溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“PySpark SQL相關知識的示例分析”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“PySpark SQL相關知識的示例分析”這篇文章吧。
1 大數據簡介
大數據是這個時代最熱門的話題之一。但是什么是大數據呢?它描述了一個龐大的數據集,并且正在以驚人的速度增長。大數據除了體積(Volume)和速度(velocity)外,數據的多樣性(variety)和準確性(veracity)也是大數據的一大特點。讓我們詳細討論體積、速度、多樣性和準確性。這些也被稱為大數據的4V特征。
1.1 Volume
數據體積(Volume)指定要處理的數據量。對于大量數據,我們需要大型機器或分布式系統。計算時間隨數據量的增加而增加。所以如果我們能并行化計算,最好使用分布式系統。數據可以是結構化數據、非結構化數據或介于兩者之間的數據。如果我們有非結構化數據,那么情況就會變得更加復雜和計算密集型。你可能會想,大數據到底有多大?這是一個有爭議的問題。但一般來說,我們可以說,我們無法使用傳統系統處理的數據量被定義為大數據。現在讓我們討論一下數據的速度。
1.2 Velocity
越來越多的組織機構開始重視數據。每時每刻都在收集大量的數據。這意味著數據的速度在增加。一個系統如何處理這個速度?當必須實時分析大量流入的數據時,問題就變得復雜了。許多系統正在開發,以處理這種巨大的數據流入。將傳統數據與大數據區別開來的另一個因素是數據的多樣性。
1.3 Variety
數據的多樣性使得它非常復雜,傳統的數據分析系統無法正確地分析它。我們說的是哪一種?數據不就是數據嗎?圖像數據不同于表格數據,因為它的組織和保存方式不同。可以使用無限數量的文件系統。每個文件系統都需要一種不同的方法來處理它。讀取和寫入JSON文件與處理CSV文件的方式不同。現在,數據科學家必須處理數據類型的組合。您將要處理的數據可能是圖片、視頻、文本等的組合。大數據的多樣性使得分析變得更加復雜。
1.4 Veracity
你能想象一個邏輯錯誤的計算機程序產生正確的輸出嗎?同樣,不準確的數據將提供誤導的結果。準確性,或數據正確性,是一個重要的問題。對于大數據,我們必須考慮數據的異常。
2 Hadoop 介紹
Hadoop是一個解決大數據問題的分布式、可伸縮的框架。Hadoop是由Doug Cutting和Mark Cafarella開發的。Hadoop是用Java編寫的。它可以安裝在一組商用硬件上,并且可以在分布式系統上水平擴展。
在商品硬件上工作使它非常高效。如果我們的工作是在商品硬件,故障是一個不可避免的問題。但是Hadoop為數據存儲和計算提供了一個容錯系統。這種容錯能力使得Hadoop非常流行。
Hadoop有兩個組件:第一個組件是HDFS(Hadoop Distributed File System),它是一個分布式文件系統。第二個組件是MapReduce。HDFS用于分布式數據存儲,MapReduce用于對存儲在HDFS中的數據執行計算。
2.1 HDFS介紹
HDFS用于以分布式和容錯的方式存儲大量數據。HDFS是用Java編寫的,在普通硬件上運行。它的靈感來自于谷歌文件系統(GFS)的谷歌研究論文。它是一個寫一次讀多次的系統,對大量的數據是有效的。HDFS有兩個組件NameNode和DataNode。
這兩個組件是Java守護進程。NameNode負責維護分布在集群上的文件的元數據,它是許多datanode的主節點。HDFS將大文件分成小塊,并將這些塊保存在不同的datanode上。實際的文件數據塊駐留在datanode上。HDFS提供了一組類unix-shell的命令。但是,我們可以使用HDFS提供的Java filesystem API在更細的級別上處理大型文件。容錯是通過復制數據塊來實現的。
我們可以使用并行的單線程進程訪問HDFS文件。HDFS提供了一個非常有用的實用程序,稱為distcp,它通常用于以并行方式將數據從一個HDFS系統傳輸到另一個HDFS系統。它使用并行映射任務復制數據。
2.2 MapReduce介紹
計算的MapReduce模型最早出現在谷歌的一篇研究論文中。Hadoop的MapReduce是Hadoop框架的計算引擎,它在HDFS中對分布式數據進行計算。MapReduce已被發現可以在商品硬件的分布式系統上進行水平伸縮。它也適用于大問題。在MapReduce中,問題的解決分為Map階段和Reduce階段。在Map階段,處理數據塊,在Reduce階段,對Map階段的結果運行聚合或縮減操作。Hadoop的MapReduce框架也是用Java編寫的。
