溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Python3爬取英雄聯盟英雄皮膚大圖的示例分析,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
爬蟲思路
初步嘗試
我先查看了network,并沒有發現有可用的API;然后又用bs4去分析英雄列表頁,但是請求到html里面,并沒有英雄列表,在英雄列表的節點上,只有“正在加載中”這樣的字樣;同樣的方法,分析英雄詳情也是這種情況,所以我猜測,這些數據應該是Javascript負責加載的。
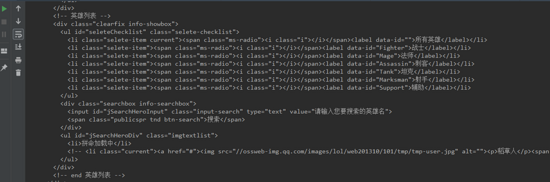
繼續嘗試
然后我就查看了 英雄列表的源代碼 ,查看外部引入的js文件,以及行內的js腳本,大概在368行,發現了有處理英雄列表的js注釋,然后繼續往下讀這些代碼,發現了第一個彩蛋,也就是他引入了一個champion.js的文件,我猜測,這個應該就是英雄列表大全了,然后我打開了這個鏈接的js,一眼看過去,黑麻麻一片,然后格式化了一下壓縮的js,確定這就是英雄列表的js數據文件了。
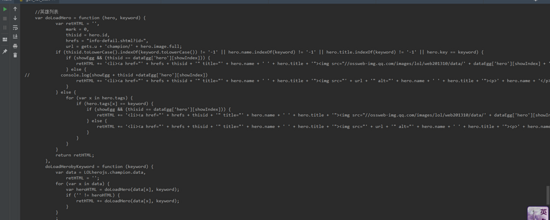
接著嘗試
前面通過查看列表的源代碼,找到了英雄列表的js數據文件,那么,我繼續隨機點開了一個英雄的詳情,然后查看 英雄詳情源代碼 ,然后大概在568行看到有一個showSkin的js方法,通過這里,發現了第二個彩蛋,也就是皮膚圖片的URL地址拼接方法。

最后嘗試
上面找到了皮膚圖片URL的拼接方法,并且發現了一行很關鍵的代碼 var skin =LOLherojs.champion[heroid].data.skins ,也就是,這個skin變量,就是英雄皮膚的所有圖片數組,但是這個文件內,并沒有LOLherojs這個變量,也就是外部引入的,所以,需要繼續查看下面的源代碼,找到引入這個變量的位置,果不其然,在757行,發現了最后一個彩蛋,也就是,英雄皮膚的js文件,通過這里可以知道,每個英雄都有一個單獨的js文件,并且知道了這個js文件的URL拼接方法。
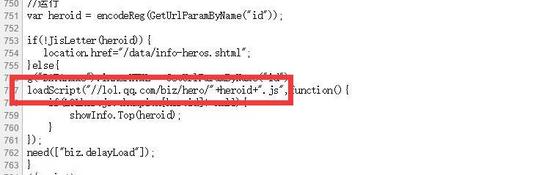
思路總結
通過上面的分析,我們就得到了爬取LOL皮膚圖片的所有數據準備了,也就是,直接,只需要提取js中的英雄列表以及英雄詳情數據,就可實現我們的需求了。下面是運行后抓取到的圖片……

運行環境
Python運行環境:python3.6
用到的模塊:requests、json、urllib、os
未安裝的模塊,請使用pip instatll進行安裝,例如:pip install requests
完整代碼
其他啥的廢話就不多說了,直接上完整代碼,有問題,直接留言給我就行,另外,代碼已上傳 GitHub 。再說明一下,那些有問題的英雄詳情的js文件,大家有時間也可以琢磨下,或者有其他的更加快捷的爬取這些圖片的方法,也可以拿出來交流和討論,謝謝。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
抓取英雄聯盟英雄全皮膚
author: gxcuizy
date: 2018-11-13
"""
import requests
import json
from urllib import parse
import os
class GetLolSkin(object):
"""抓取LOL英雄皮膚"""
def __init__(self):
"""初始化變量"""
self.hero_url = 'https://lol.qq.com/biz/hero/champion.js'
self.hero_detail_url = 'http://lol.qq.com/biz/hero/'
self.skin_folder = 'skin'
self.skin_url = 'https://ossweb-img.qq.com/images/lol/web201310/skin/big'
@staticmethod
def get_html(url):
"""下載html"""
request = requests.get(url)
request.encoding = 'gbk'
if request.status_code == 200:
return request.text
else:
return "{}"
def get_hero_list(self):
"""獲取英雄的完整信息列表"""
hero_js = self.get_html(self.hero_url)
# 刪除左右的多余信息,得到json數據
out_left = "if(!LOLherojs)var LOLherojs={};LOLherojs.champion="
out_right = ';'
hero_list = hero_js.replace(out_left, '').rstrip(out_right)
return json.loads(hero_list)
def get_hero_info(self, hero_id):
"""獲取英雄的詳細信息"""
# 獲取js詳情
detail_url = parse.urljoin(self.hero_detail_url, hero_id + '.js')
detail_js = self.get_html(detail_url)
# 刪除左右的多余信息,得到json數據
out_left = "if(!herojs)var herojs={champion:{}};herojs['champion'][%s]=" % hero_id
out_right = ';'
hero_info = detail_js.replace(out_left, '').rstrip(out_right)
return json.loads(hero_info)
def download_skin_list(self, skin_list, hero_name):
"""下載皮膚列表"""
# 循環下載皮膚
for skin_info in skin_list:
# 拼接圖片名字
if skin_info['name'] == 'default':
skin_name = '默認皮膚'
else:
if ' ' in skin_info['name']:
name_info = skin_info['name'].split(' ')
skin_name = name_info[0]
else:
skin_name = skin_info['name']
hero_skin_name = hero_name + '-' + skin_name + '.jpg'
self.download_skin(skin_info['id'], hero_skin_name)
def download_skin(self, skin_id, skin_name):
"""下載皮膚圖片"""
# 下載圖片
img_url = self.skin_url + skin_id + '.jpg'
request = requests.get(img_url)
if request.status_code == 200:
print('downloading……%s' % skin_name)
img_path = os.path.join(self.skin_folder, skin_name)
with open(img_path, 'wb') as img:
img.write(request.content)
else:
print('img error!')
def make_folder(self):
"""初始化,創建圖片文件夾"""
if not os.path.exists(self.skin_folder):
os.mkdir(self.skin_folder)
def run(self):
# 獲取英雄列表信息
hero_json = self.get_hero_list()
hero_keys = hero_json['keys']
# 循環遍歷英雄
for hero_id, hero_code in hero_keys.items():
hero_name = hero_json['data'][hero_code]['name']
hero_info = self.get_hero_info(hero_id)
if hero_info:
skin_list = hero_info['result'][hero_id]['skins']
# 下載皮膚
self.download_skin_list(skin_list, hero_name)
else:
print('英雄【%s】的皮膚獲取有問題……' % hero_name)
# 程序執行入口
if __name__ == '__main__':
lol = GetLolSkin()
# 創建圖片存儲文件
lol.make_folder()
# 執行腳本
lol.run()以上是“Python3爬取英雄聯盟英雄皮膚大圖的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





