溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關node.js怎么爬取中關村的在線電瓶車信息的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
步驟
第一步,引入需要的庫
var cheerio = require('cheerio');
var fetch = require('node-fetch');
// cheerio 是一個類似瀏覽器端的jQuery,用來解析HTML的
// fetch 用來發送請求第二步,設置初始的爬取的入口(我身處杭州,所以地區選了杭州的?)
// 初始url var url = "http://detail.zol.com.cn/convenienttravel/hangzhou/#list_merchant_loc" // 由于每個a標簽下是相對路徑,故需要一個根地址來拼接,如下 var urlRoot = "http://detail.zol.com.cn" // 存放所有url,之所以用set,是為了防止有相同的而重復爬去 var urls = new Set() // 存儲所有數據 var data = []
至此,我們的準備部分結束了?,接下來,開始表演了
分析網頁,思考爬取的方式
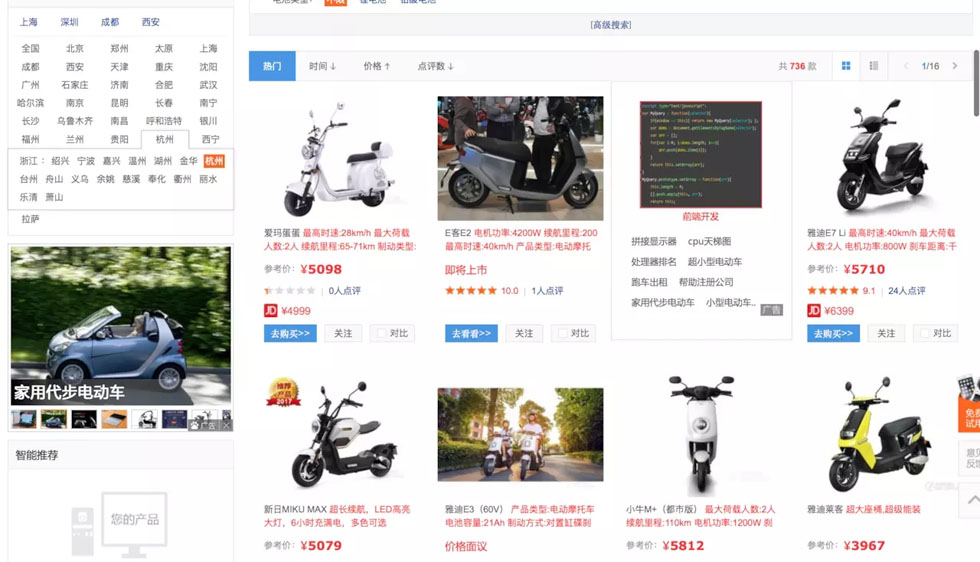
每行4款,每頁是48款,一共16頁
思路:
每次獲取當前頁48個鏈接,并點進去之后,拿到該電瓶車的名稱和價格(其他信息獲取方式一樣,自行改就好?)
第一頁的全部完成之后,翻到下一頁,繼續爬,直到最后一頁結束
首先我們定義一個函數如下
// 這是得到每個頁面的48個鏈接,并開始發送請求
function ad(arg){
// 參數 arg 先不管
// 本地化一下需要爬取的鏈接
let url2 = arg || url;
// 請求第一頁該網頁,拿到數據之后,復制給 app
var app = await fetch(url2).then(res=>res.text())
// 然后假裝用jQuery解析了
var $ = cheerio.load(app)
// 獲取當前頁所有電瓶車的a標簽
var ele = $("#J_PicMode a.pic")
// 存放已經爬取過的url,防止重復爬取
var old_urls = []
var urlapp = []
//拿到所有a標簽地址之后,存在數組里面,等會兒要開始爬的
for (let i = 0; i < ele.length; i++) {
old_urls.push(fetch(urlRoot+$(ele[i]).attr('href')).then(res=>res.text()))
}
// 用把URL一塊丟給promise處理
urlapp = await Promise.all(old_urls)
// 處理完成之后,循環加入jQuery?
for (let i = 0; i < urlapp.length; i++) {
let $2 = cheerio.load(urlapp[i],{decodeEntities: false})
data.push({
name:$2(".product-model__name").text(),
price:$2(".price-type").text()
})
}
// 至此,一頁的數據就爬完了
// console.log(data);
// 然后開始爬取下一頁
var nextURL = $(".next").attr('href')
// 判斷當前頁是不是最后一頁
if (nextURL){
let next = await fetch(urlRoot+nextURL).then(res=>res.text())
// 獲取下一頁的標簽,拿到地址,走你
ad(urlRoot+nextURL)
}
return data
}
ad()完整代碼如下
var cheerio = require('cheerio');
var fetch = require('node-fetch');
var url = "http://detail.zol.com.cn/convenienttravel/hangzhou/#list_merchant_loc"
var urlRoot = "http://detail.zol.com.cn"
// var url = "http://localhost:3222/app1"
var urls = new Set()
var data = []
async function ad(arg){
let url2 = arg || url;
var app = await fetch(url2).then(res=>res.text())
var $ = cheerio.load(app)
var ele = $("#J_PicMode a.pic")
var old_urls = []
var urlapp = []
for (let i = 0; i < ele.length; i++) {
old_urls.push(fetch(urlRoot+$(ele[i]).attr('href')).then(res=>res.text()))
}
urlapp = await Promise.all(old_urls)
for (let i = 0; i < urlapp.length; i++) {
let $2 = cheerio.load(urlapp[i],{decodeEntities: false})
data.push({
name:$2(".product-model__name").text(),
price:$2(".price-type").text()
})
}
var nextURL = $(".next").attr('href')
if (nextURL){
let next = await fetch(urlRoot+nextURL).then(res=>res.text())
ad(urlRoot+nextURL)
}
return data
}
ad()感謝各位的閱讀!關于“node.js怎么爬取中關村的在線電瓶車信息”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





