溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
前言
這些原則都是經歷過實戰總結而成
每一條原則背后都是血淋淋的教訓
這些原則主要是針對數據庫開發人員,在開發過程中務必注意
一、核心原則
1.盡量不在數據庫做運算
俗話說:別讓腳趾頭想事情,那是腦瓜子的職責
作為數據庫開發人員,我們應該讓數據庫多做她所擅長的事情:
舉例:
在mysql中盡量不要使用如:md5()、Order by Rand()等這類運算函數
2.盡量控制單表數據量
大家都知道單表數據量過大后會影響數據查詢效率,嚴重情況下會導致整個庫都卡住
一般情況下,按照一年內單表數據量預估:
同時要盡量做好合理的分表,使單表數據量不超載,常見的分表策略有:
分區表的適用場景主要有:
① 表非常大,無法全部存在內存,或者只在表的最后有熱點數據,其他都是歷史數據;
② 分區表的數據更易維護,可以對獨立的分區進行獨立的操作;
③ 分區表的數據可以分布在不同的機器上,從而高效使用資源;
④ 可以使用分區表來避免某些特殊的瓶頸;
⑤ 可以備份和恢復獨立的分區。
但是使用分區表同樣有一些限制,在使用的時候需要注意:
① 一個表最多只能有 1024 個分區;
② 5.1版本中,分區表表達式必須是整數, 5.5可以使用列分區;
③ 分區字段中如果有主鍵和唯一索引列,那么主鍵列和唯一列都必須包含進來;
④ 分區表中無法使用外鍵約束;
⑤ 需要對現有表的結構進行修改;
⑥ 所有分區都必須使用相同的存儲引擎;
⑦ 分區函數中可以使用的函數和表達式會有一些限制;
⑧ 某些存儲引擎不支持分區;
⑨ 對于 MyISAM 的分區表,不能使用 load index into cache;
⑩ 對于 MyISAM 表,使用分區表時需要打開更多的文件描述符。
3.盡量控制表字段數量
單表的字段數量也不能太多,根據業務場景進行優化調整,盡量調整表字段數少而精,這樣有以下好處:
那究竟單表多少字段合適呢?
按照單表1G體積,500W行數據量進行評估:
==>建議單表字段數上限控制在20~50個
4.平衡范式與冗余
數據庫表結構的設計也講究平衡,以往我們經常說要嚴格遵循三大范式,所以先來說說什么是范式:
第一范式:單個字段不可再分。唯一性。
第二范式:不存在非主屬性只依賴部分主鍵。消除不完全依賴。
第三范式:消除傳遞依賴。
用一句話來總結范式和冗余:
冗余是以存儲換取性能,
范式是以性能換取存儲。
所以,一般在實際工作中冗余更受歡迎一些。
模型設計時,這兩方面的具體的權衡,首先要以企業提供的計算能力和存儲資源為基礎。
其次,一般互聯網行業中都根據Kimball模式實施數據倉庫,建模也是以任務驅動的,因此冗余和范式的權衡符合任務需要。
例如,一份指標數據,必須在早上8點之前處理完成,但計算的時間窗口又很小,要盡可能減少指標的計算耗時,這時在計算過程中要盡可能減少多表關聯,模型設計時需要做更多的冗余。
5.拒絕3B
數據庫的并發就像城市交通,呈非線性增長
這就要求我們在做數據庫開發的時候一定要注意高并發下的瓶頸,防止因高并發造成數據庫癱瘓。
這里的拒絕3B是指:
二、字段類原則
1.用好數值字段類型
三類數值類型:
以幾個常見的例子來進行說明:
1)INT(1) VS INT(11)
