溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了python接口自動化之如何處理Json數據,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
json 模塊簡介
1、Json 簡介:Json,全名 JavaScript Object Notation,JSON(JavaScript Object Notation(記號、標記))是一種輕量級的數據交換格式。它基于JavaScript(Standard ECMA-262 3rd Edition - December 1999)的一個子集。JSON采用完全獨立
于語言的文本格式,但是也使用了類似于C語言家族的習慣(包括C, C++, C#, Java, JavaScript, Perl, Python等)。這些特性使JSON成為理想的數據交換語言。JSON易于人閱讀和編寫,同時也易于機器解析和生成。常用于 http 請求中,接口
返回的數據中。
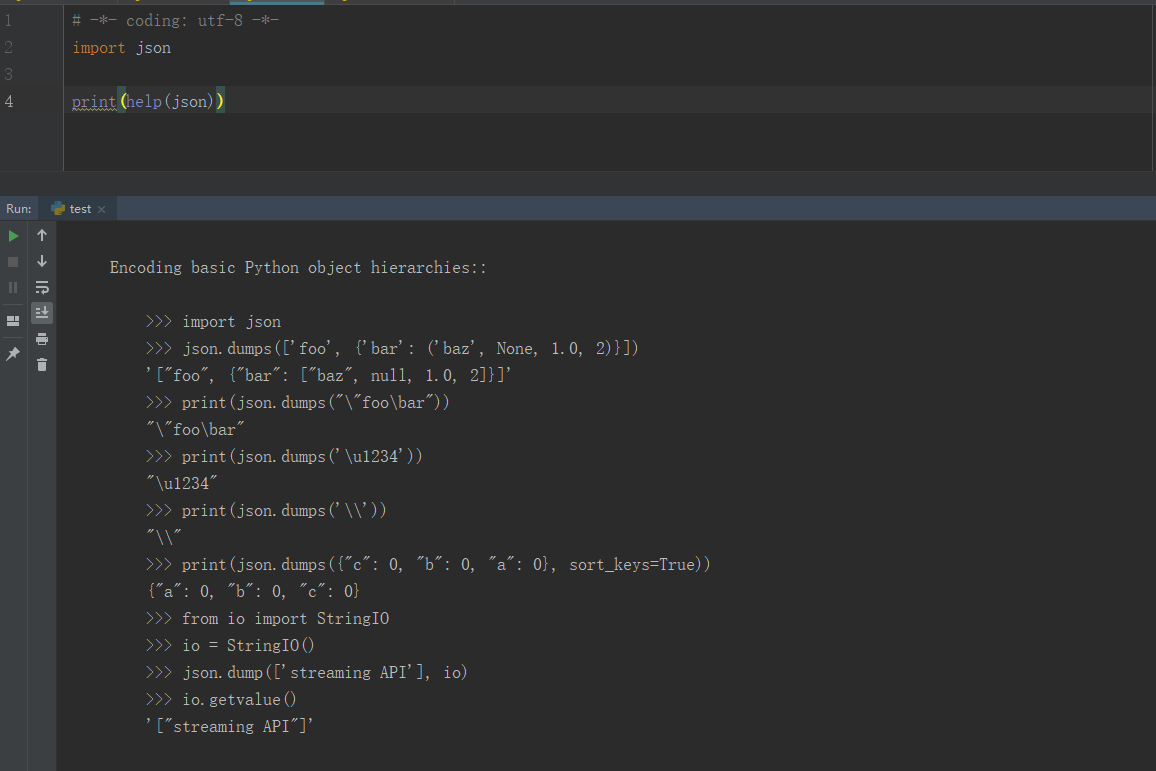
2、可以用 help(json),查看對應的源碼注釋內容
