溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文研究的主要是Python爬蟲天氣預報的相關內容,具體介紹如下。
這次要爬的站點是這個:http://www.weather.com.cn/forecast/
要求是把你所在城市過去一年的歷史數據爬出來。
分析網站
首先來到目標數據的網頁 http://www.weather.com.cn/weather40d/101280701.shtml
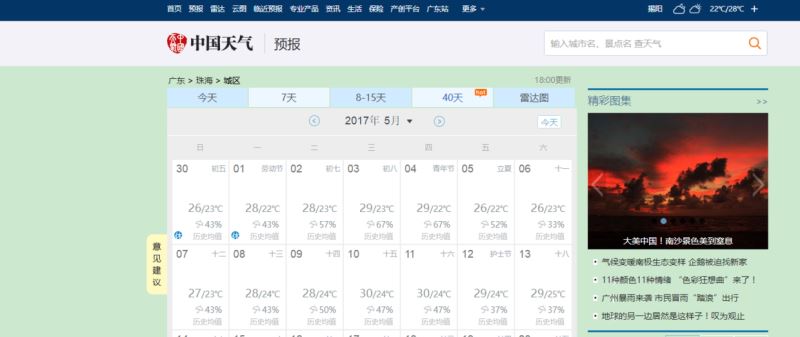
我們可以看到,我們需要的天氣數據都是放在圖表上的,在切換月份的時候,發現只有部分頁面刷新了,就是天氣數據的那塊,而URL沒有變化。
這是因為網頁前端使用了JS異步加載的技術,更新時不用加載整個頁面,從而提升了網頁的加載速度。
對于這種非靜態頁面,我們在請求數據時,就不能簡單的通過替換URL來請求不同的頁面。
著眼點要放在Network,觀察整個請求的過程,從中尋找突破口。
老規矩按下F12 > network,切換下頁面,發現多了一些東西,這就是切換月份,瀏覽器發出的請求,可以很清楚的看到請求頭和請求參數。
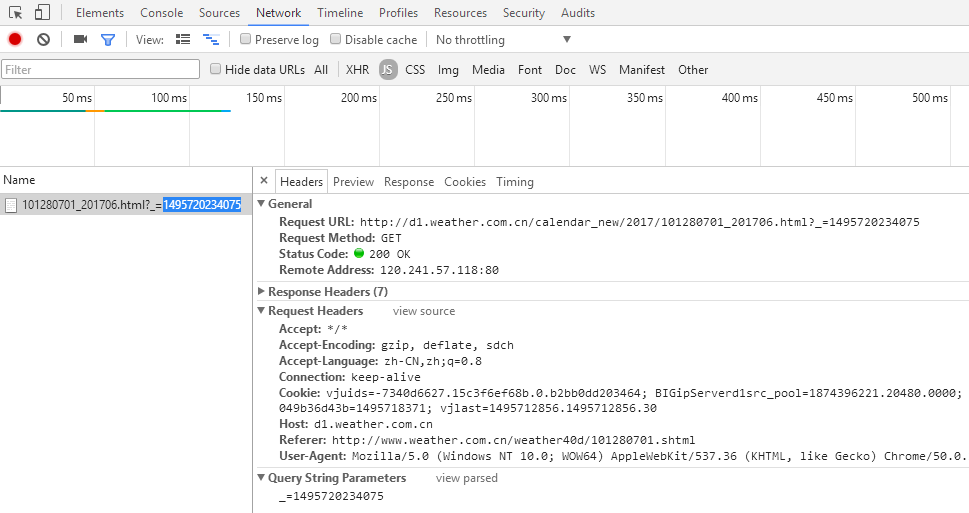
再來看看Response是怎樣的吧

真是沒想到,返回的居然是json格式的天氣數據!直接做 json 反序化就能變成字典的形式,省掉了我們解析 html 的麻煩呀。既然找到了數據所在的地方,就可以開始嘗試構建請求了。
構建請求
先直接copy上面的Request URL,試下請求。http://d1.weather.com.cn/calendar_new/2017/101280701_201706.html?_=1495720234075
然后發現報錯了,先把請求頭全部滿上懟進去,發現可以正常的響應。
但是我們還要分析下到底哪個參數不對出了問題。經過嘗試,發現請求頭里的Referer的原因,去掉就會報錯。
這是因為這是瀏覽器發出請求時,會通過Referer告訴服務器我是從哪個頁面鏈接過來的,有些網站會對這個做驗證,主要時為了防止別人盜鏈的問題。
這個中國天氣網,就是驗證了Referer里的域名是不是自己的,不是的話就會403禁止訪問服務器。
接下來就要考慮怎么請求不同月份的數據。
通過觀察URL,發現其實很簡單,直接替換年月,就可以循環抓取,得到整年的數據。
那中間的101280701是什么意思呢,經過請求不同的城市對比URL,我發現這是表示地理位置的一個數據。
前3位表示國家中國,后6位依次表示,省份,城市和區縣。修改這里,就能實現對不同城市進行查詢了。
最后一個參數1495720234075,開始以為是隨機數,后來有朋友提醒這是unix時間戳,實際上就算去掉這個,也能正常訪問數據,沒什么影響。
解析數據
拿到數據以后,就可以開始解析了。不過這里根本用不上xpath,直接用Json.load(),就能反序列化成json對象,從中取出字典,節省很多麻煩。需要注意的是,返回的40天的天氣數據 fc40 字符串是這樣
var fc40 = [{"blue":"","c1":"","c2":"","cla":"history","date":"20151227","des":"歷史均值","fe":"","hgl":"17%","hmax":"17","hmin":"13","hol":"","jq":""
.....]}
前面的字符串需要去掉,才能反序列化,注意這里的json對象實際是個存儲字典的list[]。開始想用正則,不過不熟沒弄好。后來發現 python 字符串也能使用這樣的語法 [a:b] 來取出位置a到位置b的字符串,所以就直接用[11 : ], 就能取出fc40 后面的字符串,也很方便。
保存數據
因為數據量比較大,就采用mongodb來做數據持久化。mongodb 我也是才學習,參考了別人的教程,才做好了環境配置,過程打算總結到另一篇,這里就打算不多說了。
因為原本的放了天氣數據的字典里面有太多沒用的數據,我只想提取出我想要的部分,就用了一個小技巧。
將想要的數據的key,保存成subkey這個字典,用 for in取出subkey中的key,再回到原本的dict中取出對應的值,最后將這些鍵值對,都存儲在一個subdict字典里,就完成了提取出子字典的功能。說起來很麻煩,但是代碼卻很簡單,這可能就是python的魅力吧。
