溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關Python中怎么操作MySQL數據庫,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
第一種 使用pymysql
代碼如下:
import pymysql #打開數據庫連接 db=pymysql.connect(host='1.1.1.1',port=3306,user='root',passwd='123123',db='test',charset='utf8') cursor=db.cursor()#使用cursor()方法獲取操作游標 sql = "select * from test0811" cursor.execute(sql) info = cursor.fetchall() db.commit() cursor.close() #關閉游標 db.close()#關閉數據庫連接
數據表test0811的內容和上邊的代碼讀出來的內容分別是
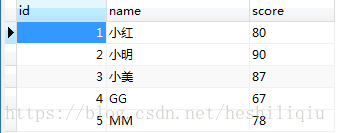

pymysql是Python操作MySQL數據庫的模塊。首先引入pymysql模塊
import pymysql
使用pymysql的connect()方法連接數據庫,connect的幾個參數解釋如下:
host:MySQL服務的地址,若數據庫在本地上,使用localhost或者127.0.0.1。如果在其它的服務器上,應該寫IP地址。
port:服務的端口號,默認為3306,如果不寫,為默認值。
user:登錄數據庫的用戶名
passwd:user賬戶登錄MySQL的密碼
db:將要操作的數據庫的名字
charset:設置為utf8編碼,這樣就可以存入漢字沒有亂碼
注意:除了port=3306不用引號,其它項的值都有用引號括起來
代碼中的db就架起了Python和MySQL通信的橋梁,db.cursor()表示返回連接的游標對象,通過游標執行SQL語句。還有幾個常用的方法是commit()表示提交數據庫修改,rollback()表示回滾,就是取消當前的操作,close()表示關閉連接。
上面講的是連接對象db的一些方法,游標對象的一些方法也很重要,利用游標對象的方法就可以對數據庫進行操作了,游標對象的常用方法如下表:
| 名稱 | 描述 |
|---|---|
| close() | 關閉游標,之后游標不可用 |
| execute(query[,args]) | 執行一條SQL語句,可以帶參數 |
| executemany(query,pseq) | 對序列pseq中的每個參數執行SQL語句 |
| fetchone() | 返回一條查詢結果 |
| fetchall() | 返回所有查詢結果 |
| fetchmany([size]) | 返回size條查詢結果 |
| nextset() | 移動到下一條結果 |
| scroll(value,mode='relative') | 移動游標到指定行,如果mode='relative',則表示從當前行移動value條,如果mode=‘absolute',則表示從結果集的第一行移動value條 |
到這里就基本把pymysql的基本用法講清楚了,剩下的對數據庫的操作(增刪改查)就是SQL語句的事情了。雖然SQL語句很強大,但有時候也會顯得力不從心,Python的靈活加上SQL的強大才可以做更多的事情,而pymysql只是充當工具、橋梁的作用。從代碼運行的結果中(第二幅圖)發現讀出來的結果是存放在二維元組中的,即((1, '小紅', '80'),(2, '小明', '90'),(3, '小美', '87'),(4, 'GG', '67'),(5, 'MM', '78')),但是元組不可改變,只能讀出,對于數據處理還有些不便,下面第二種方法就是把數據讀出存放在DataFrame中,便于處理。
第二種 使用pandas
代碼如下:
import pandas as pd
from sqlalchemy import create_engine
from sqlalchemy.types import CHAR,INT
connect_info = 'mysql+pymysql://username:passwd@host:3306/dbname?charset=utf8'
engine = create_engine(connect_info) #use sqlalchemy to build link-engine
sql = "SELECT * FROM test0811" #SQL query
df = pd.read_sql(sql=sql, con=engine) #read data to DataFrame 'df'
#write df to table 'test1'
df.to_sql(name = 'test1',
con = engine,
if_exists = 'append',
index = False,
dtype = {'id': INT(),
'name': CHAR(length=2),
'score': CHAR(length=2)
}
)pandas的DataFrame數據格式有行索引和列索引,使用DataFrame來存儲數據庫表中的數據會十分方便。使用pandas中的read_sql和to_sql函數從MySQL數據庫中讀寫數據。兩個函數介紹如下。
pandas.read_sql
復制代碼 代碼如下:
pandas.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
pandas.read_sql的文檔中有詳細的各個參數的英文介紹(不要排斥看英文,虛心向老外學習),參考資料http://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_sql.html
常用的參數是sql:SQL命令或者表名字,con:連接數據庫的引擎,可以用SQLAlchemy或者pymysql建立,從數據庫讀數據的基本用法給出sql和con就可以了。其它都是默認參數,有特殊需求才會用到,有興趣的話可以查看文檔。
代碼中的con是使用SQLAlchem構建數據庫連接引擎,即sqlalchemy.create_engine( )。這個函數基于一個URL來產生一個引擎對象,URL通常包含了數據庫的相關信息,典型的形式是:
dialect+driver://username:password@host:port/database
dialect表示數據庫的名字,比如sqlite,mysql,postgresql,oracle,mssql等,driver是用于連接數據庫的DBAPI的名字,這里用的是pymysql(Python 3.x,在Python 2.x中用的是mysqldb),如果這一項不指定,將使用默認的DBAPI。
除了使用SQLAlchemy創建engine外,還可以直接使用DBAPI創建engine,代碼如下:
con = pymysql.connect(host=localhost, user=username, password=password, database=dbname, charset='utf8') df = pd.read_sql(sql, con)
pandas.DataFrame.to_sql
復制代碼 代碼如下:
DataFrame.to_sql(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None)
主要參數介紹如下
name:輸出的表名
con:連接數據庫的引擎
if_exists:三種模式{“fail”,“replace”,"append"},默認是"fail"。fail:若表存在,引發一個ValueError;replace:若表存在,覆蓋原來表內數據;append:若表存在,將數據寫到原表數據的后面。
index:是否將DataFrame的index單獨寫到一列中,默認為“True”
index_label:當index為True時,指定列作為DataFrame的index輸出
dtype:指定列的數據類型,字典形式存儲{column_name: sql_dtype},常見數據類型是sqlalchemy.types.INT()和sqlalchemy.types.CHAR(length=x)。注意:INT和CHAR都需要大寫,INT()不用指定長度。
以上就是Python中怎么操作MySQL數據庫,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





