溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
前言:
在做一個商城項目的時候,需要實現商品搜索功能。
說到搜索,第一時間想到的是數據庫的 select * from tb_sku where name like %蘋果手機%
或者django的 SKU.objects.filter(name__contains="蘋果手機")
但是,假如你的數據庫有幾千萬條數據,name字段沒有索引,可能查詢需要十幾分鐘,用戶可能會等你?那為什么不給name字段增加索引?商品表不僅僅是用來查詢,也會經常修改數據,新增刪除數據等。建立索引后,做增刪改操作時也會大大占用數據庫資源。所以應該怎么解決呢?
Elasticsearch!
一個強大的基于Lucene的全文搜索服務器!維基百科、Stack Overflow、Github都在用。
如果想詳細了解其原理的話,可以參考:Elasticsearch 基礎介紹及索引原理分析
這里只是簡單說一下他的原理。
Elasticsearch原理:
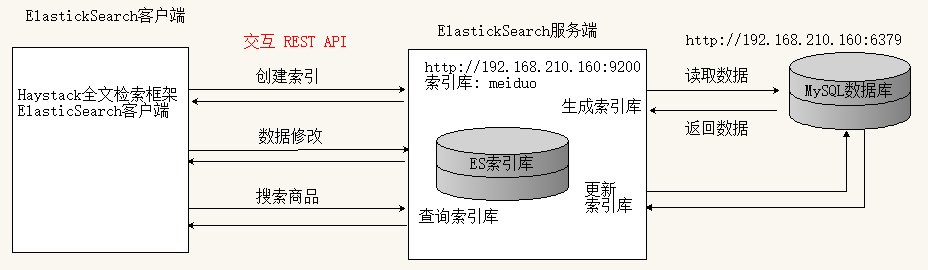
部署好ElasticSearch服務器后,剛開始需要創建索引,ES索引庫會對數據庫中的數據進行一遍預處理,單獨建立起一份索引結構數據。
理解:
假如你的商品表里有這幾個字段。id,名字,副標題,價格,商品圖片鏈接地址,評論數,是否上架。
一般用戶會根據名字或者副標題來搜索。此時名字、副標題這個字段就需要建立索引(當然,id也要,人家在mysql那里是主鍵總要給點面子吧)。但是后端返回給前端的數據,不僅僅是需要名字、副標題啊。你還要價格什么的呢!所以我們還要指定需要的字段,不然直接找個名字或者副標題出來有什么用?
所以剛開始創建索引庫時,ElasticSearch服務端會根據我們指定要作為索引的字段(名字、副標題、id)、要返回的字段(價格...),同步一份到ES索引庫里面。為什么要同步到elasticsearch?因為查找快呀。至于為什么ElasticSearch查找這么快,可以參考一下上面鏈接的原理。
注意上面的圖,ElasticSearch是C/S架構的軟件。下面說一下,服務端怎么搭建?
ElasticSearch服務端的搭建:
在搭建前說下,ElasticSearch建立索引時會分詞。什么是分詞呢?例如“我今天吃了一個漢堡包”。分詞后是“我”、“今天”、“吃了”、“一個”、“漢堡包”。你以為ElasticSearch會這么智能?沒錯,它對英文是這么智能,但是對我們的中文,只會分成“我”、“今”、“天”、“吃”、“了”、“一”、“個”、“漢”、“堡”、“包”。這樣用戶還怎么搜索啊。。。所以我們需要一個在ElasticSearch服務端集成一個插件,ElasticSearch-ik插件。有了這個插件,真的可以這么智能了。
所以,帶有-ik插件的ElasticSearch服務端怎么裝呢?
太麻煩了,所以我選擇docker(滑稽.jpg)
(1)加載docker鏡像
sudo docker load -i elasticsearch-ik-2.4.6_docker.tar
(2)修改配置文件
elasticsearc-2.4.6/config/elasticsearch.yml第54行,更改ip地址為本機ip地址:
network.host: xxx.xxx.xxx.xxx
如果docker不是運行在開發環境的本機,可以設為0.0.0.0。表示允許所有ip訪問此服務器。
(3)運行容器
docker run -d -p 9200:9200 --network=host --name=elasticsearch -v /var/elasticsearch-2.4.6/config:/usr/share/elasticsearch/config delron/elasticsearch-ik:2.4.6-1.0
(4)測試ElasticSearch是否安裝成功
curl 'http://xxx.xxx.xxx.xxx:9200/' # IP地址是ElasticSearch的IP
如果測試成功,那么ElasticSearch服務器就已經全部搭建完畢啦,而且這個鏡像集中了-ik插件,支持中文分詞。搭建完服務端后,就要用客戶端了。
使用Haystack對接Elasticsearch客戶端:
如果直接在Django項目直接編寫代碼作為ElasticSearch的客戶端,比較復雜,所以借助第三方包Haystack來對接ELasticSearch的客戶端。而且使用了Haystack后,以后你換其他的全文搜索服務器時(雖然不太可能換),也不用修改Django項目已經寫好的代碼。
(1)安裝Haystack和ElasticSearch客戶端。
pip install drf-haystack # 因為該項目是用DRF寫的前后端分離,所以安裝的是drf-haystack。如果不用DRF的話,安裝的是django-haystack pip install elasticsearch==2.4.1
(2)配置
1.注冊應用
INSTALLED_APPS = [
...