subkey = {'date', 'hmax', 'hmin', 'hgl', 'fe', 'wk', 'time'}
subdict = {key: dict[key] for key in subkey}
然后我還做了個用中文替換的原來key的功能,只需要稍作修改,for in 取出來的是鍵值對,然后用中文的value,替換英文的key,就ok了。
subkey = {'date': '日期', 'hmax': '最高溫度', 'hmin': '最低溫度', 'hgl':
'降水概率', 'fe': '節日', 'wk': '星期'}
subdict = {value: dict[key] for key, value in subkey.items()}
最后的結果如下圖,這是用pycharm上的mongodb可視化插件Mongo Plugin看到的,在pycharm>settings>plugins里面可以搜索安裝。需要注意的是,默認只顯示300條數據。想要看到更多,就在Row limit 上輸入總數就行。
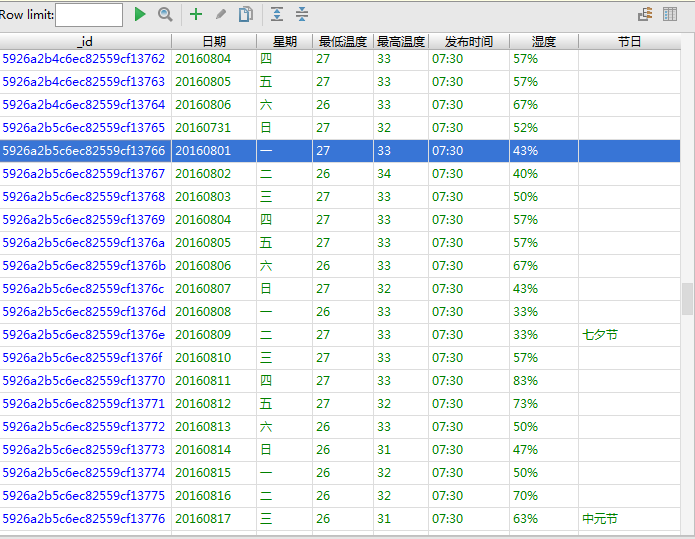
Python的代碼非常短才30多行,就完成了爬蟲的整個流程, 請求,解析,保存,一氣呵成,可謂是爬蟲界的豪杰。
# encoding=utf-8
import requests
import json
import pymongo
import time
def request(year, month):
url = "http://d1.weather.com.cn/calendar_new/" + year + "/101280701_" + year + month + ".html?_=1495685758174"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36",
"Referer": "http://www.weather.com.cn/weather40d/101280701.shtml",
}
return requests.get(url, headers=headers)
def parse(res):
json_str = res.content.decode(encoding='utf-8')[11:]
return json.loads(json_str)
def save(list):
subkey = {'date': '日期', 'hmax': '最高溫度', 'hmin': '最低溫度', 'hgl': '降水概率', 'fe': '節日', 'wk': '星期', 'time': '發布時間'}
for dict in list:
subdict = {value: dict[key] for key, value in subkey.items()} #提取原字典中部分鍵值對,并替換key為中文
forecast.insert_one(subdict) #插入mongodb數據庫
if __name__ == '__main__':
year = "2016"
month = 1
client = pymongo.MongoClient('localhost', 27017) # 連接mongodb,端口27017
test = client['test'] # 創建數據庫文件test
forecast = test['forecast'] # 創建表forecast
for i in range(month, 13):
month = str(i) if i > 9 else "0" + str(i) #小于10的月份要補0
save(parse(request(year, month)))
time.sleep(1)
總結
以上就是本文關于Python爬蟲天氣預報實例詳解(小白入門)的全部內容,希望對大家有所幫助。感興趣的朋友可以繼續參閱本站其他相關專題,如有不足之處,歡迎留言指出。感謝朋友們對本站的支持!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





