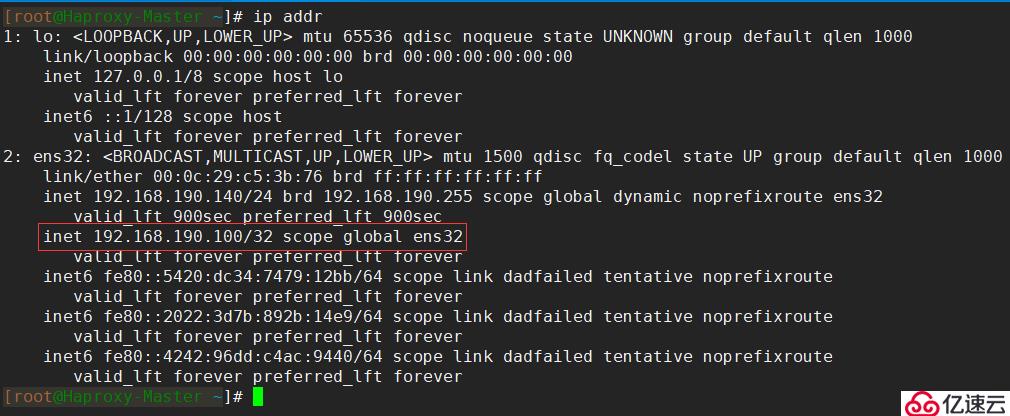
另一個節點也是使用以上的步驟進行安裝和配置,這里就不再重復了。
以上我們完成了Keepalived的安裝與配置,最后我們來測試Keepalived服務是否正常可用,以及測試Haproxy是否已具有高可用性。
首先,在其他節點上測試虛擬IP能否正常ping通,如果不能ping通就需要檢查配置了。如圖,我這里是能正常ping通的: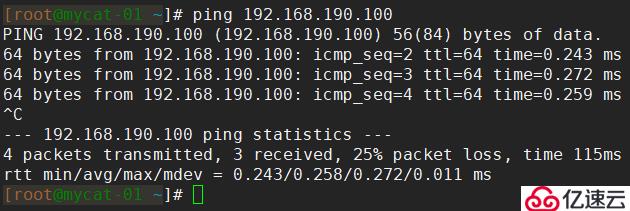
常見的虛擬IP ping不通的情況:
確認能夠從外部ping通Keepalived的虛擬IP后,使用Navicat測試能否通過虛擬IP連接到Mycat: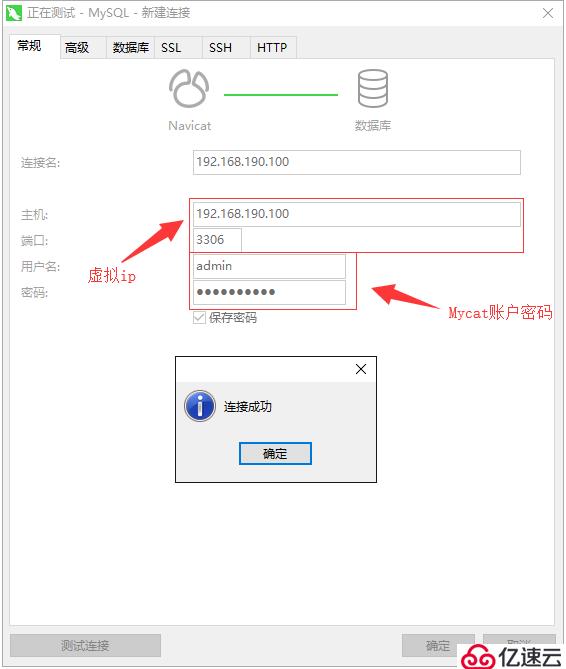
連接成功后,執行一些語句測試能否正常插入、查詢數據: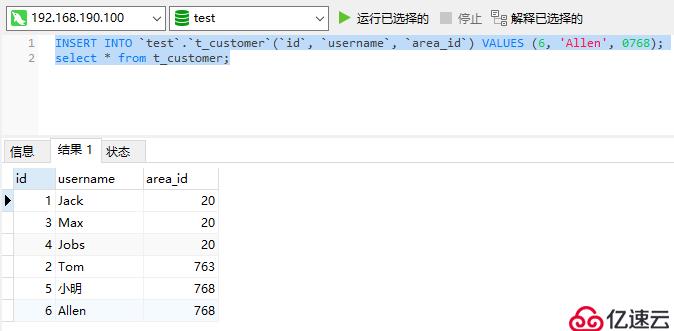
到此就基本沒什么問題了,最后測試一下Haproxy的高可用性,將其中一個Haproxy節點上的keepalived服務給關掉:
[root@Haproxy-Master ~]# systemctl stop keepalived然后再次執行執行一些語句測試能否正常插入、查詢數據,如下能正常執行代表Haproxy節點已具有高可用性: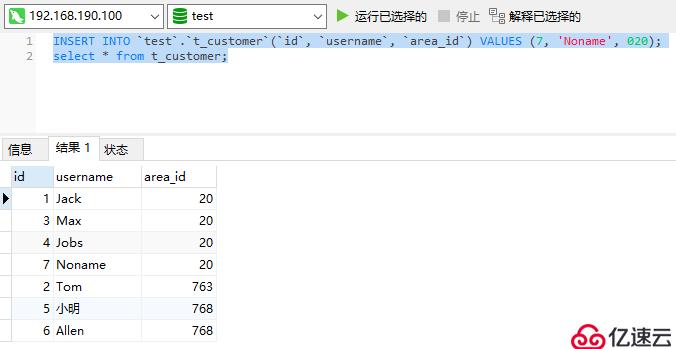
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





