溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
環境zabbix 4.0 + pgpool + postgres 11.0 cluster + Centos 7.5 +Python2.7.5【3.6】引起故障的原因,PG Master 磁盤空間150G,由于zabbix監控設備眾多(約1000個點,模板監控項也較多),導致數據庫的歸檔文件增長速度非常快,通常五分鐘左右吃掉一個G的空間。磁盤空間消耗完畢之后,pg&pgpool的服務會停止,進而影響zabbix系統的使用.為了解決這個問題,創建了bash shell 腳本和crontab 任務定時清理歸檔文件.
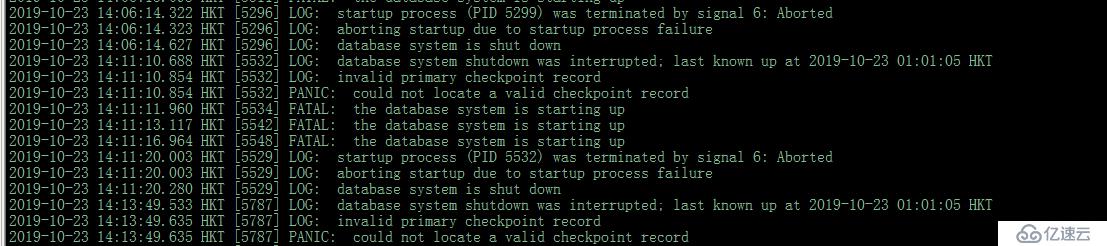
1. 登錄 postgres : docker run -ti postgres /bin/bash【不是docker環境直接跳過此步驟】
2. 切換到 postgres 用戶
3. 執行修復命令:/usr/pgsql-11/bin/pg_resetwal -f /var/lib/pgsql/11/data
【根據環境和安裝方式的不同,可能文件路徑不同,具體可以使用locate或find 命令搜索 pg_resetwal】
【pg_resetxlog -f DATADIR postgres 低于10.0 以下的版本可以使用該命令;-f 強制執行更新】
4. 如果看到“Write-ahead log reset”,表示修復成功。
# systemctl start postgresql-11.service
# systemctl status postgresql-11.service
# systemctl start pgpool-II-11.service
# systemctl status pgpool-II-11.service
# netstat -pltn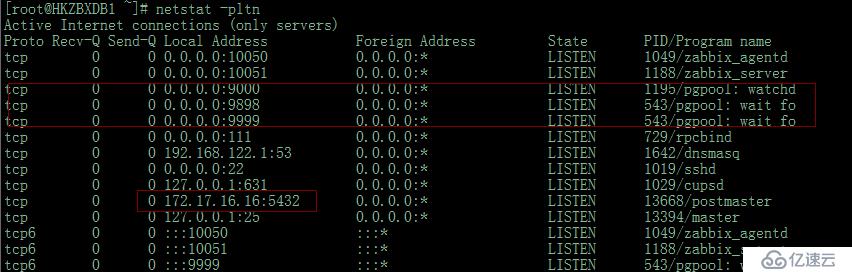
此時PG的服務起來了,但是未必數據庫可以正常使用,繼續使用命令檢查
-bash-4.2$ psql
psql: FATAL: xlog flush request 399/FCA1D7D8 is not satisfied --- flushed only to 399/E720DE18
CONTEXT: writing block 2225 of relation base/16385/17835
--此時報的這個錯誤,可以耐心等待一段時間(約十幾分吧),經驗而談pg和pgpool從故障恢復過來都要等一段時間才可正常使用;
-bash-4.2$ psql
psql (11.4)
Type "help" for help.
postgres=# 
備注:只需要點擊紅色箭頭所指“返回/斷開連接” & "重新加載“”,集群業務即可恢復使用,比命令行管理方便已維護;免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





