溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了如何使用MySQL系統數據庫做性能負載診斷,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
某大師曾說過,像了解自己的老婆 一樣了解自己管理的數據庫,個人認為包含了兩個方面的了解:
1,在穩定性層面來說,更多的是關注高可用、讀寫分離、負載均衡,災備管理等等high level層面的措施(就好比要保證生活的穩定性)
2,在實例級別的來說,需要關注內存、IO、網絡,熱點表,熱點索引,top sql,死鎖,阻塞,歷史上執行異常的SQL(好比生活品質細節)MySQL的performance_data庫和sys庫提供了非常豐富的系統日志數據,可以幫助我們更好地了解非常細節的,這里簡單地列舉出來了一些常用的數據。
sys庫是以較為可讀化的方式封裝了performance_data中的某些表,因此這些個數據來源還是performance_data庫中的數據。
這里粗略列舉出個人常用的一些系統數據,可以在實例級別更加清楚地了解MySQL的運行過程中資源分配情況。
Status中的信息
MySQL的status變量只是給出了一個總的信息,從status變量上無法得知詳細資源的消耗,比如IO或者內存的熱點在哪里,庫、表的熱點在哪里,如果想要知道具體的明細信息就需要系統庫中的數據。
前提要開啟performance_schema,因為sys庫的視圖是基于performance_schema的庫的。
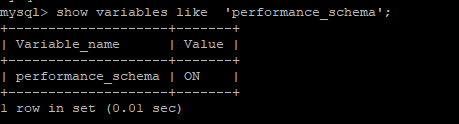
內存使用:
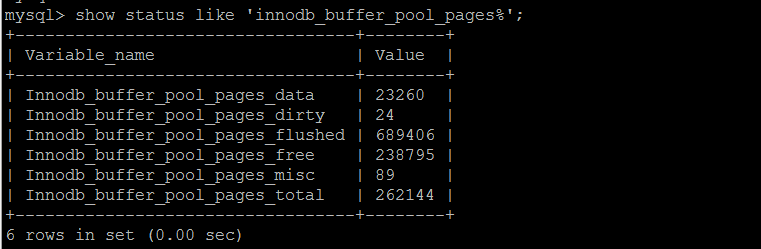
內存/innodb_buffer_pool使用
概要innodb_buffer_pool的使用情況summary,已知當前實例262144*16/1024 = 4096MB buffer pool,已使用23260*16/1024 363MB
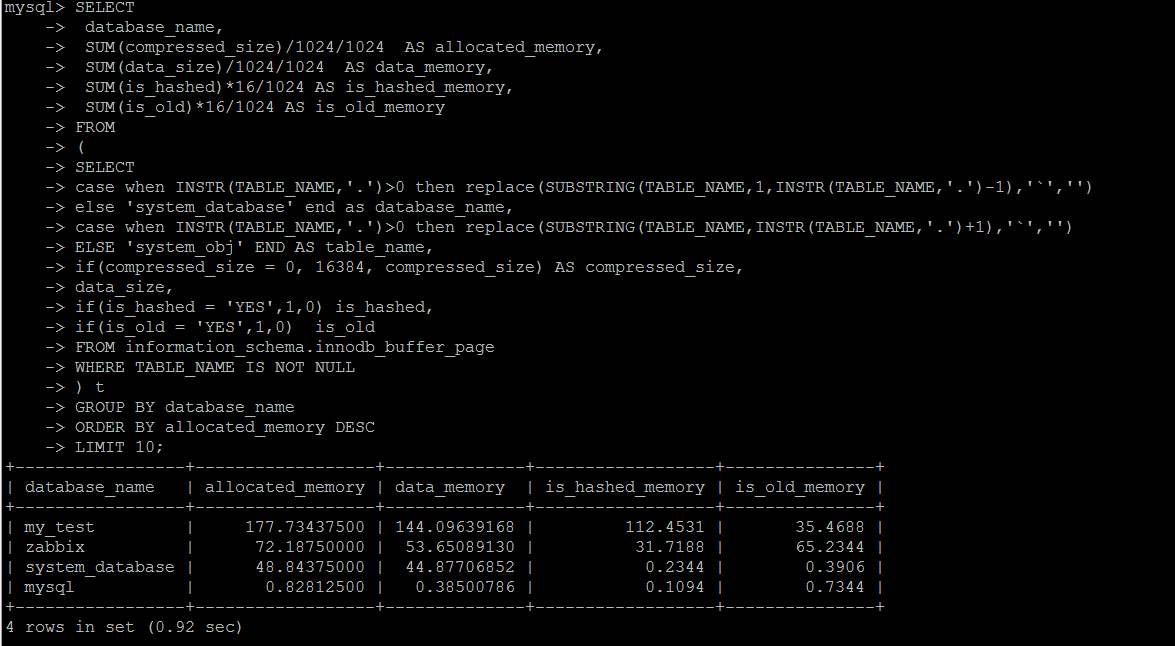
innodb_buffer_pool已占用內存的明細信息,可以按照庫\表的維度來統計