很多人都分不清INT(1)和INT(11)的區別,想必大家也很好奇吧,其實1和11其實只是顯示長度的卻別而已,也就是不管int(x)x的值是什么值,存儲數字的取值范圍還是int本身數據類型的取值范圍,x只是數據顯示的長度而已。
2)BIGINT AUTO_INCREMENT
大家都知道,有符號int最大可以支持到約22億,遠遠大于我們的需求和MySQL單表所能支持的性能上限。對于OLTP應用來說,單表的規模一般要保持在千萬級別,不會達到22億上限。如果要加大預留量,可以把主鍵改為改為無符號int,上限為42億,這個預留量已經是非常的充足了。
使用bigint,會占用更大的磁盤和內存空間,內存空間畢竟有限,無效的占用會導致更多的數據換入換出,額外增加了IO的壓力,對性能是不利的。
因此推薦自增主鍵使用int unsigned類型,但不建議使用bigint。
3)DECIMAL(N,0)
當采用DECIMAL數據類型的時候,一般小數位數不會是0,如果小數位數設置為0,那建議使用INT類型
2.將字符轉化為數字
數字型VS字符串型索引有更多優勢:
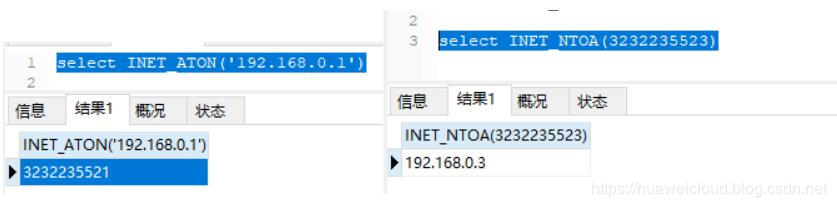
舉例:用無符號INT存儲IP,而非CHAR(15)
INT UNSIGNED
可以用INET_ATON()和INET_NTOA()來實現IP字符串和數值之間的轉換
3.優先使用ENUM或SET
對于一些枚舉型數據,我們推薦優先使用ENUM或SET,這樣的場景適合:
1)字符串型
2)可能值已知且有限
存儲方面:
1)ENUM占用1字節,轉為數值運算
2)SET視節點定,最多占用8字節
3)比較時需要加‘單引號(即使是數值)
舉例:
`sex` enum('F','M') COMMENT '性別';
`c1` enum('0','1','2','3') COMMENT '審核';
4.避免使用NULL字段
為什么在數據庫表字段設計的時候盡量都加上NOT NULL DEFAULT '',這里面不得不說用NULL字段的弊端:
很難進行查詢優化
NULL列加索引,需要額外空間
含NULL復合索引無效
舉例:
1)`a` char(32) DEFAULT NULL 【不推薦】
2)`b` int(10) NOT NULL 【不推薦】
3)`c` int(10) NOT NULL DEFAULT 0 【推薦】
5.少用并拆分TEXT/BLOB
TEXT類型處理性能遠低于VARCHAR
盡量不用TEXT/BLOB數據類型
如果業務需要必須用,建議拆分到單獨的表
舉例:
CREATE TABLE t1 ( id INT NOT NULL AUTO_INCREMENT, data TEXT NOT NULL, PRIMARY KEY(id) ) ENGINE=InnoDB;
6.不在數據庫里存圖片
先上圖:
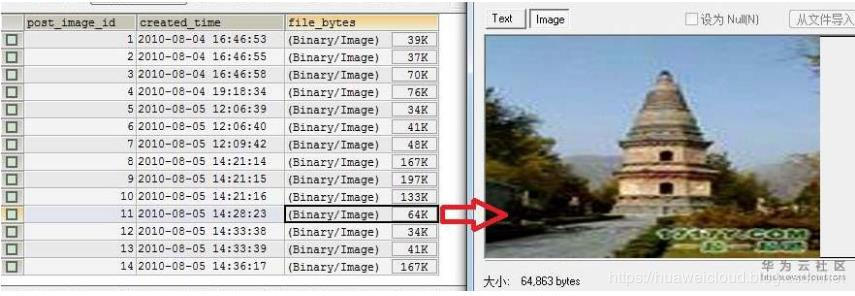
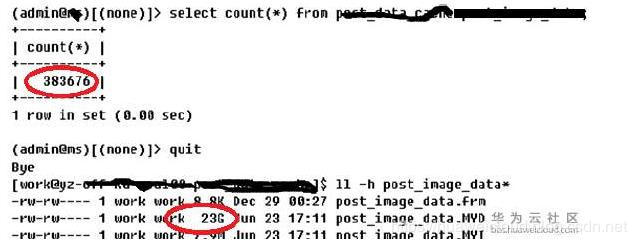
可見,如果將圖片全部存在數據庫,將使得數據庫體積變大,會造成讀寫速度變慢。
圖片存數據庫的弊端:
★推薦處理辦法:數據庫中保存圖片路徑
按照年月日生成路徑。具體是按照年月日還是按照年月去生成路徑,根據自己需要(不一定是按照日期去生成)。
理解為什么要分散到多個文件夾中去才是關鍵,涉及到一個原理就明白了:
操作系統對單個目錄的文件數量是有限制的。當文件數量很多的時候。從目錄中獲取文件的速度就會越來越慢。所以為了保持速度,才要按照固定規則去分散到多個目錄中去。
圖片分散到磁盤路徑中去。數據庫字段中保存的是類似于這樣子的”images/2012/09/25/ 1343287394783.jpg”
原來上傳的圖片文件名稱會重新命名保存,比如按照時間戳來生成,1343287394783. jpg。這樣子是為了避免文件名重復,多個人往同一個目錄上傳圖片的時候會出現。
反正用什么樣的規則命名圖片,只要做到圖片名稱的唯一性即可。
比如網站的并發訪問量大,目錄的生成分得月細越好。比如精確到小時,一個小時都可以是一個文件夾。同時0.001秒有兩個用戶同時在上傳圖片(因為那么就會往同一個小時文件夾里面存圖片)。因為時間戳是精確到秒的。為了做到圖片名稱唯一性而不至于覆蓋,生成可以在在時間戳后面繼續加毫秒微秒等。總結的規律是,并發訪問量越大。就越精確就好了。
題外話:
1)為什么保存的磁盤路徑,是”images/2012/09/25/1343287394783.jpg”,而不是” /images/2012/09/25/ 1343287394783.jpg”(最前面帶有斜杠)
在頁面中需要取出圖片路徑展示圖片的時候,如果是相對路徑,則可以使用”./”+”images/2012/09/25/1343287394783.jpg”進行組裝。
如果需要單獨的域名(比如做cdn加速的時候)域名,img1.xxx.com,img2.xxx.com這樣的域名,
直接組裝 “http://img1.xxx.com/”+”images/2012/09/25/1343287394783.jpg”
2)為什么保存的磁盤路徑,是”images/2012/09/25/1343287394783.jpg”,而不是“http://www.xxx.com/images/2012/09/25/1343287394783.jpg"
這里其實涉及到CDN的知識,具體CDN的知識在此不多展開,簡而言之:
cdn服務:對于靜態內容是非常適合的。所以像商品圖片,隨著訪問量大了后,租用cdn服務,只需要把圖片上傳到他們的服務器上去。
例子:北京訪問長沙服務器,距離太遠。我完全可以把商品圖片,放到北京的云服務(我覺得現在提供給網站使用的云存儲其實就是cdn,給網站提供分流和就近訪問)上去。這樣子北京用戶訪問的時候,實際上圖片就是就近獲取。不需要很長距離的傳輸。
自己用一個域名img.xxx.com來載入圖片。這個域名解析到北京的云服務上去。
做法:數據庫中保存的是” images/2012/09/25/1343287394783.jpg”,
這些圖片實際上不存儲在web服務器上。上傳到北京的cdn服務器上去。
我從數據庫取出來,直接”img.xxx.com/”+” images/2012/09/25/1343287394783.jpg”
比如如果還有多個,就命名img1.xx.com、img2.xx.com
反正可以隨便。所以如果把域名直接保存進去。就顯得很麻煩了。遷移麻煩。
三、索引類原則
1.謹慎合理添加索引
舉例:不要給“性別”列創建索引
理論文章會告訴你值重復率高的字段不適合建索引。不要說性別字段只有兩個值,網友親測,一個字段使用拼音首字母做值,共有26種可能,加上索引后,百萬加的數據量,使用索引的速度比不使用索引要慢!
