溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關python中協程的示例分析,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
先介紹下什么是協程:
協程,又稱微線程,纖程,英文名Coroutine。協程的作用,是在執行函數A時,可以隨時中斷,去執行函數B,然后中斷繼續執行函數A(可以自由切換)。但這一過程并不是函數調用(沒有調用語句),這一整個過程看似像多線程,然而協程只有一個線程執行。
是不是有點沒看懂,沒事,我們下面會解釋。要理解協程是什么,首先需要理解yield,這里簡單介紹下,yield可以理解為生成器,yield item這行代碼會產出一個值,提供給next(...)的調用方; 此外,還會作出讓步,暫停執行生成器,讓調用方繼續工作,直到需要使用另一個值時再調用next()。調用方會從生成器中拉取值,但是在協程中,yield關鍵字一般是在表達式右邊(如,data=yield),協程可以從調用方接收數據,也可以產出數據,下面看一個簡單的例子:
>>> def simple_coroutine():
... print('coroutine start')
... x = yield
... print('coroutine recive:',x)
...
>>> my_co=simple_coroutine()
>>> my_co
<generator object simple_coroutine at 0x1085174f8>
>>> next(my_co)
coroutine start
>>> my_co.send(42)
coroutine recive: 42
Traceback (most recent call last):
File "<input>", line 1, in <module>
StopIteration其中x = yield就是精髓部分,意思是從客戶端獲取數據,產出None,因為yield關鍵字右邊沒有表達式, 而協程在創建完成之后,是沒有啟動的,沒有在yield處暫停,所以需要調用next()函數,啟動協程,在調用my_co.send(42)之后,協程定義體中的yield表達式會計算出42,現在協程恢復,一直運行到下一個yield表達式,或者終止,在最后,控制權流動到協程定義體的末尾,生成器拋出StopIteration異常。
協程有四個狀態,如下:
'GEN_CREATED' 等待開始執行。
'GEN_RUNNING' 解釋器正在執行。
'GEN_SUSPENDED' 在 yield 表達式處暫停。
'GEN_CLOSED' 執行結束。
當前狀態可以使用inspect.getgeneratorstate來確定,如下:
>>> import inspect >>> inspect.getgeneratorstate(my_co) 'GEN_CLOSED'
這里再解釋下next(my_co),如果在創建好協程對象之后,立即把None之外的值發送給它,會出現如下錯誤:
>>> my_co=simple_coroutine() >>> my_co.send(42) Traceback (most recent call last): File "<input>", line 1, in <module> TypeError: can't send non-None value to a just-started generator >>> my_co=simple_coroutine() >>> my_co.send(None) coroutine start
最先調用 next(my_co) 函數這一步通常稱為“預激”(prime)協程(即,讓協程向前執行到第一個 yield 表達式,準備好作為活躍的協程使用)。
再參考下面這個例子:
>>> def simple_coro2(a):
... print('-> Started: a =', a)
... b = yield a
... print('-> Received: b =', b)
... c = yield a + b
... print('-> Received: c =', c)
...
