溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
下文給大家帶來Nginx的負載均衡策略及常用故障節點的摘除,希望能夠給大家在實際運用中帶來一定的幫助,負載均衡涉及的東西比較多,理論也不多,網上有很多書籍,今天我們就用億速云在行業內累計的經驗來做一個解答。
摘要:本文介紹了Nginx的負載均衡策略,一致性hash分配原理,及常用的故障節點的摘除與恢復配置。
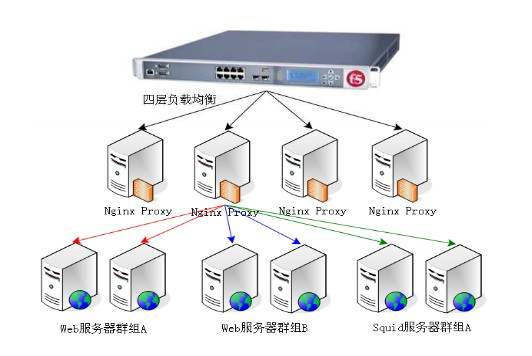
前篇Nginx專題(1):Nginx之反向代理及配置詳細介紹了Nginx功能之一——反向代理。本篇文章將重點介紹Nginx功能之二——負載均衡。
為了增加對負載均衡的好感,我們先了解負載均衡能實現什么。
下面正式進入主題。
負載均衡就是將請求“均衡”地分配到多臺業務節點服務器上。這里的“均衡”是依據實際場景和業務需要而定的。
對于Nginx來說,請求到達Nginx,Nginx作為反向代理服務器,有絕對的決策權,可以按照規則將請求分配給它知道的節點中的一個,通過這種分配,使得所有節點需要處理的請求量處于相對平均的狀態,從而實現負載均衡。
Nginx支持的負載均衡策略很多,比較重點的如下:
這么多的策略,非常不利于記憶和選擇,我們不妨將這些常見的策略歸類,分而化之,方便挑選。
最佳實踐,其實就是最常見、最普通的默認配置,當然也是在一定程度上最好用的配置。不知道用什么方式的時候,就可以選擇用這一類型。
輪詢不用多說。這里的隨機,其實在大量請求的情況下,按照概率的理論等同于輪詢的方式。
輪詢配置參考:
#默認配置就是輪詢策略
upstream server_group {
server backend1.example.com;
server backend2.example.com;
}隨機配置參考:
upstream server_group {
random;
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
server backend4.example.com;
}讓業務節點中性能更強的機器得到更多請求,這也是一個比較好的分配策略。
什么是性能更好的機器?這個問題也有很多的維度去考量。
權重的配置參考:
upstream server_group {
server backend1.example.com weight=5;
#默認為不配置權重為1
server backend2.example.com;
}響應的時長(fair)配置參考:需要在Nginx編譯時加入nginx-upstream-fair模塊。
upstream server_group{
fair;
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
server backend4.example.com;
}最少連接數(least_conn)配置參考:
upstream server_group {
least_conn;
server backend1.example.com;
server backend2.example.com;
}很多請求都是有狀態的,上一次請求到哪個業務節點,這次還要請求到哪臺機器。比如常見的session就是這樣一種有狀態的業務。
這里Nginx提供了按照客戶端ip的hash來作為用戶的標示分配、url的hash作為分配標示的規則。本質上還是要找到用戶的請求中不變的要素,抽離出來,這樣就可以進行分配了。
ip_hash配置參考:
upstream server_group {
ip_hash;
server backend1.example.com;
server backend2.example.com;
}url_hash配置參考:
upstream server_group{
hash $request_uri consistent;
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
server backend4.example.com;
}Nginx支持一致性hash進行分配,也就是配置中consistent。
什么是一致性hash?為什么要引入這個機制?在生產環境下,業務節點經常會出現增加或減少的情況,就算這種增加或減少都是被動的,也可能會對hash分配產生影響。如何能夠做到盡量減少影響呢?這時一致性hash被發明出來。
一致性hash解決兩個問題:
1)如何解決分配不均的問題
將原來的每一個節點復制出N個虛擬節點,并且給這些虛擬節點都起個名字。
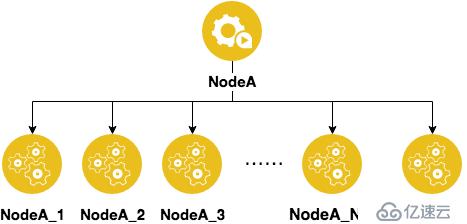
比如原來有5個節點,分配的時候經常會不均勻,現在每個節點都虛擬出N個節點,就是5*N個節點,會極大降低分配不均勻的情況。下面就要說說如何分配的問題了。
2)如何解決節點變動的問題
一致性哈希的基本思想:
如下圖。

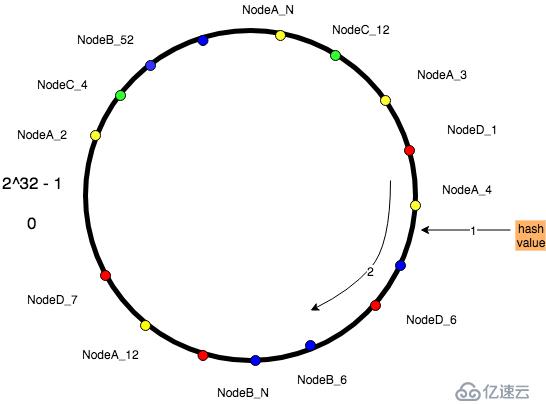
下面再來看節點的變化對一致性Hash的影響。
先看看經典配置,再詳細解釋。
upstream server_group {
server backend1.example.com ;
server backend2.example.com max_fails=3 fail_timeout=30s;
server backup1.example.com backup;
}這個參數決定了多少次請求后端失敗后會暫停這個業務節點,不再給它發新的請求,默認值是1。此參數需要配合fail_timeout一起用。
題外話:如何定義失敗,有很多種類型,這里因為主要處理HTTP代理,所以更關注proxy_next_upstream。
proxy_next_upstream:主要定義了當服務節點出現狀況時,會將請求發給其他節點,也就是定義了怎么算作業務節點失敗。
決定了當Nginx認定這個節點不可用時,暫停多久。不配置默認就是10s。
把上面兩個參數聯合起來考慮就是:當Nginx發現發送到這個節點上的請求失敗了3次的時候,就會把這個節點摘除,摘除時間是30s,30s后才會再次發送請求到這個節點上。
類似于switch語句中的default,當主要節點都掛了的時候,會把請求打到這個backup節點。這是最后一個救兵了。
看了以上Nginx的負載均衡策略及常用故障節點的摘除的解答,如果大家還有什么地方需要了解的可以在億速云行業資訊里查找自己感興趣的或者找我們的專業技術工程師解答的,億速云技術工程師在行業內擁有十幾年的經驗了。億速云官網鏈接www.neiyidaogou.com
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