為什么性別不適合建索引呢?因為你訪問索引需要付出額外的IO開銷,你從索引中拿到的只是地址,要想真正訪問到數據還是要對表進行一次IO。假如你要從表的100萬行數據中取幾個數據,那么利用索引迅速定位,訪問索引的這IO開銷就非常值了。但如果你是從100萬行數據中取50萬行數據,就比如性別字段,那你相對需要訪問50萬次索引,再訪問50萬次表,加起來的開銷并不會比直接對表進行一次完整掃描小。
2.字符字段必須建前綴索引
區分度:
單字母區分度:26
4字母區分度:26*26*26*26 = 456,976
5字母區分度:26*26*26*26*26 = 11,881,376
6字母區分度:26*26*26*26*26*26 = 308,915,776
字符字段必須建前綴索引,例如:
`pinyin` varchar(100) DEFAULT NULL COMMENT '小區拼音', KEY `idx_pinyin` (`pinyin`(8)), ) ENGINE=InnoDB
3.不在索引列做運算
原因有兩點:
1)會導致無法使用索引
2)會導致全表掃描
舉例:

BAD SAMPLE:
select * from table WHERE to_days(current_date) – to_days(date_col) <= 10
GOOD SAMPLE:
select * from table
WHERE date_col >= DATE_SUB('2011-10-22',INTERVAL 10 DAY);
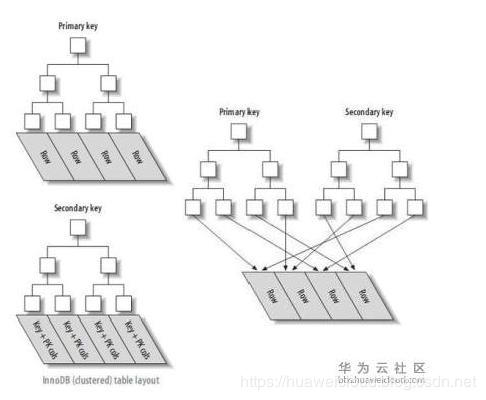
4.自增列或全局ID做INNODB主鍵
5.盡量不用外鍵
建議由程序保證約束
比如我們原來建表語句是這樣的:
CREATE TABLE `user` ( `user_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主鍵', `user_name` varchar(50) NOT NULL DEFAULT '' COMMENT '用戶名', PRIMARY KEY (`user_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `order` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主鍵', `total_price` decimal(10,2) NOT NULL DEFAULT '0.00', `user_id` int(11) NOT NULL DEFAULT '0', PRIMARY KEY (`id`), KEY `for_indx_user_id` (`user_id`), CONSTRAINT `for_indx_user_id` FOREIGN KEY (`user_id`) REFERENCES `user` (`user_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
不使用外鍵約束后:
CREATE TABLE `user` ( `user_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主鍵', `user_name` varchar(50) NOT NULL DEFAULT '' COMMENT '用戶名', PRIMARY KEY (`user_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `order` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主鍵', `total_price` decimal(10,2) NOT NULL DEFAULT '0.00', `user_id` int(11) NOT NULL DEFAULT '0', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
不適用外鍵約束后,為了加快查詢我們通常會給不建立外鍵約束的字段添加一個索引。