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ; SELECT database_name, SUM(compressed_size)/1024/1024 AS allocated_memory, SUM(data_size)/1024/1024 AS data_memory, SUM(is_hashed)*16/1024 AS is_hashed_memory, SUM(is_old)*16/1024 AS is_old_memory FROM ( SELECT case when INSTR(TABLE_NAME,'.')>0 then replace(SUBSTRING(TABLE_NAME,1,INSTR(TABLE_NAME,'.')-1),'`','') else 'system_database' end as database_name, case when INSTR(TABLE_NAME,'.')>0 then replace(SUBSTRING(TABLE_NAME,INSTR(TABLE_NAME,'.')+1),'`','') ELSE 'system_obj' END AS table_name, if(compressed_size = 0, 16384, compressed_size) AS compressed_size, data_size, if(is_hashed = 'YES',1,0) is_hashed, if(is_old = 'YES',1,0) is_old FROM information_schema.innodb_buffer_page WHERE TABLE_NAME IS NOT NULL ) t GROUP BY database_name ORDER BY allocated_memory DESC LIMIT 10;
庫\表的讀寫統計,邏輯層面的熱點數據統計
目標表是performance_schema.table_io_waits_summary_by_table,某些文章上說是邏輯IO,其實這里跟邏輯IO并無關系,這個表中的字段含義是基于表,讀寫的到的行數的統計。至于真正的邏輯IO層面的統計,筆者目前還有不知道有哪個可用的系統表來查詢。這個庫可以很清楚地看到這個表中的統計結果是怎么計算出來的。
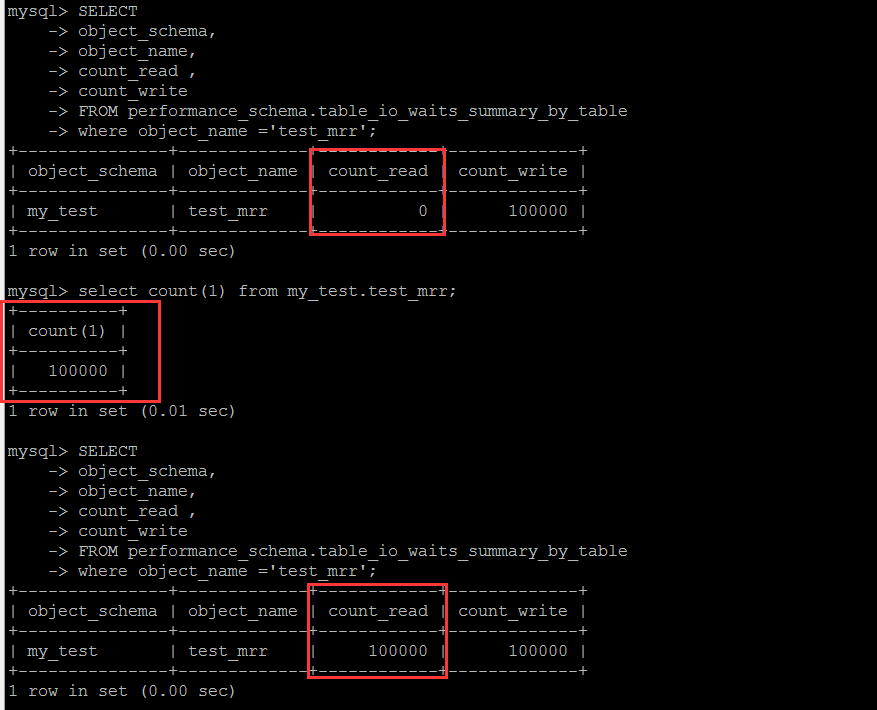
基于表的讀寫的行的次數統計,這是一個累計值,單純的看這個值本身,個人覺得意義不大,需要定時收集計算差值,才具備參考意義。
以下按照庫級別統計表的讀寫情況。
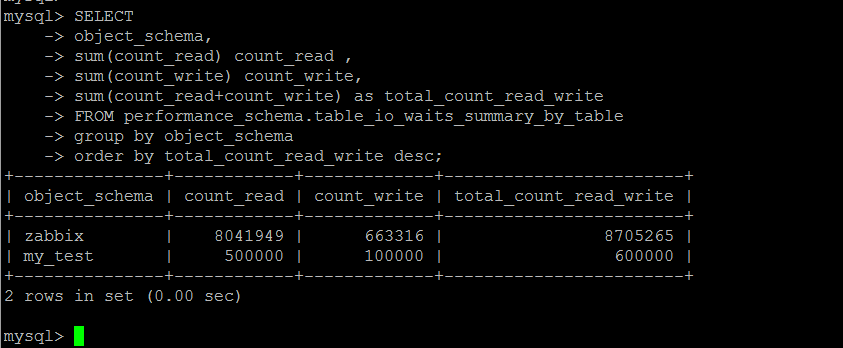
庫\表的讀寫統計,物理IO層面的熱點數據統計
按照物理IO的維度統計熱點數據,哪些庫\表消耗了多少物理IO。這里原始系統表中的數據是一個累計統計的值,最極端的情況就是一個表為0行,卻存在大量的物理讀寫IO。
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ; SELECT database_name, IFNULL(cast(sum(total_read) as signed),0) AS total_read, IFNULL(cast(sum(total_written) as signed),0) AS total_written, IFNULL(cast(sum(total) AS SIGNED),0) AS total_read_written FROM ( SELECT substring(REPLACE(file, '@@datadir/', ''),1,instr(REPLACE(file, '@@datadir/', ''),'/')-1) AS database_name, count_read, case when instr(total_read,'KiB')>0 then replace(total_read,'KiB','')/1024 when instr(total_read,'MiB')>0 then replace(total_read,'MiB','')/1024 when instr(total_read,'GiB')>0 then replace(total_read,'GiB','')*1024 