溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“Python如何利用scrapy爬蟲通過短短50行代碼下載整站短視頻”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“Python如何利用scrapy爬蟲通過短短50行代碼下載整站短視頻”這篇文章吧。
一、撕開爬蟲的面紗——爬蟲是什么,它能做什么
爬蟲是什么
爬蟲就是一段能夠從互聯網上高效獲取數據的程序。
我們每天都在從互聯網上獲取數據。當打開瀏覽器訪問百度的時候,我們就從百度的服務器獲取數據,當拿起手機在線聽歌的時候,我們就從某個app的服務器上獲取數據。簡單的歸納,這些過程都可以描述為:我們提交一個Request請求,服務器會返回一個Response數據,應用根據Response來渲染頁面,給我們展示數據結果。
爬蟲最核心的也是這個過程,提交Requests——〉接受Response。就這樣,很簡單,當我們在瀏覽器里打開一個頁面,看到頁面內容的時候,我們就可以說這個頁面被我們采集到了。
只不過當我們真正進行數據爬取時,一般會需要采集大量的頁面,這就需要提交許多的Requests,需要接受許多的Response。數量大了之后,就會涉及到一些比較復雜的處理,比如并發的,比如請求序列,比如去重,比如鏈接跟蹤,比如數據存儲,等等。于是,隨著問題的延伸和擴展,爬蟲就成為了一個相對獨立的技術門類。
但它的本質就是對一系列網絡請求和網絡響應的處理。
爬蟲能做什么
爬蟲的作用和目的只有一個,獲取網絡數據。我們知道,互聯網是個數據的海洋,大量的信息漂浮在其中,想把這些資源收歸己用,爬蟲是最常用的方式。特別是最近幾年大樹據挖掘技術和機器學習以及知識圖譜等技術的興盛,更是對數據提出了更大的需求。另外也有很多互聯網創業公司,在起步初期自身積累數據較少的時候,也會通過爬蟲快速獲取數據起步。
二、python爬蟲框架scrapy——爬蟲開發的利器
如果你剛剛接觸爬蟲的概念,我建議你暫時不要使用scrapy框架。或者更寬泛的說,如果你剛剛接觸某一個技術門類,我都不建議你直接使用框架,因為框架是對許多基礎技術細節的高級抽象,如果你不了解底層實現原理就直接用框架多半會讓你云里霧里迷迷糊糊。
在入門爬蟲之初,看scrapy的文檔,你會覺得“太復雜了”。當你使用urllib或者Requests開發一個python的爬蟲腳本,并逐個去解決了請求頭封裝、訪問并發、隊列去重、數據清洗等等問題之后,再回過頭來學習scrapy,你會覺得它如此簡潔優美,它能節省你大量的時間,它會為一些常見的問題提供成熟的解決方案。
scrapy數據流程圖
這張圖是對scrapy框架的經典描述,一時看不懂沒有關系,用一段時間再回來看。或者把本文讀完再回來看。
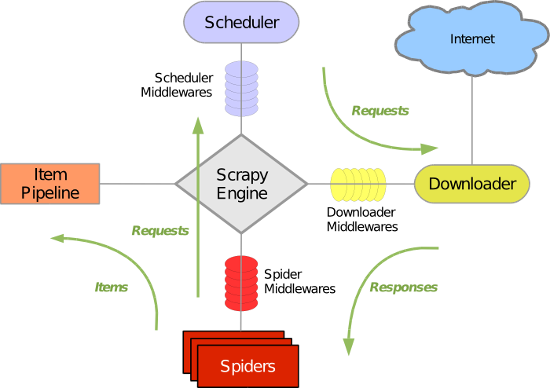
在一些書上會把爬蟲的基本抓取流程概括為UR 2 IM,意思是數據爬取的過程是圍繞URL、Request(請求)、Response(響應)、Item(數據項)、MoreUrl(更多的Url)展開的。上圖的 綠色箭頭 體現的正是這幾個要素的流轉過程。圖中涉及的四個模塊正是用于處理這幾類對象的:
Spider模塊:負責生成Request對象、解析Response對象、輸出Item對象
Scheduler模塊:負責對Request對象的調度
Downloader模塊:負責發送Request請求,接收Response響應
ItemPipleline模塊:負責數據的處理
scrapy Engine負責模塊間的通信
各個模塊和scrapy引擎之間可以添加一層或多層中間件,負責對出入該模塊的UR 2 IM對象進行處理。
scrapy的安裝
參考官方文檔,不再贅述。官方文檔:https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/install.html
三、scrapy實戰:50行代碼爬取全站短視頻
python的優雅之處在于能夠讓開發者專注于業務邏輯,花更少的時間在枯燥的代碼編寫調試上。scrapy無疑完美詮釋了這一精神。
開發爬蟲的一般步驟是:
確定要爬取的數據(item)
找到數據所在頁面的url
找到頁面間的鏈接關系,確定如何跟蹤(follow)頁面
那么,我們一步一步來。
既然是使用scrapy框架,我們先創建項目:
scrapy startproject DFVideo
緊接著,我們創建一個爬蟲:
scrapy genspider -t crawl DfVideoSpider eastday.com
這是我們發現在當前目錄下已經自動生成了一個目錄:DFVideo
目錄下包括如圖文件:
spiders文件夾下,自動生成了名為DfVideoSpider.py的文件。

爬蟲項目創建之后,我們來確定需要爬取的數據。在items.py中編輯:
import scrapy class DfvideoItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() video_url = scrapy.Field()#視頻源url video_title = scrapy.Field()#視頻標題 video_local_path = scrapy.Field()#視頻本地存儲路徑
接下來,我們需要確定視頻源的url,這是很關鍵的一步。
現在許多的視頻播放頁面是把視頻鏈接隱藏起來的,這就使得大家無法通過右鍵另存為,防止了視頻別隨意下載。
但是只要視頻在頁面上播放了,那么必然是要和視頻源產生數據交互的,所以只要稍微抓下包就能夠發現玄機。
