溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一個禮拜前一個同學問我這個事情,由于之前在參加華為的比賽,所以賽后看了一下,據說需要用到pdfminer這個包。于是安裝了一下,安裝過程很簡單:
sudo pip install pdfminer;
中間也沒有任何的報錯。至于如何調用,本人也沒有很好的研究過pdfminer這個庫,于是開始了百度……
官方文檔:http://www.unixuser.org/~euske/python/pdfminer/index.html
完全使用python編寫。 (適用于2.4或更新版本)
解析,分析,并轉換成PDF文檔。
PDF-1.7規范的支持。 (幾乎)
中日韓語言和垂直書寫腳本支持。
各種字體類型(Type1、TrueType、Type3,和CID)的支持。
基本加密(RC4)的支持。
PDF與HTML轉換。
綱要(TOC)的提取。
標簽內容提取。
通過分組文本塊重建原始的布局。
一些基本的類
PDFParser:從一個文件中獲取數據
PDFDocument:保存獲取的數據,和PDFParser是相互關聯的
PDFPageInterpreter處理頁面內容
PDFDevice將其翻譯成你需要的格式
PDFResourceManager用于存儲共享資源,如字體或圖像。
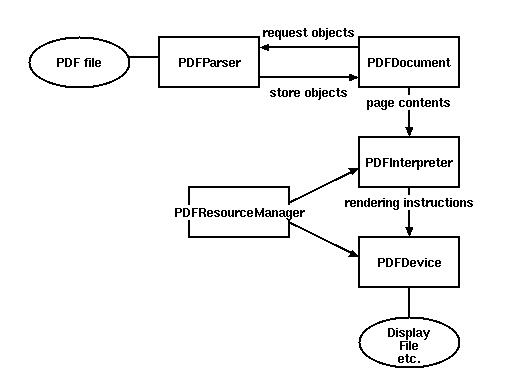
簡單的實現
讀取test.pdf輸出為output.txt:
# -*- coding: utf-8 -*-
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
from pdfminer.layout import *
from pdfminer.converter import PDFPageAggregator
import os
fp = open('test.pdf', 'rb')
#來創建一個pdf文檔分析器
parser = PDFParser(fp)
#創建一個PDF文檔對象存儲文檔結構
document = PDFDocument(parser)
# 檢查文件是否允許文本提取
if not document.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 創建一個PDF資源管理器對象來存儲共賞資源
rsrcmgr=PDFResourceManager()
# 設定參數進行分析
laparams=LAParams()
# 創建一個PDF設備對象
# device=PDFDevice(rsrcmgr)
device=PDFPageAggregator(rsrcmgr,laparams=laparams)
# 創建一個PDF解釋器對象
interpreter=PDFPageInterpreter(rsrcmgr,device)
# 處理每一頁
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
# 接受該頁面的LTPage對象
layout=device.get_result()
for x in layout:
if(isinstance(x,LTTextBoxHorizontal)):
with open('output.txt','a') as f:
f.write(x.get_text().encode('utf-8')+'\n')
以上這篇利用python將pdf輸出為txt的實例講解就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