END AS total_read, case when instr(total_written,'KiB')>0 then replace(total_written,'KiB','')/1024 when instr(total_written,'MiB')>0 then replace(total_written,'MiB','') when instr(total_written,'GiB')>0 then replace(total_written,'GiB','')*1024 END AS total_written, case when instr(total,'KiB')>0 then replace(total,'KiB','')/1024 when instr(total,'MiB')>0 then replace(total,'MiB','') when instr(total,'GiB')>0 then replace(total,'GiB','')*1024 END AS total from sys.io_global_by_file_by_bytes WHERE FILE LIKE '%@@datadir%' AND instr(REPLACE(file, '@@datadir/', ''),'/')>0 )t GROUP BY database_name ORDER BY total_read_written DESC;
ps:個人不太喜歡MySQL自定義的format_***函數,這個函數的初衷是好的,把一些數據(時間,存儲空間)等格式化成更加可讀的模式。但是卻不支持單位的參數,更多的時候想以某個固定的單位來顯示,比如格式化一個的時間,格式化后根據單位大小可能會顯示微妙,或者是毫秒,或者是秒,或者分鐘,或者天。比如想把時間統一格式化成秒,對不起,不支持,某些個數據不僅僅是看一眼那么簡單,甚至是要讀出來存檔分析的,因此這里不建議也不會使用那些個format函數
TOP SQL 統計
可以按照執行時間,阻塞時間,返回行數等等維度統計top sql。
另外可以按照時間篩選last_seen,可以統計最近某一段時間出現過的top sql
