溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關python正則的常用方法有哪些的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
1.正則的簡單介紹
首先你得導入正則方法 import re正則表達式是用于處理字符串的強大工具,擁有自己獨立的處理機制,效率上可能不如str自帶的方法,但功能十分靈活給力。它的運行過程是先定一個匹配規則("你想要的內容+正則語法規則"),放入要匹配的字符串,通過正則內部的機制就能檢索你想要的信息。
2.findall的常用幾種姿勢
基本結構大致: nojoke = re.findall(r'匹配的規則','要檢索的愿字符串') nojoke就是我們最后通過正則返回的結果,re正則findall查找全部r標識代表后面是正則的語句(這樣在代碼多的時候好查閱),下面我們看看幾個例子好深入了解
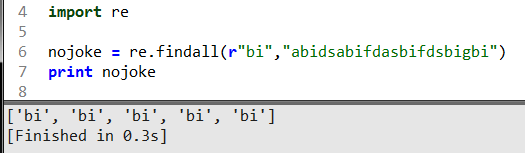
這段代碼是找出檢索字符串中所有的bi并以列表的形式返回,這個會經常用到計算統一字符出現的次數。繼續看下一個
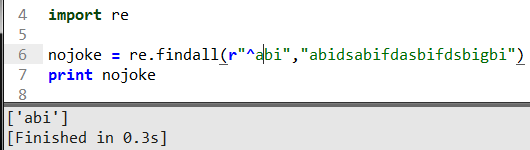
這里加了個符號^表示匹配以abi開頭的的字符串返回,也可以判斷字符串是否以abi開始的。
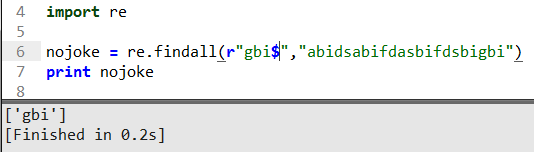
這里在的用$符號表示以gbi結尾的字符串返回,判斷是否字符串結束的字符串。
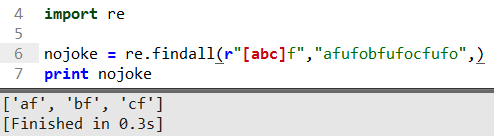
這里[...]的意思匹配括號內a和f,或者b和f,或者c和f的值返回列表。
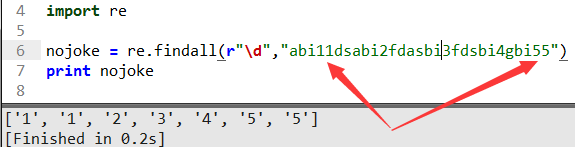
“\d”是正則語法規則用來匹配0到9之間的數返回列表,需要注意的是11會當成字符串'1'和'1'返回而不是返回'11'這個字符串,切記用不好這里是大坑。
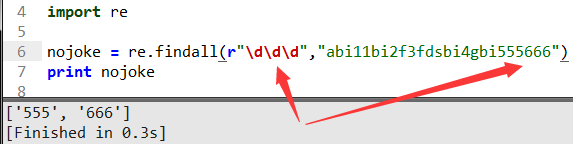
當然解決的辦法就你要取幾位數就寫幾個\d,上面這里演示取字符串中3位數字,這里展現了正則靈活一方面。
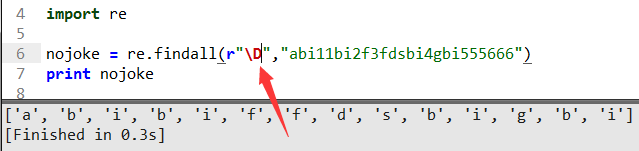
這里小d表示取數字0-9,大D表示不要數字,也就是出了數字以外的內容返回。
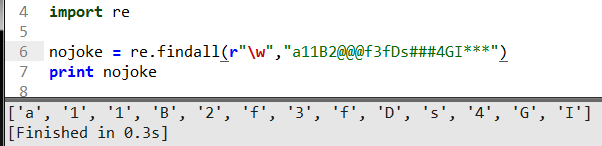
“\w”在正則里面代表匹配從小寫a到z,大寫A到Z,數字0到9包含前面這三種的如上面打印的一樣.