編碼Encode(python->json)
1、為什么要 encode,筆者在開頭就給各位小伙伴開門見山的說出來了,讓各位帶著問題來探索、來學習、來思考
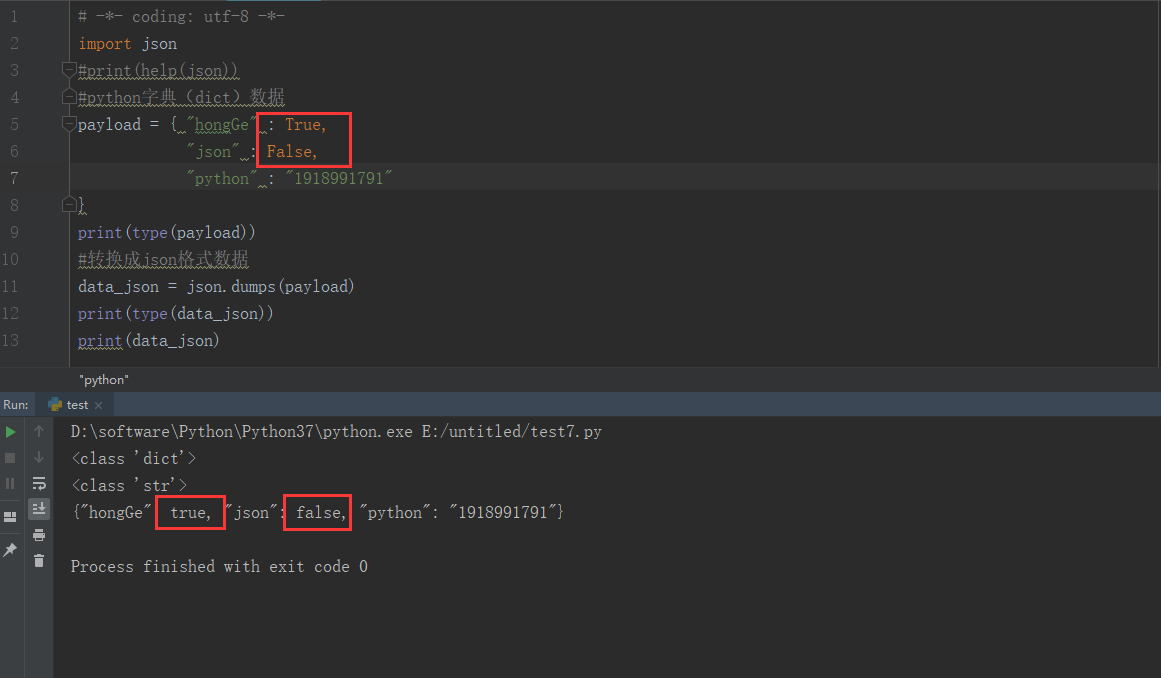
2、舉個簡單例子,下圖的實例中 dict 類型經過 json.dumps()后變成 str,True 變成了 true,False變成了 fasle
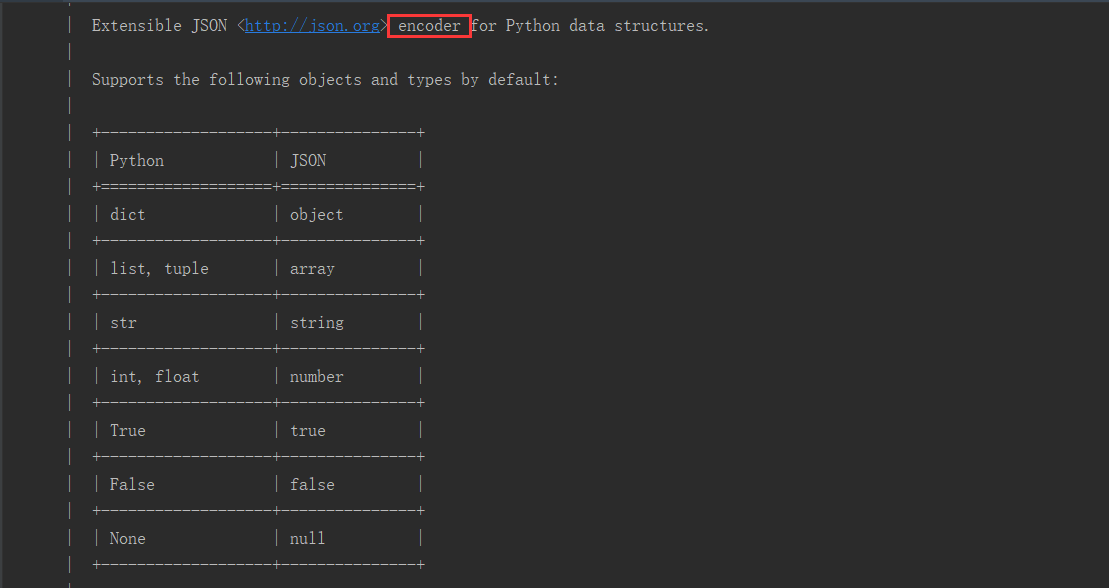
3、從json模塊的對應源碼中可以查看到,python 數據轉化成 json可識別的數據,對應的表關系如下
解碼 decode(json->python)
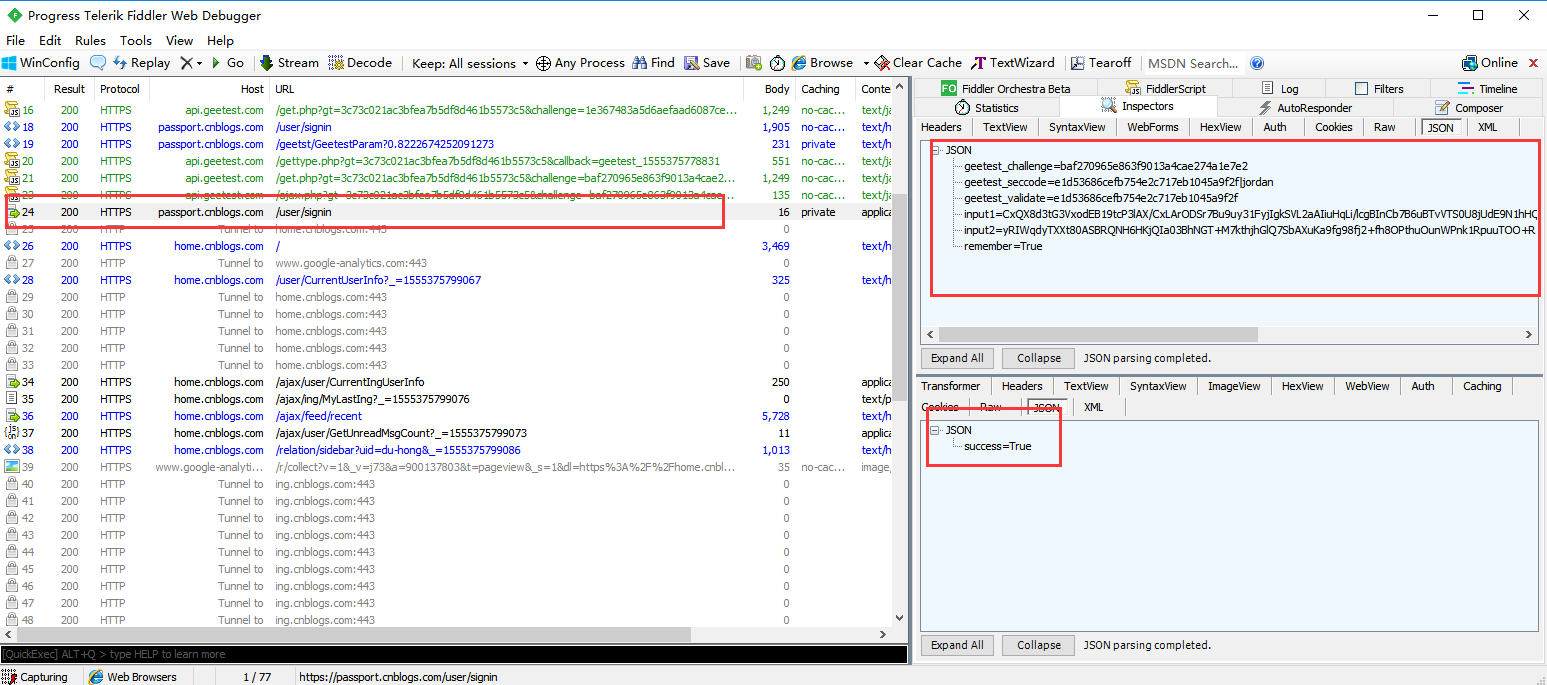
1、以博客園的登錄成功結果:{"success":True}為例,我們其實最想知道的是 success 這個字段返回的是 True 還是 False,以便于我們對接口進行斷言,以下是fiddler抓包博客園登錄成功的結果
2、如果以 content 字節輸出,返回的是一個字符串:{"success":true},這樣獲取后面那個結果就不方便了,導致斷言也不方便