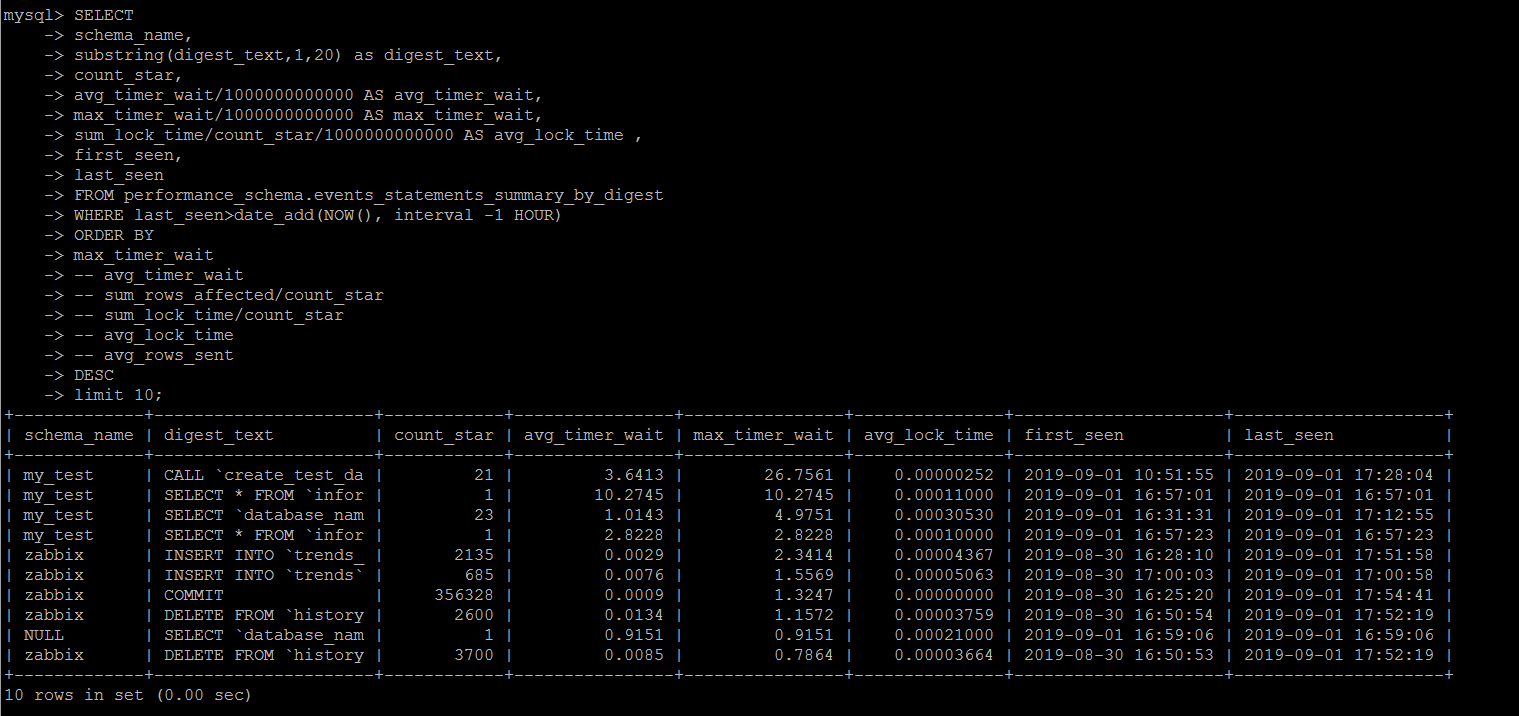
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ; SELECT schema_name, digest_text, count_star, avg_timer_wait/1000000000000 AS avg_timer_wait, max_timer_wait/1000000000000 AS max_timer_wait, sum_lock_time/count_star/1000000000000 AS avg_lock_time , sum_rows_affected/count_star AS avg_rows_affected, sum_rows_sent/count_star AS avg_rows_sent , sum_rows_examined/count_star AS avg_rows_examined, sum_created_tmp_disk_tables/count_star AS avg_create_tmp_disk_tables, sum_created_tmp_tables/count_star AS avg_create_tmp_tables, sum_select_full_join/count_star AS avg_select_full_join, sum_select_full_range_join/count_star AS avg_select_full_range_join, sum_select_range/count_star AS avg_select_range, sum_select_range_check/count_star AS avg_select_range, first_seen, last_seen FROM performance_schema.events_statements_summary_by_digest WHERE last_seen>date_add(NOW(), interval -1 HOUR) ORDER BY max_timer_wait -- avg_timer_wait -- sum_rows_affected/count_star -- sum_lock_time/count_star -- avg_lock_time -- avg_rows_sent DESC limit 10;