"\W"在正則里面代表匹配除了字母與數字以外的特殊符號,但這里\斜杠的用法要注意在字符串\是轉義符號具體百度去學。
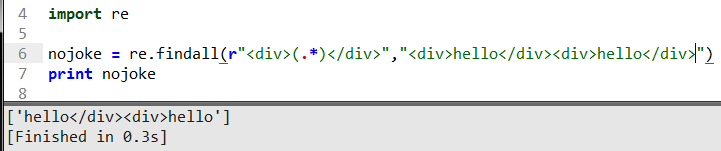
這里括號()的用法表示匹配是取括號內里面的內容,這里.*是正則貪婪匹配語法百話點就是貪心利益最大話最大范圍的匹配準則如上圖所示。
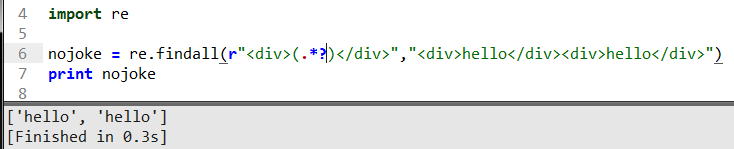
這里加了個問號.*?就是限制它不讓他最大范圍的匹配也叫非貪婪模式匹配。結果是把兩個div內的內容匹配返回。
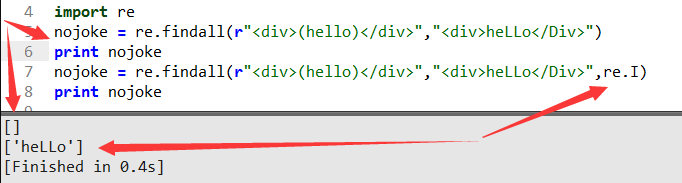
這里加re.I(大寫的i)表示匹配無論公的母的大小寫都通吃都要,不然后面有大小寫就會出現上面匹配找不到返回空列表給你。
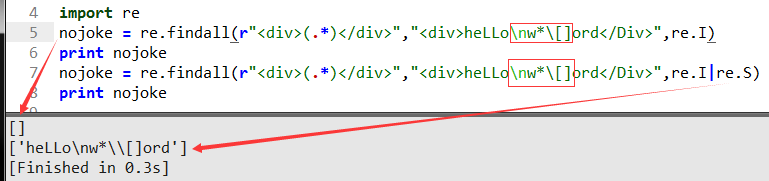
這里又搞事了就是\n俗稱換行符,一旦換行程序就SB了不認了,所以我們加上了re.S(大寫)這樣代表比匹配包括換行在內的所有字符內容返回,基本你把上面的語法和用法學會后基本70%以上匹配方法全都搞定,當然還有很方法我就不列舉了,大家可以自己去學習(剩下的基本我都很少用到了)。
2.match和search的用法及區別:
re.match 嘗試從字符串的起始位置匹配一個模式,如果不是起始位置匹配成功的話,match()就返回none。re.search 掃描整個字符串并返回第一個成功的匹配。來看看代碼就容易理解了。如下:
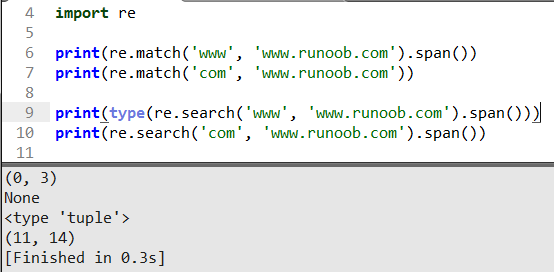
這里直接打印結尾加上.span()可以得到匹配字符串的位置以元組tuple返回(起始位置,結束位置),有一個沒寫,因為他返回空加上會編譯器報錯。
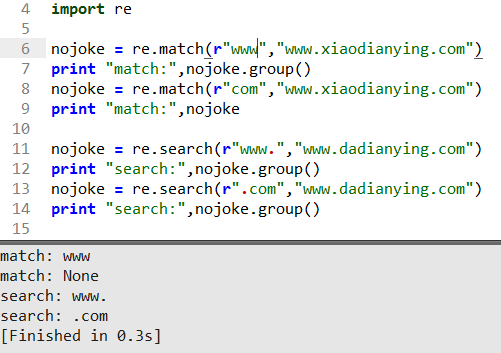
是不是一目了然,match只會開頭匹配,找不到就返回None,這里我沒加.group()是因為返回值是空值我加了編譯器會報錯,search不挑食掃描整個字符串,當然里面也可以用上面的正則方法去匹配,這里就不過多介紹了大家可以動手練練。
3.sub替換的用法
sub用于替換字符串中的匹配項,語法一般是re.sub(r'正則匹配規則','替換的字符串',需要檢索的字符串)
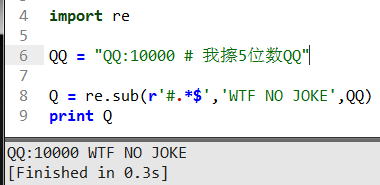
這里很直觀的反應了結果,把#號及后面的字符串替換想要改的字符串。
4.最后福利
在給最后福利之前,希望大家能多練練上面的用法和使用規則,只有多出錯多總結才會積累經驗,最后的福利講給大家幾個常用的郵箱匹配規則如下:
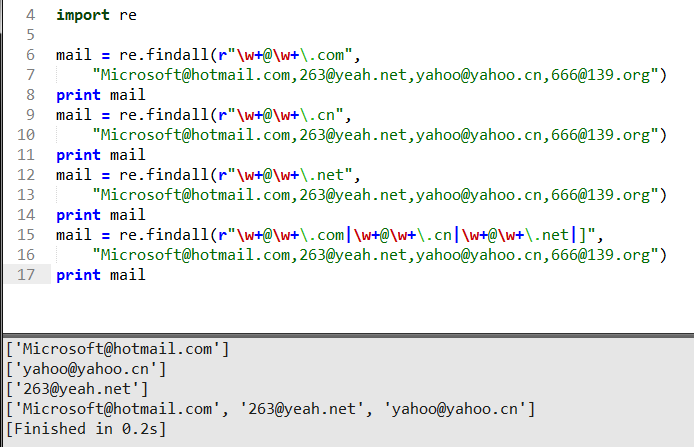
感謝各位的閱讀!關于“python正則的常用方法有哪些”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