MapReduce是一個主從模型。在Hadoop 1中,這個MapReduce計算由兩個守護進程Jobtracker和Tasktracker管理。Jobtracker是處理許多任務跟蹤器的主進程。Tasktracker是Jobtracker的從節點。但在Hadoop 2中,Jobtracker和Tasktracker被YARN取代。
我們可以使用框架提供的API和Java編寫MapReduce代碼。Hadoop streaming體模塊使具有Python和Ruby知識的程序員能夠編寫MapReduce程序。
MapReduce算法有很多用途。如許多機器學習算法都被Apache Mahout實現,它可以在Hadoop上通過Pig和Hive運行。
但是MapReduce并不適合迭代算法。在每個Hadoop作業結束時,MapReduce將數據保存到HDFS并為下一個作業再次讀取數據。我們知道,將數據讀入和寫入文件是代價高昂的活動。Apache Spark通過提供內存中的數據持久性和計算,減輕了MapReduce的缺點。
更多關于Mapreduce 和 Mahout 可以查看如下網頁:
https://www.usenix.org/legacy/publications/library/proceedings/osdi04/tech/full_papers/dean/dean_html/index.html
https://mahout.apache.org/users/basics/quickstart.html
3 Apache Hive 介紹
計算機科學是一個抽象的世界。每個人都知道數據是以位的形式出現的信息。像C這樣的編程語言提供了對機器和匯編語言的抽象。其他高級語言提供了更多的抽象。結構化查詢語言(Structured Query Language, SQL)就是這些抽象之一。世界各地的許多數據建模專家都在使用SQL。Hadoop非常適合大數據分析。那么,了解SQL的廣大用戶如何利用Hadoop在大數據上的計算能力呢?為了編寫Hadoop的MapReduce程序,用戶必須知道可以用來編寫Hadoop的MapReduce程序的編程語言。
現實世界中的日常問題遵循一定的模式。一些問題在日常生活中很常見,比如數據操作、處理缺失值、數據轉換和數據匯總。為這些日常問題編寫MapReduce代碼對于非程序員來說是一項令人頭暈目眩的工作。編寫代碼來解決問題不是一件很聰明的事情。但是編寫具有性能可伸縮性和可擴展性的高效代碼是有價值的。考慮到這個問題,Apache Hive就在Facebook開發出來,它可以解決日常問題,而不需要為一般問題編寫MapReduce代碼。
根據Hive wiki的語言,Hive是一個基于Apache Hadoop的數據倉庫基礎設施。Hive有自己的SQL方言,稱為Hive查詢語言。它被稱為HiveQL,有時也稱為HQL。使用HiveQL, Hive查詢HDFS中的數據。Hive不僅運行在HDFS上,還運行在Spark和其他大數據框架上,比如Apache Tez。
Hive為HDFS中的結構化數據向用戶提供了類似關系數據庫管理系統的抽象。您可以創建表并在其上運行類似sql的查詢。Hive將表模式保存在一些RDBMS中。Apache Derby是Apache Hive發行版附帶的默認RDBMS。Apache Derby完全是用Java編寫的,是Apache License Version 2.0附帶的開源RDBMS。
HiveQL命令被轉換成Hadoop的MapReduce代碼,然后在Hadoop集群上運行。
了解SQL的人可以輕松學習Apache Hive和HiveQL,并且可以在日常的大數據數據分析工作中使用Hadoop的存儲和計算能力。PySpark SQL也支持HiveQL。您可以在PySpark SQL中運行HiveQL命令。除了執行HiveQL查詢,您還可以直接從Hive讀取數據到PySpark SQL并將結果寫入Hive
相關鏈接:
https://cwiki.apache.org/confluence/display/Hive/Tutorial
https://db.apache.org/derby/
4 Apache Pig介紹
Apache Pig是一個數據流框架,用于對大量數據執行數據分析。它是由雅虎開發的,并向Apache軟件基金會開放源代碼。它現在可以在Apache許可2.0版本下使用。Pig編程語言是一種Pig拉丁腳本語言。Pig松散地連接到Hadoop,這意味著我們可以將它連接到Hadoop并執行許多分析。但是Pig可以與Apache Tez和Apache Spark等其他工具一起使用。