需要注意的是,這個統計是按照MySQL執行一個事務消耗的資源做統計的,而不是一個語句,筆者一開始懵逼了一陣子,舉個簡單的例子。
參考如下,這里是循環寫個數據的一個存儲過程,調用方式就是call create_test_data(N),寫入N條測試數據。
比如call create_test_data(1000000)就是寫入100W的測試數據,這個執行過程耗費了幾分鐘的時間,按照筆者的測試實例情況,avg_timer_wait的維度,絕對是一個TOP SQL。
但是在查詢的時候,始終沒有發現這個存儲過程的調用被列為TOP SQL,后面嘗試在存儲過程內部加了一個事物,然后就順利地收集到了整個TOP SQL.
因此說performance_schema.events_statements_summary_by_digest里面的統計,是基于事務的,而不是某一個批處理的執行時間的。
CREATE DEFINER=`root`@`%` PROCEDURE `create_test_data`( IN `loopcnt` INT ) LANGUAGE SQL NOT DETERMINISTIC CONTAINS SQL SQL SECURITY DEFINER COMMENT '' BEGIN -- START TRANSACTION; while loopcnt>0 do insert into test_mrr(rand_id,create_date) values (RAND()*100000000,now(6)); set loopcnt=loopcnt-1; end while; -- commit; END
另外一點比較有意思的是,這個系統表是為數不多的支持truncate的,當然它在內部,也是在不斷收集的一個過程。
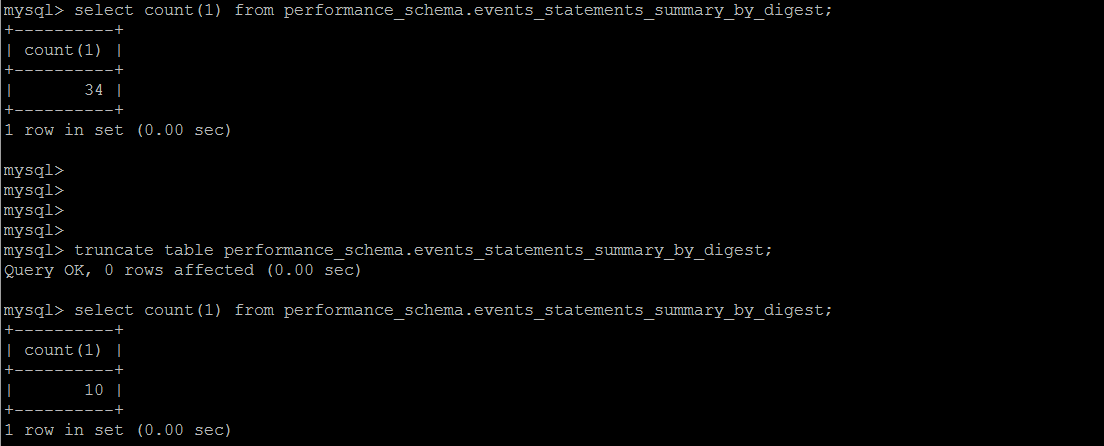
執行失敗的SQL 統計
