溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
什么是推薦系統
維基百科這樣解釋道:推薦系統屬于資訊過濾的一種應用。推薦系統能夠將可能受喜好的資訊或實物(例如:電影、電視節目、音樂、書籍、新聞、圖片、網頁)推薦給使用者。
本質上是根據用戶的一些行為數據有針對性的推薦用戶更可能感興趣的內容。比如在網易云音樂聽歌,聽得越多,它就會推薦越多符合你喜好的音樂。
推薦系統是如何工作的呢?有一種思路如下:
用戶 A 聽了 收藏了 a,b,c 三首歌。用戶 B 收藏了 a, b 兩首歌,這時候推薦系統就把 c 推薦給用戶 B。因為算法判斷用戶 A,B 對音樂的品味有極大可能一致。
推薦算法分類
最常見的推薦算法分為基于內容推薦以及協同過濾。協同過濾又可以分為基于用戶的協同過濾和基于物品的協同過濾
基于內容推薦是直接判斷所推薦內容本身的相關性,比如文章推薦,算法判斷某篇文章和用戶歷史閱讀文章的相關性進行推薦。
基于用戶的協同過濾就是文章開頭舉的例子。
基于物品的協同過濾:
假設用戶 A,B,C 都收藏了音樂 a,b。然后用戶 D 收藏了音樂 a,那么這時候就推薦音樂 b 給他。
動手打造自己的推薦系統
這一次我們要做的是一個簡單的電影推薦,雖然離工業應用還差十萬八千里,但是非常適合新手一窺推薦系統的內部原理。數據集包含兩個文件:ratings.csv 和 movies.csv。
# 載入數據
import pandas as pd
import numpy as np
df = pd.read_csv('data/ratings.csv')
df.head()
ratings.csv 包含四個維度的數據:
要推薦電影還需要有電影的名字,電影名字保存在 movies.csv 中:
movies = pd.read_csv('data/movies.csv')
movies.head()
將 ratings.csv 和 movies.csv 的數據根據 movieId 合并。
df = pd.merge(df, movie_title, on='movieId') df.head()
我們這次要做的推薦系統的核心思路是:
所以我們要先有所有用戶對所有電影的評分的列聯表:
movie_matrix = df.pivot_table(index = 'userId', columns = 'title' ,values = 'rating') movie_matrix.head()
假設用戶 A 觀看的電影是 air_force_one (1997),則計算列聯表中所有電影與 air_force_one (1997) 的相關性。
AFO_user_rating = movie_matrix['Air Force One (1997)'] simliar_to_air_force_one = movie_matrix.corrwith(AFO_user_rating)
這樣我們就得到了所有電影與 air_force_one (1997)的相關性。
但是,直接對這個相關性進行排序并推薦最相關的電影有一個及其嚴重的問題:
ratings = pd.DataFrame(df.groupby('title')['rating'].mean())#計算電影平均得分
ratings['number_of_ratings'] = df.groupby('title')['rating'].count()
import matplotlib.pyplot as plt
%matplotlib inline
ratings['number_of_ratings'].hist(bins = 60);
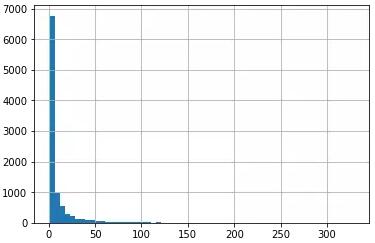
上圖是電影被評分次數的直方圖,可以看到大量的電影評分次數不足10次。評分次數太少的電影很容易就被判斷為高相關性。所以我們要將這部分的評分刪掉。
corr_AFO = pd.DataFrame(similar_to_air_force_one, columns = ['Correlation']) corr_AFO.dropna(inplace = True) corr_contact = corr_contact.join(ratings['number_of_ratings'],how = 'left',lsuffix='_left', rsuffix='_right') corr_AFO[corr_AFO['number_of_ratings']>100].sort_values(by = 'Correlation',ascending = False).head()
這樣我們就得到了一個與 air_force_one (1997) 高相關的電影列表。但是高相關有可能評分低(概率低),再從列表里挑幾部平均得分高的電影推薦就好了。
總結
以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作具有一定的參考學習價值,謝謝大家對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





