溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
推薦算法在互聯網行業的應用非常廣泛,今日頭條、美團點評等都有個性化推薦,推薦算法抽象來講,是一種對于內容滿意度的擬合函數,涉及到用戶特征和內容特征,作為模型訓練所需維度的兩大來源,而點擊率,頁面停留時間,評論或下單等都可以作為一個量化的 Y 值,這樣就可以進行特征工程,構建出一個數據集,然后選擇一個合適的監督學習算法進行訓練,得到模型后,為客戶推薦偏好的內容,如頭條的話,就是咨詢和文章,美團的就是生活服務內容。
可選擇的模型很多,如協同過濾,邏輯斯蒂回歸,基于DNN的模型,FM等。我們使用的方式是,基于內容相似度計算進行召回,之后通過FM模型和邏輯斯蒂回歸模型進行精排推薦,下面就分別說一下,我們做這個電影推薦系統過程中,從數據準備,特征工程,到模型訓練和應用的整個過程。
我們實現的這個電影推薦系統,爬取的數據實際上維度是相對少的,特別是用戶這一側的維度,正常推薦系統涉及的維度,諸如頁面停留時間,點擊頻次,收藏等這些維度都是沒有的,以及用戶本身的維度也相對要少,沒有地址、年齡、性別等這些基本的維度,這樣我們爬取的數據只有打分和評論這些信息,所以之后我們又從這些信息里再拿出一些統計維度來用。我們爬取的電影數據(除電影詳情和圖片信息外)是如下這樣的形式:
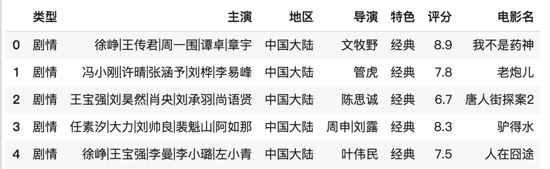
這里的數據是有冗余的,又通過如下的代碼,對數據進行按維度合并,去除冗余數據條目:
# 處理主函數,負責將多個冗余數據合并為一條電影數據,將地區,導演,主演,類型,特色等維度數據合并
def mainfunc():
try:
unable_list = []
with connection.cursor() as cursor:
sql='select id,name from movie'
cout=cursor.execute(sql)
print("數量: "+str(cout))
for row in cursor.fetchall():
#print(row[1])
movieinfo = df[df['電影名'] == row[1]]
if movieinfo.shape[0] == 0:
disable_movie(row[0])
print('disable movie ' + str(row[1]))
else:
g = lambda x:movieinfo[x].iloc[0]
types = movieinfo['類型'].tolist()
types = reduce(lambda x,y:x+'|'+y,list(set(types)))
traits = movieinfo['特色'].tolist()
traits = reduce(lambda x,y:x+'|'+y,list(set(traits)))
update_one_movie_info(type_=types, actors=g('主演'), region=g('地區'), director=g('導演'), trait=traits, rat=g('評分'), id_=row[0])
connection.commit()
finally:
connection.close()
之后開始準備用戶數據,我們從用戶打分的數據中,統計出每一個用戶的打分的最大值,最小值,中位數值和平均值等,從而作為用戶的一個附加屬性,存儲于userproex表中:
'insert into userproex(userid, rmax, rmin, ravg, rcount, rsum, rmedian) values(\'%s\', %s, %s, %s, %s, %s, %s)' % (userid, rmax, rmin, ravg, rcount, rsum, rmedium) 'update userproex set rmax=%s, rmin=%s, ravg=%s, rmedian=%s, rcount=%s, rsum=%s where userid=\'%s\'' % (rmax, rmin, ravg, rmedium, rcount, rsum, userid)