Apache Hive用作報告工具,其中Apache Pig用于提取、轉換和加載(ETL)。我們可以使用用戶定義函數(UDF)擴展Pig的功能。用戶定義函數可以用多種語言編寫,包括Java、Python、Ruby、JavaScript、Groovy和Jython。
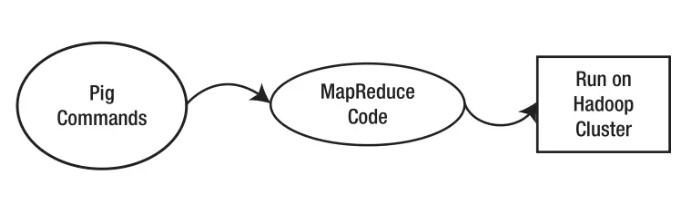
Apache Pig使用HDFS讀取和存儲數據,Hadoop的MapReduce執行算法。Apache Pig在使用Hadoop集群方面類似于Apache Hive。在Hadoop上,Pig命令首先轉換為Hadoop的MapReduce代碼。然后將它們轉換為MapReduce代碼,該代碼運行在Hadoop集群上。
Pig最好的部分是對代碼進行優化和測試,以處理日常問題。所以用戶可以直接安裝Pig并開始使用它。Pig提供了Grunt shell來運行交互式的Pig命令。因此,任何了解Pig Latin的人都可以享受HDFS和MapReduce的好處,而不需要了解Java或Python等高級編程語言。
相關鏈接
http://pig.apache.org/docs/
https://en.wikipedia.org/wiki/Pig_(programming_tool))
https://cwiki.apache.org/confluence/display/PIG/Index
5 Apache Kafka 介紹
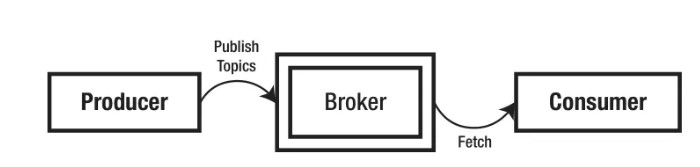
Apache Kafka是一個發布-訂閱的分布式消息傳遞平臺。它由LinkedIn開發,并進一步開源給Apache基金會。它是容錯的、可伸縮的和快速的。Kafka術語中的消息(數據的最小單位)通過Kafka服務器從生產者流向消費者,并且可以在稍后的時間被持久化和使用。
Kafka提供了一個內置的API,開發人員可以使用它來構建他們的應用程序。接下來我們討論Apache Kafka的三個主要組件。
5.1 Producer
Kafka Producer 將消息生成到Kafka主題,它可以將數據發布到多個主題。
5.2 Broker
這是運行在專用機器上的Kafka服務器,消息由Producer推送到Broker。Broker將主題保存在不同的分區中,這些分區被復制到不同的Broker以處理錯誤。它本質上是無狀態的,因此使用者必須跟蹤它所消費的消息。
5.3 Consumer
Consumer從Kafka代理獲取消息。記住,它獲取消息。Kafka Broker不會將消息推送給Consumer;相反,Consumer從Kafka Broker中提取數據。Consumer訂閱Kafka Broker上的一個或多個主題,并讀取消息。Broker還跟蹤它所使用的所有消息。數據將在Broker中保存指定的時間。如果使用者失敗,它可以在重新啟動后獲取數據。
相關鏈接:
https://kafka.apache.org/quickstart
https://kafka.apache.org/documentation/
6 Apache Spark介紹
Apache Spark是一個通用的分布式編程框架。它被認為非常適合迭代和批處理數據。它是在AMP實驗室開發的,它提供了一個內存計算框架。它是開源軟件。一方面,它最適合批量處理,另一方面,它對實時或接近實時的數據非常有效。機器學習和圖形算法本質上是迭代的,這就是Spark的神奇之處。根據它的研究論文,它比它的同行Hadoop快得多。數據可以緩存在內存中。在迭代算法中緩存中間數據提供了驚人的快速處理。Spark可以使用Java、Scala、Python和R進行編程。
如果您認為Spark是經過改進的Hadoop,在某種程度上,確實是可以這么認為的。因為我們可以在Spark中實現MapReduce算法,所以Spark使用了HDFS的優點。這意味著它可以從HDFS讀取數據并將數據存儲到HDFS,而且它可以有效地處理迭代計算,因為數據可以保存在內存中。除了內存計算外,它還適用于交互式數據分析。
還有許多其他庫也位于PySpark之上,以便更容易地使用PySpark。下面我們將討論一些:
MLlib: MLlib是PySpark核心的一個包裝器,它處理機器學習算法。MLlib庫提供的機器學習api非常容易使用。MLlib支持多種機器學習算法,包括分類、聚類、文本分析等等。
ML: ML也是一個位于PySpark核心的機器學習庫。ML的機器學習api可以用于數據流。
GraphFrames: GraphFrames庫提供了一組api,可以使用PySpark core和PySpark SQL高效地進行圖形分析。
7 PySpark SQL介紹