3、如果經過 json 解碼后,返回的就是一個字典:{u'success': True},這樣獲取后面那個結果,就用字典的方式去取值:result2["success"],這樣不言而喻斷言也就簡單方便了
4、由于博客園的登錄機制的改變,我們這里接著上一篇的刪除隨筆的返回結果,給小伙伴們實戰演練一下
5、用fiddler抓包,抓到刪除新建隨筆的請求,從抓包結果可以看出,返回結果是一個字符串:{"isSuccess":True},按照上邊的步驟用代碼實現
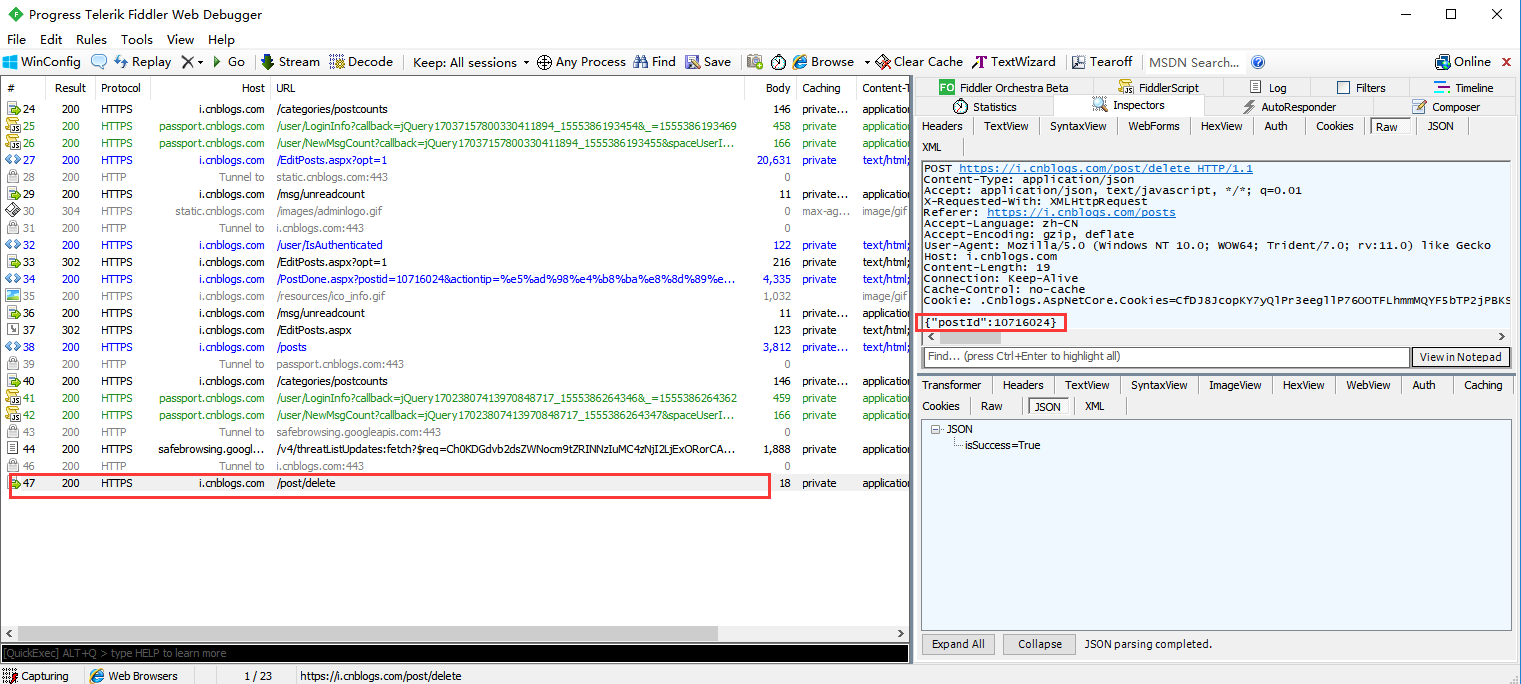
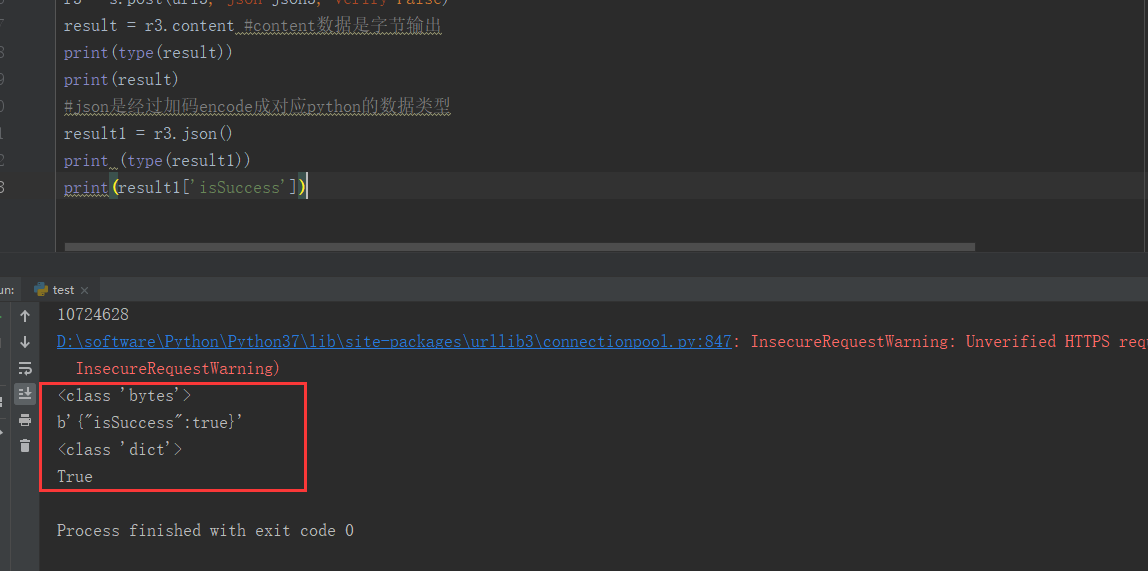
6、代碼及結果(看到了吧,就是這么輕松被我們取到其value了,接下來就可以進行斷言了)
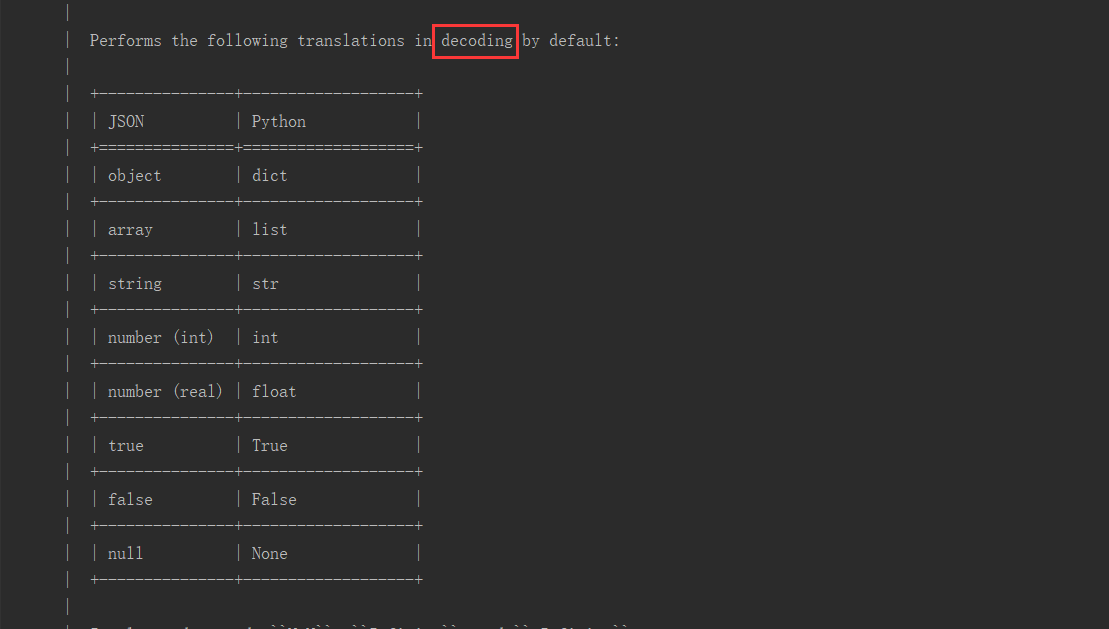
7、從json模塊的對應源碼中可以查看到, json 數據轉化成 python 可識別的數據,對應的表關系如下
8、參考代碼
# coding:utf-8
import requests
