溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
我之前自己維護了一個公眾號,但因為個人關系很久沒有更新了,今天上來緬懷一下,卻偶然發現了一個獲取微信公眾號文章的方法。
之前獲取方法有很多,通過搜狗、清博、網頁端、客戶端等等都還可以,這個可能并沒有其他的優秀,但是操作簡單,很容易理解。
so、 首先需要有一個微信公眾平臺的賬號
微信公眾平臺:https://mp.weixin.qq.com/
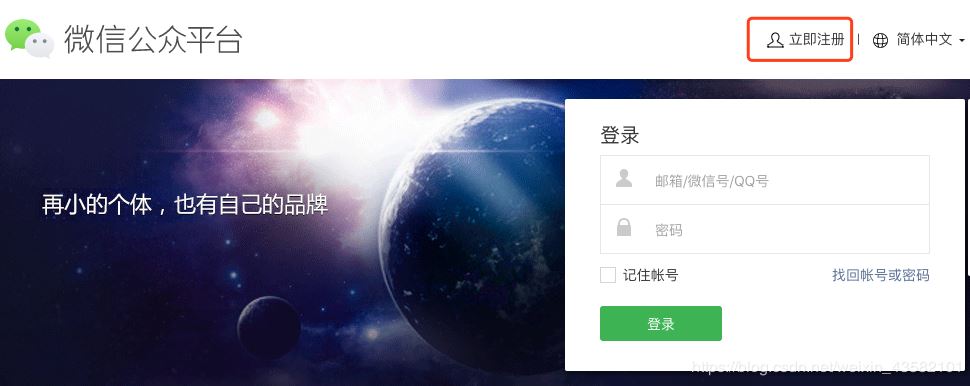
登陸之后,進入首頁,點擊新建群發。
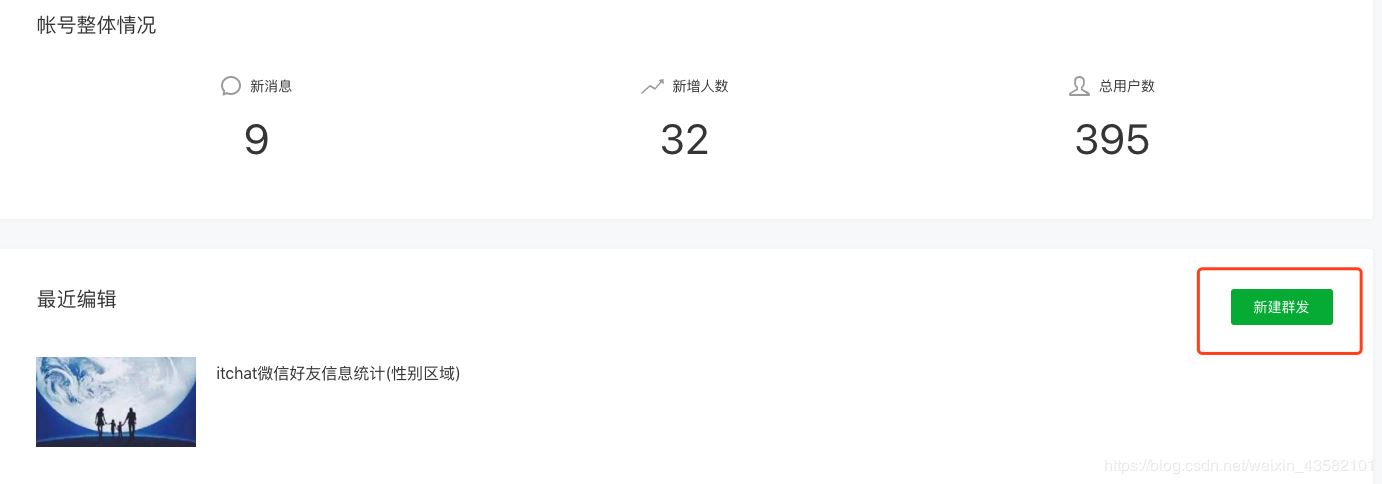
選擇自建圖文:
似乎像是公眾號運營教學了
進入編輯頁面之后,點擊超鏈接
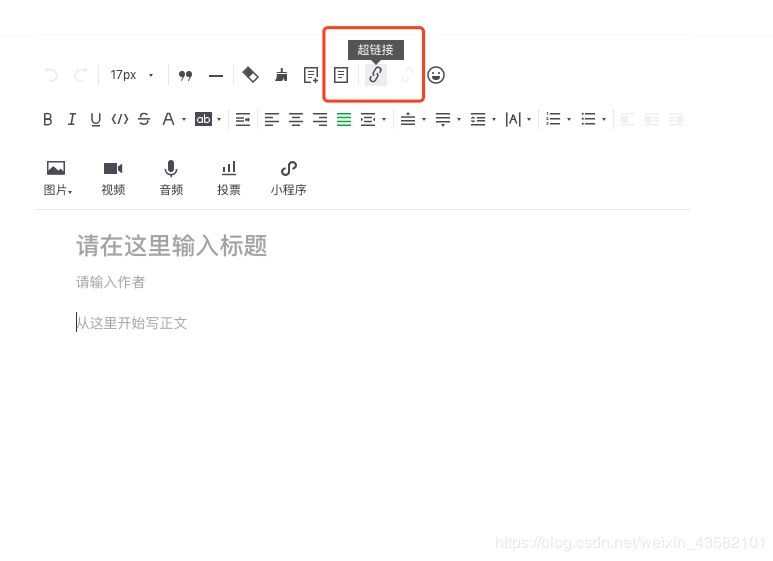
彈出選擇框,我們在框中輸入對應的公眾號名字,即可出現對應的文章列表
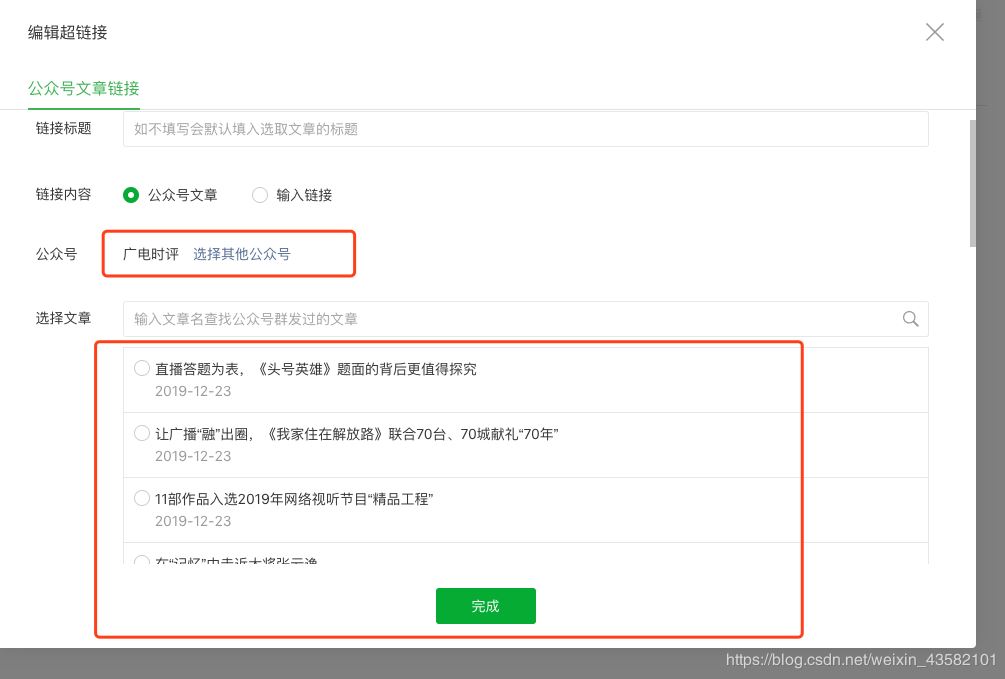
是不是很驚奇,可以打開控制臺,查看一下請求的接口
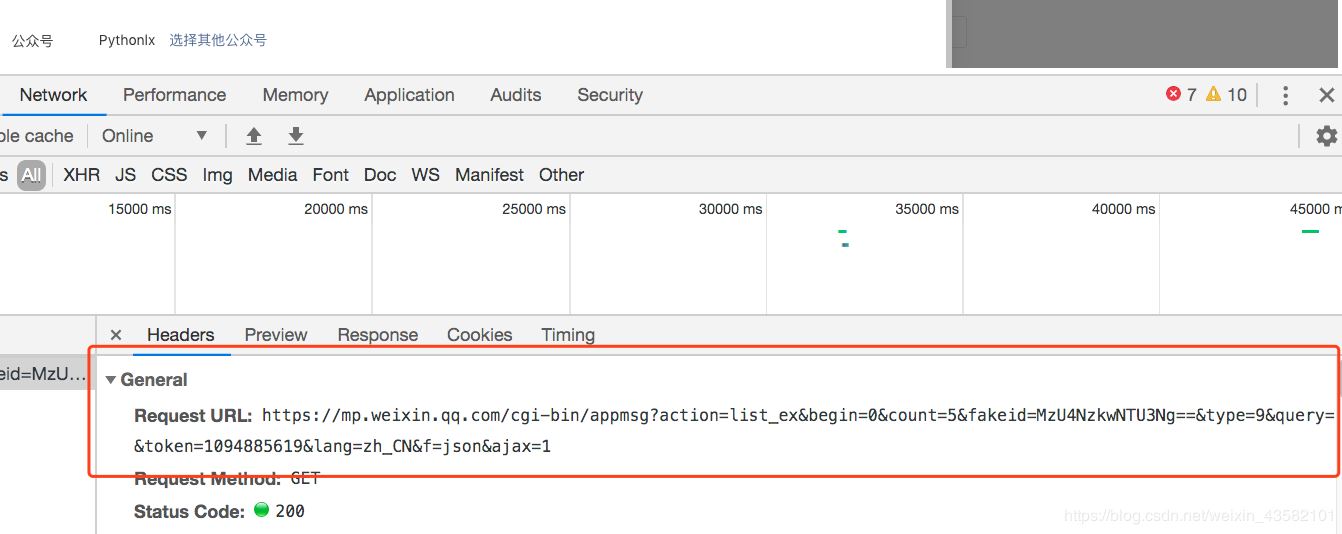
打開response,里面就是我們需要的文章鏈接

確定了數據以后,我們需要分析一下這個接口。
感覺很簡單,一個GET請求,攜帶一些參數。

fakeid是公眾號的獨有ID,所以想通過名字直接獲取文章列表,還需要先獲取一下fakeid。