CREATE TABLE `order` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主鍵', `total_price` decimal(10,2) NOT NULL DEFAULT '0.00', `user_id` int(11) NOT NULL DEFAULT '0', PRIMARY KEY (`id`), KEY `idx_user_id` (`user_id`), ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
實際開發中,一般不會建立外鍵約束。
四、SQL類原則
1.SQL語句盡可能簡單
在開發過程中,我們盡量要保持SQL語句的簡單性,我們對比一下大SQL和多個簡單SQL
拒絕大SQL,拆解成多條簡單SQL
2.保持事務(連接)短小
舉例:
1)發帖時的圖片上傳等待
2)大量的sleep連接
3.盡可能避免使用SP/TRIG/FUNC
線上OLTP系統中,我們應當:
將上述這些事情都交給客戶端程序負責
4.盡量不用SELECT *
用SELECT * 時,將會更多的消耗CPU、內存、IO以及網絡帶寬
我們在寫查詢語句時,應當盡量不用SELECT * ,只取需要的數據列:
舉例:
不推薦:
SELECT * FROM tag WHERE id = 999148
推薦:
SELECT keyword FROM tag WHERE id = 999148
5.改寫OR為IN()
同一字段,將or改寫為in()
OR效率:O(n)
IN效率:O(Log n)
當n很大時,OR會慢很多
注意控制IN的個數,建議n小于200
舉例:
不推薦:
Select * from opp WHERE phone='12347856' or phone='42242233'
推薦:
Select * from opp WHERE phone in ('12347856' , '42242233')
6.改寫OR為UNION
不同字段,將or改為union
舉例:
不推薦:
Select * from opp WHERE phone='010-88886666' or cellPhone='13800138000';
推薦:
Select * from opp WHERE phone='010-88886666' union Select * from opp WHERE cellPhone='13800138000';
7.避免負向查詢和%前綴模糊查詢
在實際開發中,我們要盡量避免負向查詢,那什么是負向查詢呢,主要有以下:
NOT、!=、<>、!<、!>、NOT EXISTS、NOT IN、NOT LIKE等
同時,我們還要避免%前綴模糊查詢,因為這樣會使用B+ Tree,同時會造成使用不了索引,并且會導致全表掃描,性能和效率可想而知
舉例:

8.減少COUNT(*)
在開發中我們經常會使用COUNT(*),殊不知這種用法會造成大量的資源浪費,因為COUNT(*)資源開銷大,所以我們能不用盡量少用
對于計數類統計,我們推薦:
來對比一下COUNT(*)和其他幾個COUNT吧:
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '公司的id', `sale_id` int(10) unsigned DEFAULT NULL,
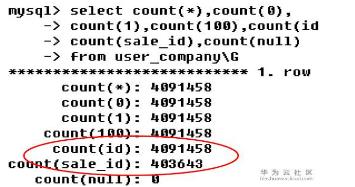
結論:
COUNT(*)=COUNT(1) COUNT(0)=COUNT(1) COUNT(1)=COUNT(100) COUNT(*)!=COUNT(col)
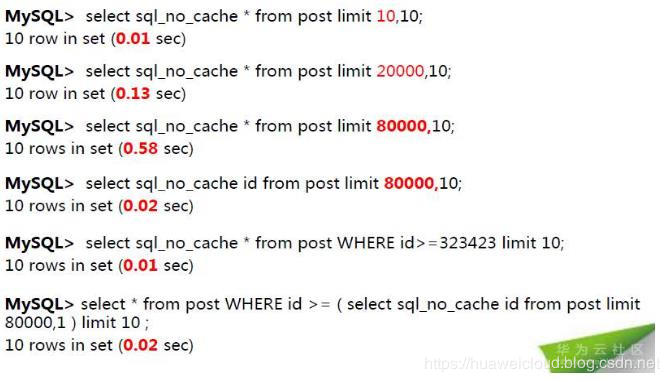
9.LIMIT高效分頁
傳統分頁:
Select * from table limit 10000,10;
LIMIT原理:
推薦分頁:
Select * from table WHERE id>=23423 limit 11; #10+1 (每頁10條) select * from table WHERE id>=23434 limit 11;
分頁方式二:
Select * from table WHERE id >= ( select id from table limit 10000,1 ) limit 10;
分頁方式三:
SELECT * FROM table INNER JOIN (SELECT id FROM table LIMIT 10000,10) USING (id) ;
分頁方式四:
#先使用程序獲取ID: select id from table limit 10000,10; #再用in獲取ID對應的記錄 Select * from table WHERE id in (123,456…) ;
具體需要根據實際的場景分析并重組索引
示例:
10.用UNION ALL 而非UNION
如果無需對結果進行去重,僅僅是對多表進行聯合查詢并展示,則用UNION ALL,因為UNION有去重開銷
舉例:
MySQL>SELECT * FROM detail20091128 UNION ALL SELECT * FROM detail20110427 UNION ALL SELECT * FROM detail20110426 UNION ALL SELECT * FROM detail20110425 UNION ALL SELECT * FROM detail20110424 UNION ALL SELECT * FROM detail20110423;
11.分解聯接保證高并發
高并發DB不建議進行兩個表以上的JOIN
適當分解聯接保證高并發:
舉例:
原SQL:
MySQL> Select * from tag JOIN tag_post on tag_post.tag_id=tag.id JOIN post on tag_post.post_id=post.id WHERE tag.tag=‘二手玩具';
分解SQL:
MySQL> Select * from tag WHERE tag=‘二手玩具'; MySQL> Select * from tag_post WHERE tag_id=1321; MySQL> Select * from post WHERE post.id in (123,456,314,141)
12.GROUP BY 去除排序
使用GROUP BY可以實現分組和自動排序
無需排序:Order by NULL
特定排序:Group by DESC/ASC
舉例:

13.同數據類型的列值比較
原則:數字對數字,字符對字符
數值列與字符類型比較:同時轉換為雙精度進行比對
字符列與數值類型比較:字符列整列轉數值,不會使用索引查詢
舉例:
字段:`remark` varchar(50) NOT NULL COMMENT '備注,默認為空',
MySQL>SELECT `id`, `gift_code` FROM gift WHERE `deal_id` = 640 AND remark=115127; 1 row in set (0.14 sec) MySQL>SELECT `id`, `gift_code` FROM pool_gift WHERE `deal_id` = 640 AND remark='115127'; 1 row in set (0.005 sec)
14.Load data 導數據
批量數據快導入:
盡量不用INSERT ... SELECT,一個是有延遲,另外就是會同步出錯
15.打散大批量更新
舉例:
update post set tag=1 WHERE id in (1,2,3); sleep 0.01; update post set tag=1 WHERE id in (4,5,6); sleep 0.01; ……
16.Know Every SQL
作為DBA乃至數據庫開發人員,我們必須對數據庫的每條SQL都非常了解,常見的命令有:
五、約定類原則
1.隔離線上線下
構建數據庫的生態環境,確保開發無線上庫操作權限
原則:線上連線上,線下連線下
2.禁止未經DBA確認的子查詢
舉例:
MySQL> select * from table1 where id in (select id from table2); MySQL> insert into table1 (select * from table2); //可能導致復制異常
3.永遠不在程序端顯式加鎖
對于類似并發扣款等一致性問題,我們采用事務來處理,Commit前進行二次校驗沖突
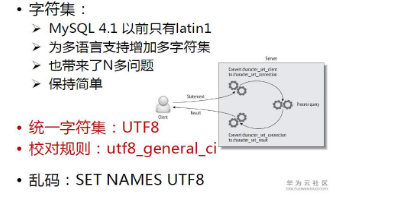
4.統一字符集為UTF8
5.統一命名規范
1)庫表等名稱統一用小寫
2)索引命名默認為“idx_字段名"
3)庫名用縮寫,盡量在2~7個字母
DataSharing ==> ds
4)注意避免用保留字命名
以上所有坑,建議數據庫開發人員都要銘記于心。希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