數據科學家處理的大多數數據在本質上要么是結構化的,要么是半結構化的。為了處理結構化和半結構化數據集,PySpark SQL模塊是該PySpark核心之上的更高級別抽象。我們將在整本書中學習PySpark SQL。它內置在PySpark中,這意味著它不需要任何額外的安裝。
使用PySpark SQL,您可以從許多源讀取數據。PySpark SQL支持從許多文件格式系統讀取,包括文本文件、CSV、ORC、Parquet、JSON等。您可以從關系數據庫管理系統(RDBMS)讀取數據,如MySQL和PostgreSQL。您還可以將分析報告保存到許多系統和文件格式。
7.1 DataFrames
DataFrames是一種抽象,類似于關系數據庫系統中的表。它們由指定的列組成。DataFrames是行對象的集合,這些對象在PySpark SQL中定義。DataFrames也由指定的列對象組成。用戶知道表格形式的模式,因此很容易對數據流進行操作。
DataFrame 列中的元素將具有相同的數據類型。DataFrame 中的行可能由不同數據類型的元素組成。基本數據結構稱為彈性分布式數據集(RDD)。數據流是RDD上的包裝器。它們是RDD或row對象。
相關鏈接:
https://spark.apache.org/docs/latest/sql-programming-guide.html
7.2 SparkSession
SparkSession對象是替換SQLContext和HiveContext的入口點。為了使PySpark SQL代碼與以前的版本兼容,SQLContext和HiveContext將繼續在PySpark中運行。在PySpark控制臺中,我們獲得了SparkSession對象。我們可以使用以下代碼創建SparkSession對象。
為了創建SparkSession對象,我們必須導入SparkSession,如下所示。
from pyspark.sql import SparkSession
導入SparkSession后,我們可以使用SparkSession.builder進行操作:
spark = SparkSession.builder.appName("PythonSQLAPP") .getOrCreate()appName函數將設置應用程序的名稱。函數的作用是:返回一個現有的SparkSession對象。如果不存在SparkSession對象,getOrCreate()函數將創建一個新對象并返回它。
7.3 Structured Streaming
我們可以使用結構化流框架(PySpark SQL的包裝器)進行流數據分析。我們可以使用結構化流以類似的方式對流數據執行分析,就像我們使用PySpark SQL對靜態數據執行批處理分析一樣。正如Spark流模塊對小批執行流操作一樣,結構化流引擎也對小批執行流操作。結構化流最好的部分是它使用了類似于PySpark SQL的API。因此,學習曲線很高。對數據流的操作進行優化,并以類似的方式在性能上下文中優化結構化流API。
7.4 Catalyst Optimizer
SQL是一種聲明性語言。使用SQL,我們告訴SQL引擎要做什么。我們不告訴它如何執行任務。類似地,PySpark SQL命令不會告訴它如何執行任務。這些命令只告訴它要執行什么。因此,PySpark SQL查詢在執行任務時需要優化。catalyst優化器在PySpark SQL中執行查詢優化。PySpark SQL查詢被轉換為低級的彈性分布式數據集(RDD)操作。catalyst優化器首先將PySpark SQL查詢轉換為邏輯計劃,然后將此邏輯計劃轉換為優化的邏輯計劃。從這個優化的邏輯計劃創建一個物理計劃。創建多個物理計劃。使用成本分析儀,選擇最優的物理方案。最后,創建低層RDD操作代碼。
8 集群管理器(Cluster Managers)
在分布式系統中,作業或應用程序被分成不同的任務,這些任務可以在集群中的不同機器上并行運行。如果機器發生故障,您必須在另一臺機器上重新安排任務。
由于資源管理不善,分布式系統通常面臨可伸縮性問題。考慮一個已經在集群上運行的作業。另一個人想做另一份工作。第二項工作必須等到第一項工作完成。但是這樣我們并沒有最優地利用資源。資源管理很容易解釋,但是很難在分布式系統上實現。開發集群管理器是為了優化集群資源的管理。有三個集群管理器可用于Spark單機、Apache Mesos和YARN。這些集群管理器最好的部分是,它們在用戶和集群之間提供了一個抽象層。由于集群管理器提供的抽象,用戶體驗就像在一臺機器上工作,盡管他們在集群上工作。集群管理器將集群資源調度到正在運行的應用程序。
8.1 單機集群管理器(Standalone Cluster Manager)