當我們輸入公眾號名字后,點擊搜索。可以看到觸發了搜索接口,返回了fakeid。
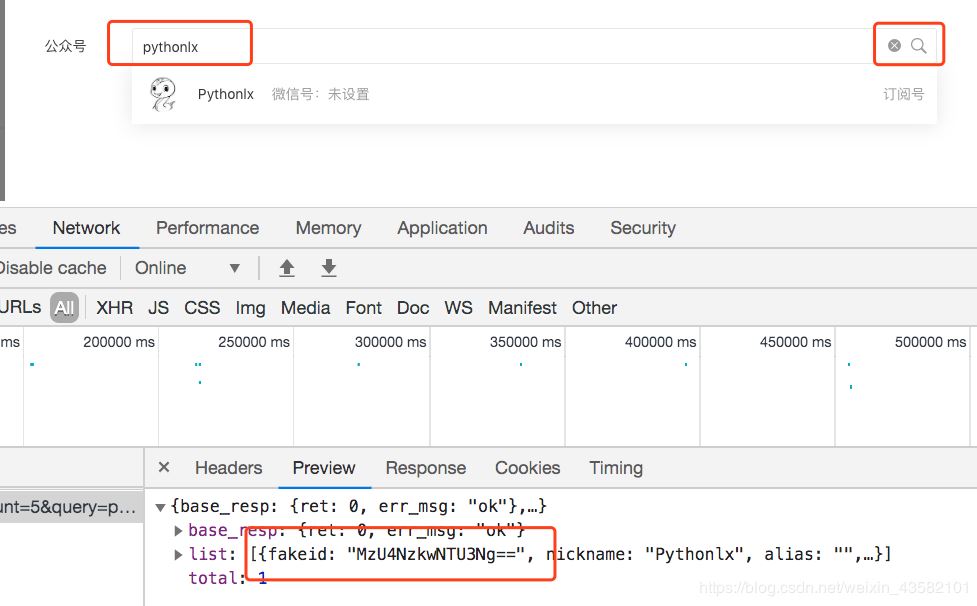
這個接口所需參數也不多。
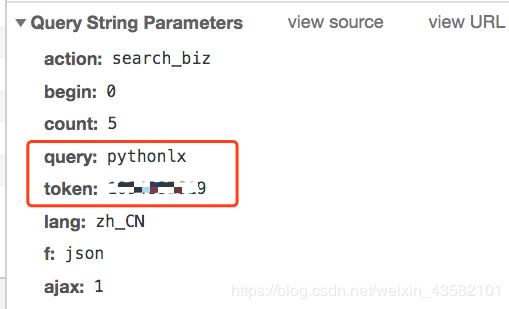
接下來,我們可以用代碼來模擬以上的操作了。
但是還需要使用現有Cookie避免登陸。
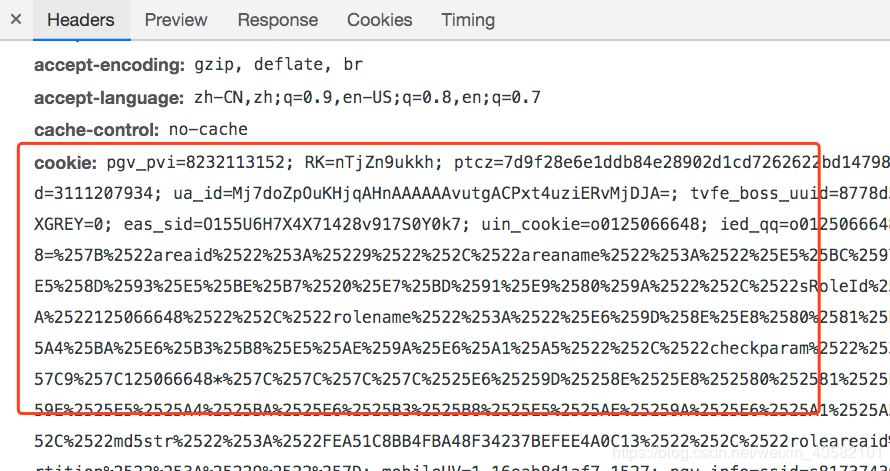
目前Cookie的有效期,我還沒有測試。可能需要及時更新Cookie。
測試代碼:
import requests
import json
Cookie = '請換上自己的Cookie,獲取方法:直接復制下來'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公眾號名字:可自定義
token = '你的token' # 獲取方法:如上述 直接復制下來
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
這樣就能獲取最新的10篇文章了,如果想要獲取更多的歷史文章,可以修改data中的"begin"參數,0是第一頁,5是第二頁,10是第三頁(以此類推)
但是如果想要大規模抓取的話:
請給自己安排一個穩定的代理,降低爬蟲的速度,準備多個賬號,來減少被封禁的可能性。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