一直以為系統不會記錄執行失敗的\解析錯誤的SQL,比如想統計因為超時而執行失敗的語句,后面才發現,這些信息,MySQL會完整地記錄下來
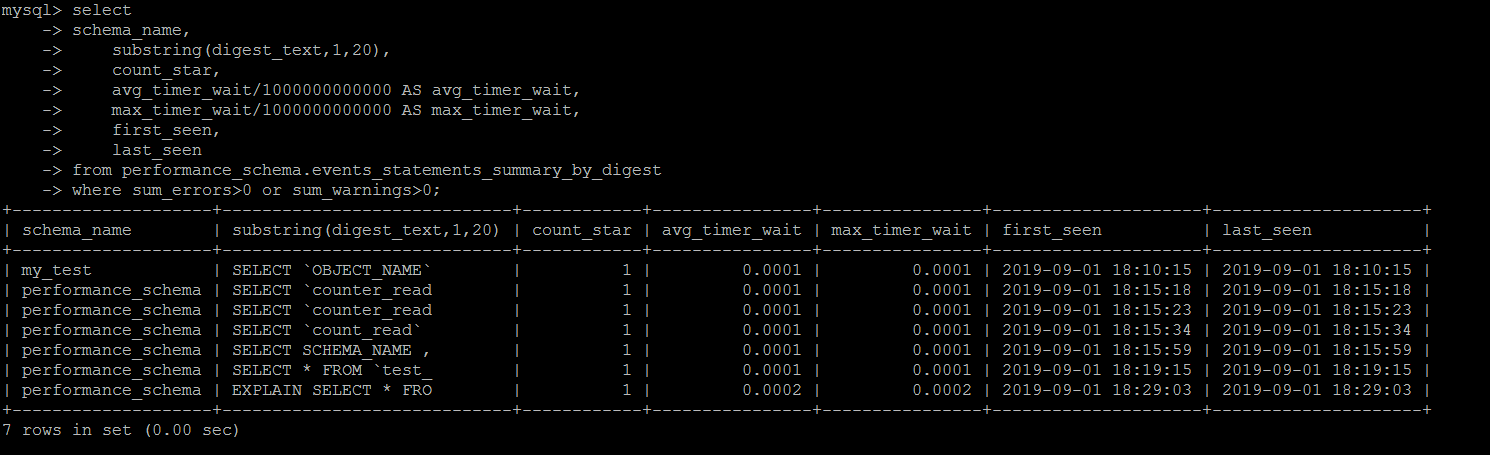
這里會詳細記錄執行錯誤的語句,包括最終執行失敗(超時之類的),語法錯誤,執行過程中產生了警告之類的語句。用sum_errors>0 or sum_warnings>0去performance_schema.events_statements_summary_by_digest篩選一下即可。
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ; select schema_name, digest_text, count_star, first_seen, last_seen from performance_schema.events_statements_summary_by_digest where sum_errors>0 or sum_warnings>0 order by last_seen desc;
Index使用情況統計
基于performance_schema.table_io_waits_summary_by_index_usage這個系統表,其統計的維度同樣是“按照某個索引查詢返回的行數的統計”。
可以按照哪些索引使用最多\最少等情況進行統計。
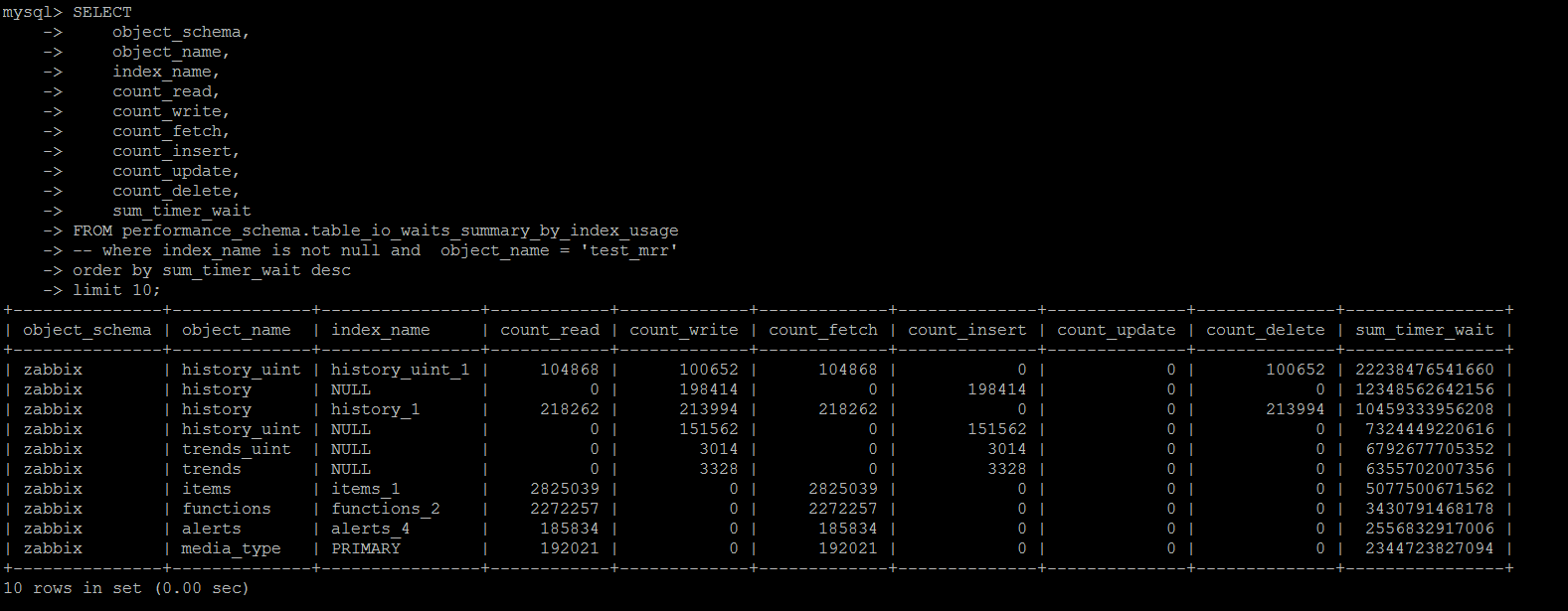
不過這個統計有一個給人潛在一個誤區:count_read,count_write,count_fetch,count_insert,count_update,count_delete統計了某個索引上使用到索引的情況下,受影響的行數,sum_timer_wait是累計在該索引上等待的時間。
如果使用到了該索引,但是沒有數據受影響(就是沒有DML語句的條件沒有命中數據),將count_***不會統計進來,但是sum_timer_wait會統計進來
這就存在一個容易受到誤導的地方,這個索引明明沒有命中過很多次,但是卻產生了大量的timer_wait,索引看到類似的信息,也不能貿然刪除索引。