以上兩個SQL是最終插入表的時候用到的,代表準備用戶數據的最終步驟,其余細節可以參考文末的github倉庫,不在此贅述,數據處理還用到了一些SQL,以及其他處理細節。
系統上線運行時,第一次是全量的數據處理,之后會是增量處理過程,這個后面還會提到。
我們目前把用戶數據和電影的數據的原始數據算是準備好了,下一步開始特征工程。做特征工程的思路是,對type, actors, director, trait四個類型數據分別構建一個頻度統計字典,用于之后的one-hot編碼,代碼如下:
def get_dim_dict(df, dim_name):
type_list = list(map(lambda x:x.split('|') ,df[dim_name]))
type_list = [x for l in type_list for x in l]
def reduce_func(x, y):
for i in x:
if i[0] == y[0][0]:
x.remove(i)
x.append(((i[0],i[1] + 1)))
return x
x.append(y[0])
return x
l = filter(lambda x:x != None, map(lambda x:[(x, 1)], type_list))
type_zip = reduce(reduce_func, list(l))
type_dict = {}
for i in type_zip:
type_dict[i[0]] = i[1]
return type_dict
涉及到的冗余數據也要刪除
df_ = df.drop(['ADD_TIME', 'enable', 'rat', 'id', 'name'], axis=1)
將電影數據轉換為字典列表,由于演員和導演均過萬維,實際計算時過于稀疏,當演員或導演只出現一次時,標記為冷門演員或導演
movie_dict_list = []
for i in df_.index:
movie_dict = {}
#type
for s_type in df_.iloc[i]['type'].split('|'):
movie_dict[s_type] = 1
#actors
for s_actor in df_.iloc[i]['actors'].split('|'):
if actors_dict[s_actor] < 2:
movie_dict['other_actor'] = 1
else:
movie_dict[s_actor] = 1
#regios
movie_dict[df_.iloc[i]['region']] = 1
#director
for s_director in df_.iloc[i]['director'].split('|'):
if director_dict[s_director] < 2:
movie_dict['other_director'] = 1
else:
movie_dict[s_director] = 1
#trait
for s_trait in df_.iloc[i]['trait'].split('|'):
movie_dict[s_trait] = 1
movie_dict_list.append(movie_dict)
使用DictVectorizer進行向量化,做One-hot編碼
v = DictVectorizer() X = v.fit_transform(movie_dict_list)
這樣的數據,下面做余弦相似度已經可以了,這是特征工程的基本的一個處理,模型所使用的數據,需要將電影,評分,用戶做一個數據拼接,構建訓練樣本,并保存CSV,注意這個CSV不用每次全量構建,而是除第一次外都是增量構建,通過mqlog中類型為'c'的消息,增量構建以comment(評分)為主的訓練樣本,拼接之后的形式如下:
USERID cf2349f9c01f9a5cd4050aebd30ab74f movieid 10533913 type 劇情|奇幻|冒險|喜劇 actors 艾米·波勒|菲利絲·史密斯|理查德·坎德|比爾·哈德爾|劉易斯·布萊克 region 美國 director 彼特·道格特|羅納爾多·德爾·卡門 trait 感人|經典|勵志 rat 8.7 rmax 5 rmin 2 ravg 3.85714 rcount 7 rmedian 4 TIME_DIS 15
這個數據的actors等字段和上面的處理是一樣的,為了之后libfm的使用,在這里需要轉換為libsvm的數據格式
dump_svmlight_file(train_X_scaling, train_y_, train_file)
模型使用上遵循先召回,后精排的策略,先通過余弦相似度計算一個相似度矩陣,然后根據這個矩陣,為用戶推薦相似的M個電影,在通過訓練好的FM,LR模型,對這個M個電影做偏好預估,FM會預估一個用戶打分,LR會預估一個點擊概率,綜合結果推送給用戶作為推薦電影。
模塊列表
為了能夠輸出一個可感受的系統,我們采購了阿里云服務器作為數據庫服務器和應用服務器,在線上搭建了電影推薦系統的第一版,地址是:
www.technologyx.cn
可以注冊,也可以使用已有用戶:
| 用戶名 | 密碼 |
|---|---|
| gavin | 123 |
| gavin2 | 123 |
| wuenda | 123 |
歡迎登錄使用感受一下。

設計思路
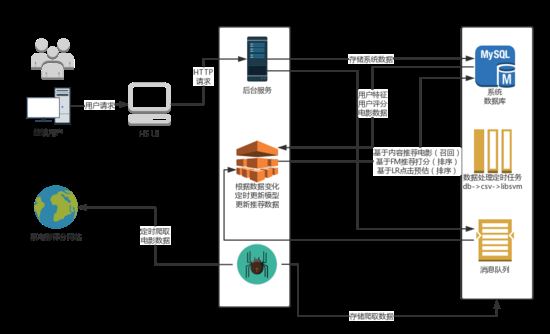
用簡單地方式表述一下設計思路,
1.后端服務recsys_web依賴于系統數據庫的推薦表‘recmovie'展示給用戶推薦內容
2.用戶對電影打分后(暫時沒有對點擊動作進行響應),后臺應用會向mqlog表插入一條數據(消息)。
3.新用戶注冊,系統會插入mqlog中一條新用戶注冊消息
4.新電影添加,系統會插入mqlog中一條新電影添加消息
5.推薦模塊recsys_core會拉取用戶的打分消息,并且并行的做以下操作:
a.增量的更新訓練樣本
b.快速(因服務器比較卡,目前設定了延時)對用戶行為進行基于內容推薦的召回
c.訓練樣本更新模型
d.使用FM,LR模型對Item based所召回的數據進行精排
e.處理新用戶注冊消息,監聽到用戶注冊消息后,對該用戶的屬性初始化(統計值)。
f.處理新電影添加消息,更新基于內容相似度而生成的相似度矩陣
注:
由于線上資源匱乏,也不想使系統增加復雜度,所以沒有直接使用MQ組件,而是以數據庫表作為代替。
項目源碼地址: https://github.com/GavinHacker/recsys_core
模型相關的模塊介紹
增量的處理用戶comment,即增量處理評分模塊
這個模塊負責監聽來自mqlog的消息,如果消息類型是用戶的新的comment,則對消息進行拉取,并相應的把新的comment合并到總的訓練樣本集合,并保存到一個臨時目錄
然后更新數據庫的config表,把最新的樣本集合(csv格式)的路徑更新上去
運行截圖
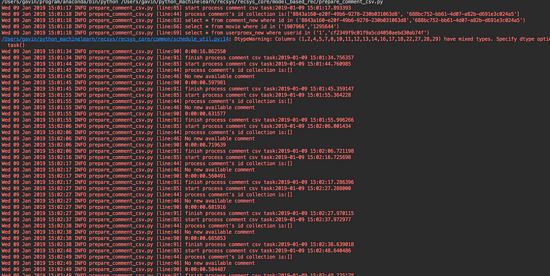
消息隊列的截圖
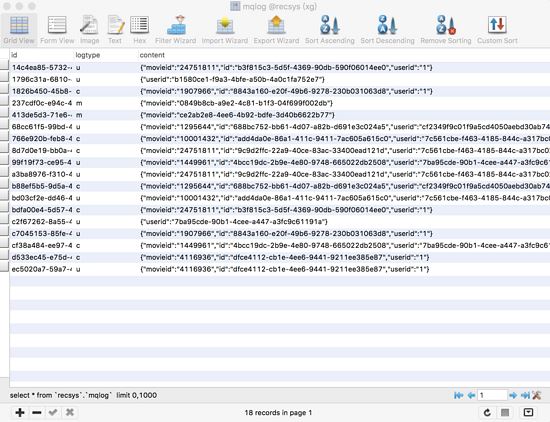
把csv處理為libsvm數據
這個模塊負責把最新的csv文件,異步的處理成libSVM格式的數據,以供libFM和LR模型使用,根據系統的性能確定任務的間隔時間
運行截圖
基于內容相似度推薦
當監聽到用戶有新的comment時,該模塊將進行基于內容相似度的推薦,并按照電影評分推薦
運行截圖

libFM預測
http://www.libfm.org/
對已有的基于內容推薦召回的電影進行模型預測打分,呈現時按照打分排序
如下圖為打分更新
邏輯回歸預測
對樣本集中的打分做0,1處理,根據正負樣本平衡,> 3分為喜歡 即1, <=3 為0 即不喜歡,這樣使用邏輯回歸做是否喜歡的點擊概率預估,根據概率排序
項目源碼地址: https://github.com/GavinHacker/recsys_core
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