Apache Spark附帶一個單機集群管理器。它提供了一個主從架構來激發集群。它是一個只使用spark的集群管理器。您只能使用這個獨立的集群管理器運行Spark應用程序。它的組件是主組件和工作組件。工人是主過程的奴隸,它是最簡單的集群管理器。可以使用Spark的sbin目錄中的腳本配置Spark獨立集群管理器。
8.2 Apache Mesos集群管理器(Apache Mesos Cluster Manager)
Apache Mesos是一個通用的集群管理器。它是在加州大學伯克利分校的AMP實驗室開發的。Apache Mesos幫助分布式解決方案有效地擴展。您可以使用Mesos在同一個集群上使用不同的框架運行不同的應用程序。來自不同框架的不同應用程序的含義是什么?這意味著您可以在Mesos上同時運行Hadoop應用程序和Spark應用程序。當多個應用程序在Mesos上運行時,它們共享集群的資源。Apache Mesos有兩個重要組件:主組件和從組件。這種主從架構類似于Spark獨立集群管理器。運行在Mesos上的應用程序稱為框架。奴隸告訴主人作為資源提供的可用資源。從機定期提供資源。主服務器的分配模塊決定哪個框架獲取資源。
8.3 YARN 集群管理器(YARN Cluster Manager)
YARN代表著另一個資源談判者(Resource Negotiator)。在Hadoop 2中引入了YARN來擴展Hadoop。資源管理與作業管理分離。分離這兩個組件使Hadoop的伸縮性更好。YARN的主要成分是資源管理器(Resource Manager)、應用程序管理器(Application Master)和節點管理器(Node Manager)。有一個全局資源管理器,每個集群將運行許多節點管理器。節點管理器是資源管理器的奴隸。調度程序是ResourceManager的組件,它為集群上的不同應用程序分配資源。最棒的部分是,您可以在YARN管理的集群上同時運行Spark應用程序和任何其他應用程序,如Hadoop或MPI。每個應用程序有一個application master,它處理在分布式系統上并行運行的任務。另外,Hadoop和Spark有它們自己的ApplicationMaster。
9 PostgreSQL介紹
關系數據庫管理系統在許多組織中仍然非常常見。這里的關系是什么意思?關系表。PostgreSQL是一個關系數據庫管理系統。它可以運行在所有主要的操作系統上,比如Microsoft Windows、基于unix的操作系統、MacOS X等等。它是一個開源程序,代碼在PostgreSQL許可下可用。因此,您可以自由地使用它,并根據您的需求進行修改。
PostgreSQL數據庫可以通過其他編程語言(如Java、Perl、Python、C和c++)和許多其他語言(通過不同的編程接口)連接。還可以使用與PL/SQL類似的過程編程語言PL/pgSQL(過程語言/PostgreSQL)對其進行編程。您可以向該數據庫添加自定義函數。您可以用C/ c++和其他編程語言編寫自定義函數。您還可以使用JDBC連接器從PySpark SQL中讀取PostgreSQL中的數據。
PostgreSQL遵循ACID(Atomicity, Consistency, Isolation and
Durability/原子性、一致性、隔離性和持久性)原則。它具有許多特性,其中一些是PostgreSQL獨有的。它支持可更新視圖、事務完整性、復雜查詢、觸發器等。PostgreSQL使用多版本并發控制模型進行并發管理。
PostgreSQL得到了廣泛的社區支持。PostgreSQL被設計和開發為可擴展的。
10 MongoDB介紹
MongoDB是一個基于文檔的NoSQL數據庫。它是一個開放源碼的分布式數據庫,由MongoDB公司開發。MongoDB是用c++編寫的,它是水平伸縮的。許多組織將其用于后端數據庫和許多其他用途。
MongoDB附帶一個mongo shell,這是一個到MongoDB服務器的JavaScript接口。mongo shell可以用來運行查詢以及執行管理任務。在mongo shell上,我們也可以運行JavaScript代碼。
使用PySpark SQL,我們可以從MongoDB讀取數據并執行分析。我們也可以寫出結果。
11 Cassandra介紹
Cassandra是開放源碼的分布式數據庫,附帶Apache許可證。這是一個由Facebook開發的NoSQL數據庫。它是水平可伸縮的,最適合處理結構化數據。它提供了高水平的一致性,并且具有可調的一致性。它沒有一個單一的故障點。它使用對等的分布式體系結構在不同的節點上復制數據。節點使用閑話協議交換信息。
以上是“PySpark SQL相關知識的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