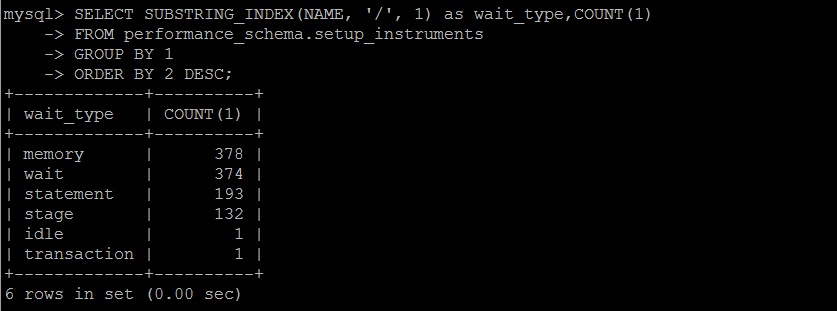
等待事件統計
MySQL數據庫中的任何一個動作,都需要等待(一定的時間來完成),一共有超過1000個等待事件,分屬不懂的類別,每個版本都不一樣,且默認不是所有的等待事件都啟用。
個人認為等待事件這個東西,僅做參考,不具備問題的診斷性,即便是再優化或者低負載的數據庫,累計一段時間,某些事件仍舊會積累大量的等待事件。
這些事件的等待事件,不一定都是負面性的,比如事物的鎖等待,是在并發執行過程中必然會生成的,這個等待事件的統計結果,也是累計的,單純的看一個直接的值,不具備任何參考意義。
除非定期收集,做差值計算,根據實際情況,才具備參考意義。
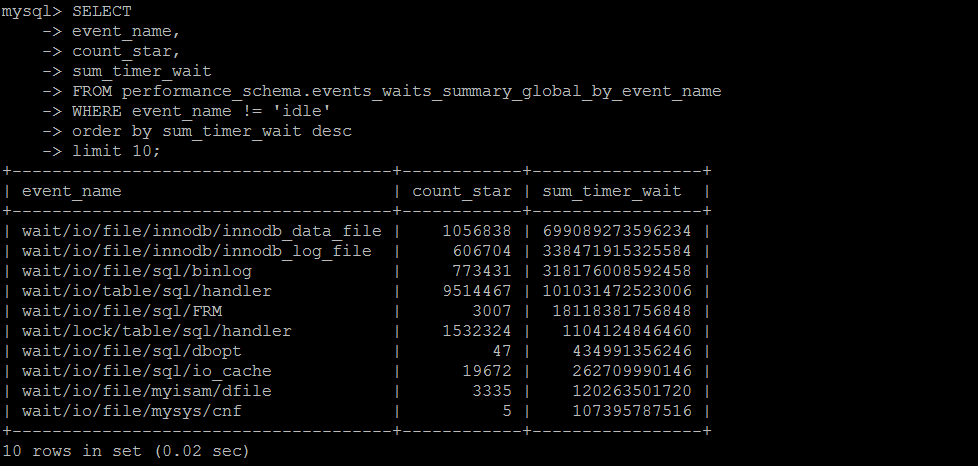
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ; SELECT SUBSTRING_INDEX(NAME, '/', 1) as wait_type,COUNT(1) FROM performance_schema.setup_instruments GROUP BY 1 ORDER BY 2 DESC; SELECT event_name, count_star, sum_timer_wait FROM performance_schema.events_waits_summary_global_by_event_name WHERE event_name != 'idle' order by sum_timer_wait desc limit 100;
最后,需要注意的是,
1,MySQL提供的諸多的系統表(視圖)中的數據,單純的看這個值本身,因為它是一個累計值,個人覺得意義不大,尤其是avg_***,需要結合多方面的綜合因素,做參考使用。
2,任何系統表的查詢,都可能對系統性能的本身造成一定的影響,不要再對系統可能產生較大負面影響的情況下做數據的統計收集。
感謝你能夠認真閱讀完這篇文章,希望小編分享的“如何使用MySQL系統數據庫做性能負載診斷”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