>>> my_coro2 = simple_coro2(14)
>>> from inspect import getgeneratorstate
>>> getgeneratorstate(my_coro2)
'GEN_CREATED'
>>> next(my_coro2) # 協程執行到`b = yield a`處暫停,等待為b賦值,
-> Started: a = 14
14
>>> getgeneratorstate(my_coro2)
'GEN_SUSPENDED' #從狀態也可以看到,當前是暫停狀態。
>>> my_coro2.send(28) #將28發送到協程,計算yield表達式,并把結果綁定到b,產出a+b的值,然后暫停。
-> Received: b = 28
42
>>> my_coro2.send(99)
-> Received: c = 99
Traceback (most recent call last):
File "<input>", line 1, in <module>
StopIteration
>>> getgeneratorstate(my_coro2)
'GEN_CLOSED'simple_coro2的執行過程如下圖所示:
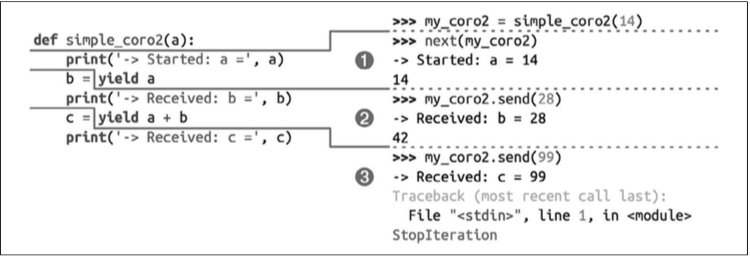
調用next(my_coro2),打印第一個消息,然后執行yield a,產出數字 14。
調用my_coro2.send(28),把28賦值給b,打印第二個消息,然后執行yield a + b,產 出數字 42。
調用my_coro2.send(99),把 99 賦值給 c,打印第三個消息,協程終止。
說了這么多,我們為什么要用協程呢,下面我們再看看它的優勢是什么:
執行效率極高,因為子程序切換(函數)不是線程切換,由程序自身控制,沒有切換線程的開銷。所以與多線程相比,線程的數量越多,協程性能的優勢越明顯。
不需要多線程的鎖機制,因為只有一個線程,也不存在同時寫變量沖突,在控制共享資源時也不需要加鎖,因此執行效率高很多。
說明:協程可以處理IO密集型程序的效率問題,但是處理CPU密集型不是它的長處,如要充分發揮CPU利用率可以結合多進程+協程。
下面看最后一個例子,傳統的生產者-消費者模型是一個線程寫消息,一個線程取消息,通過鎖機制控制隊列和等待,但一不小心就可能死鎖。
如果改用協程,生產者生產消息后,直接通過yield跳轉到消費者開始執行,待消費者執行完畢后,切換回生產者繼續生產,效率極高:
from bs4 import BeautifulSoup
import requests
from urllib.parse import urlparse
start_url = 'https://www.cnblogs.com'
trust_host = 'www.cnblogs.com'
ignore_path = []
history_urls = []
def parse_html(html):
soup = BeautifulSoup(html, "lxml")
print(soup.title)
links = soup.find_all('a', href=True)
return (a['href'] for a in links if a['href'])
def parse_url(url):
url = url.strip()
if url.find('#') >= 0:
url = url.split('#')[0]
if not url:
return None
if url.find('javascript:') >= 0:
return None
for f in ignore_path:
if f in url:
return None
if url.find('http') < 0:
url = start_url + url
return url
parse = urlparse(url)
if parse.hostname == trust_host:
return url
def consumer():
html = ''
while True:
url = yield html
if url:
print('[CONSUMER] Consuming %s...' % url)
rsp = requests.get(url)
html = rsp.content
def produce(c):
next(c)
def do_work(urls):
for u in urls:
if u not in history_urls:
history_urls.append(u)
print('[PRODUCER] Producing %s...' % u)
html = c.send(u)
results = parse_html(html)
work_urls = (x for x in map(parse_url, results) if x)
do_work(work_urls)
do_work([start_url])
c.close()
if __name__ == '__main__':
c = consumer()
produce(c)
print(len(history_urls))首先consumer函數是一個generator,在開始執行之后:
調用next(c)啟動生成器;
進入do_work,這是一個遞歸調用,其內部將url傳遞給consumer,由consumer來發出請求,獲取到html信息,返回給produce,
produce解析html,獲取url數據,繼續生產url,
當所有的url都在history_urls中,也就是說我們已經爬取了所有的url地址,結束遞歸調用
調用c.close(),關閉consumer,整個過程結束。
可以看到,我們的整個流程無鎖,由一個線程執行,produce和consumer協作完成任務,所以稱為“協程”,而非線程的搶占式多任務。
關于“python中協程的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