這里我們使用fiddler抓包分析。
發現其視頻播放頁的鏈接類似于:video.eastday.com/a/180926221513827264568.html?index3lbt
視頻源的數據鏈接類似于:mvpc.eastday.com/vyule/20180415/20180415213714776507147_1_06400360.mp4
有了這兩個鏈接,工作就完成了大半:
在DfVideoSpider.py中編輯
# -*- coding: utf-8 -*-
import scrapy
from scrapy.loader import ItemLoader
from scrapy.loader.processors import MapCompose,Join
from DFVideo.items import DfvideoItem
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
import time
from os import path
import os
class DfvideospiderSpider(CrawlSpider):
name = 'DfVideoSpider'
allowed_domains = ['eastday.com']
start_urls = ['http://video.eastday.com/']
rules = (
Rule(LinkExtractor(allow=r'video.eastday.com/a/\d+.html'),
callback='parse_item', follow=True),
)
def parse_item(self, response):
item = DfvideoItem()
try:
item["video_url"] = response.xpath('//input[@id="mp4Source"]/@value').extract()[0]
item["video_title"] = response.xpath('//meta[@name="description"]/@content').extract()[0]
#print(item)
item["video_url"] = 'http:' + item['video_url']
yield scrapy.Request(url=item['video_url'], meta=item, callback=self.parse_video)
except:
pass
def parse_video(self, response):
i = response.meta
file_name = Join()([i['video_title'], '.mp4'])
base_dir = path.join(path.curdir, 'VideoDownload')
video_local_path = path.join(base_dir, file_name.replace('?', ''))
i['video_local_path'] = video_local_path
if not os.path.exists(base_dir):
os.mkdir(base_dir)
with open(video_local_path, "wb") as f:
f.write(response.body)
yield i至此,一個簡單但強大的爬蟲便完成了。
如果你希望將視頻的附加數據保存在數據庫,可以在pipeline.py中進行相應的操作,比如存入mongodb中:
from scrapy import log
import pymongo
class DfvideoPipeline(object):
def __init__(self):
self.mongodb = pymongo.MongoClient(host='127.0.0.1', port=27017)
self.db = self.mongodb["DongFang"]
self.feed_set = self.db["video"]
# self.comment_set=self.db[comment_set]
self.feed_set.create_index("video_title", unique=1)
# self.comment_set.create_index(comment_index,unique=1)
def process_item(self, item, spider):
try:
self.feed_set.update({"video_title": item["video_title"]}, item, upsert=True)
except:
log.msg(message="dup key: {}".format(item["video_title"]), level=log.INFO)
return item
def on_close(self):
self.mongodb.close()當然,你需要在setting.py中將pipelines打開:
ITEM_PIPELINES = {
'TouTiaoVideo.pipelines.ToutiaovideoPipeline': 300,
}以上是“Python如何利用scrapy爬蟲通過短短50行代碼下載整站短視頻”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