# 先打開登錄首頁,獲取部分cookie
url = "https://passport.cnblogs.com/user/signin"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0"
} # get方法其它加個ser-Agent就可以了
s = requests.session()
r = s.get(url, headers=headers,verify=False)
print (s.cookies)
# 添加登錄需要的兩個cookie
c = requests.cookies.RequestsCookieJar()
c.set('.CNBlogsCookie', 'XXX') # 填上面抓包內容
c.set('.Cnblogs.AspNetCore.Cookies','XXX') # 填上面抓包內容
c.set('AlwaysCreateItemsAsActive',"True")
c.set('AdminCookieAlwaysExpandAdvanced',"True")
s.cookies.update(c)
print (s.cookies)
result = r.content
print(result.decode('utf-8'))
# 登錄成功后保存編輯內容
url2= "https://i.cnblogs.com/EditPosts.aspx?opt=1"
body = {"__VIEWSTATE": "",
"__VIEWSTATEGENERATOR":"FE27D343",
"Editor$Edit$txbTitle":"這是繞過登錄的標題:北京-宏哥",
"Editor$Edit$EditorBody":"<p>這里是中文內容:http://www.cnblogs.com/duhong/</p>",
"Editor$Edit$Advanced$ckbPublished":"on",
"Editor$Edit$Advanced$chkDisplayHomePage":"on",
"Editor$Edit$Advanced$chkComments":"on",
"Editor$Edit$Advanced$chkMainSyndication":"on",
"Editor$Edit$lkbDraft":"存為草稿",
}
r2 = s.post(url2, data=body, verify=False)
print (r.content.decode('utf-8'))
# 第三步:正則提取需要的參數值
import re
postid = re.findall(r"postid=(.+?)&", r2.url)
print(type(postid))
print (postid) # 這里是 list
# 提取為字符串
print (postid[0])
# 第四步:刪除草稿箱
url3 = "https://i.cnblogs.com/post/delete"
json3 = {"postId": postid[0]}
r3 = s.post(url3, json=json3, verify=False)
result = r3.content #content數據是字節輸出
print(type(result))
print(result)
#json是經過加碼encode成對應python的數據類型
result1 = r3.json()
print (type(result1))
print(result1['isSuccess'])感謝你能夠認真閱讀完這篇文章,希望小編分享的“python接口自動化之如何處理Json數據”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