'haystack',
...
]
2.在項目的配置文件中配置haystack
# 配置haystack全文檢索框架
HAYSTACK_CONNECTIONS = {
'default': {
'ENGINE': 'haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine',
# 此處為elasticsearch運行的服務器ip地址,端口號默認為9200
'URL': 'http://xxx.xxx.xxx.xxx:9200/',
# 指定elasticsearch建立的索引庫的名稱
'INDEX_NAME': 'meiduo',
},
}
# 當添加、修改、刪除數據時,自動更新索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
(3)創建索引類
創建索引類的目的是指定要保存的字段,ElasticSearch服務器會把mysql的這些字段的數據進行同步。方便查詢出來時進行返回。
# goods(應用名)/search_indexes.py # search_indexes名字不能改,固定
from haystack import indexes
from .models import SKU
class SKUIndex(indexes.SearchIndex, indexes.Indexable):
"""
SKU索引類
""" # text表示被查詢的字段,用戶搜索的是這些字段的值,具體被索引的字段寫在另一個文件里。
text = indexes.CharField(document=True, use_template=True)
# 保存在索引庫中的字段
id = indexes.IntegerField(model_attr='id')
name = indexes.CharField(model_attr='name')
price = indexes.DecimalField(model_attr='price')
default_image_url = indexes.CharField(model_attr='default_image_url')
comments = indexes.IntegerField(model_attr='comments')
def get_model(self):
"""返回建立索引的模型類"""
return SKU
def index_queryset(self, using=None):
"""返回要建立索引的數據查詢集"""
return self.get_model().objects.filter(is_launched=True)
(4)指定被索引的字段
# templates/search/indexes/goods(應用名)/sku_text.txt # 路徑和名字是固定的
{{ object.name }}
{{ object.caption }}
{{ object.id }}
(5)生成索引庫
python manage.py rebuild_index
此時,索引庫成功生成了。接下來就是后端接受用戶存過來的查詢參數,并返回相應的字段了。
完善后端:
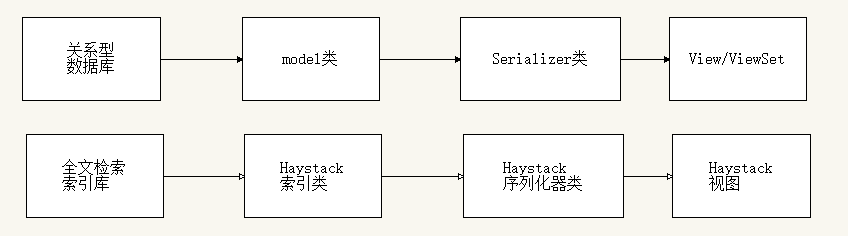
剛剛寫的SKUIndex可以當做是我們平時寫DRF時的model類,接下來還要寫序列化器,視圖,注冊路由。
(1)Haystack序列化器類
from drf_haystack.serializers import HaystackSerializer
class SKUIndexSerializer(HaystackSerializer):
"""
SKU索引結果數據序列化器
"""
class Meta:
index_classes = [SKUIndex]
fields = ('text', 'id', 'name', 'price', 'default_image_url', 'comments')
(2)Haystack視圖
from drf_haystack.viewsets import HaystackViewSet class SKUSearchViewSet(HaystackViewSet): # HaystackViewSet繼承了RetrieveModelMixin, ListModelMixin, ViewSetMixin, HaystackGenericAPIView,所以可以查一條或多條數據 """ SKU搜索 HaystackViewSet: 查一條,查多條 """ index_models = [SKU] serializer_class = SKUIndexSerializer
(3)注冊路由
router = DefaultRouter()
router.register('skus/search', views.SKUSearchViewSet, base_name='skus_search')
...
urlpatterns += router.urls
(4)訪問:127.0.0.1:8080/skus/search/?text=Apple
就可以查詢出帶有Apple的數據了~
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





