溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
我用的是Anaconda3 ,用spyder編寫pytorch的代碼,在Anaconda3中新建了一個pytorch的虛擬環境(虛擬環境的名字就叫pytorch)。
以下內容僅供參考哦~~
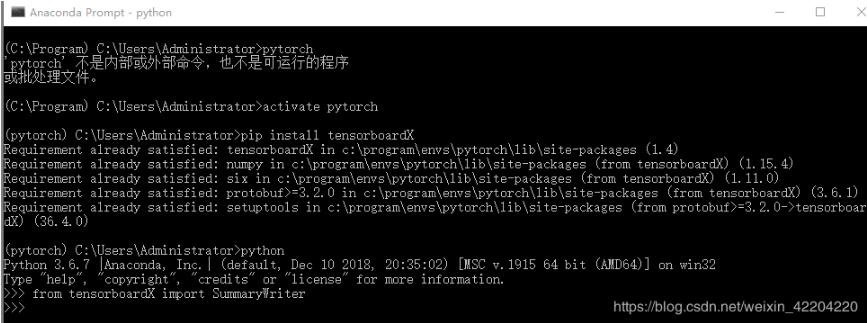
1.首先打開Anaconda Prompt,然后輸入activate pytorch,進入pytorch.
2.輸入pip install tensorboardX,安裝完成后,輸入python,用from tensorboardX import SummaryWriter檢驗是否安裝成功。如下圖所示:
3.安裝完成之后,先給大家看一下我的文件夾,如下圖:
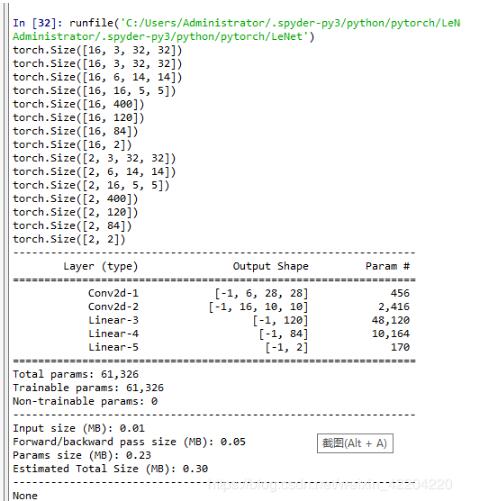
假設用LeNet5框架識別圖像的準確率,LeNet.py代碼如下:
import torch import torch.nn as nn from torchsummary import summary from torch.autograd import Variable import torch.nn.functional as F class LeNet5(nn.Module): #定義網絡 pytorch定義網絡有很多方式,推薦以下方式,結構清晰 def __init__(self): super(LeNet5,self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16*5*5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 2) def forward(self,x): # print(x.size()) x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) # print(x.size()) x = F.max_pool2d(F.relu(self.conv2(x)), 2) # print(x.size()) x = x.view(x.size()[0], -1)#全連接層均使用的nn.Linear()線性結構,輸入輸出維度均為一維,故需要把數據拉為一維 #print(x.size()) x = F.relu(self.fc1(x)) # print(x.size()) x = F.relu(self.fc2(x)) #print(x.size()) x = self.fc3(x) # print(x.size()) return x net = LeNet5() data_input = Variable(torch.randn(16,3,32,32)) print(data_input.size()) net(data_input) print(summary(net,(3,32,32)))
示網絡結構如下圖:
訓練代碼(LeNet_train_test.py)如下:
# -*- coding: utf-8 -*-
"""
Created on Wed Jan 2 15:53:33 2019
@author: Administrator
"""
import torch
import torch.nn as nn
import os
import numpy as np
import matplotlib.pyplot as plt
from torchvision import datasets,transforms
import torchvision
import LeNet
from torch import optim
import time
from torch.optim import lr_scheduler
from tensorboardX import SummaryWriter
writer = SummaryWriter('LeNet5')
data_transforms = {
'train':transforms.Compose([
#transforms.Resize(56),
transforms.RandomResizedCrop(32),#
transforms.RandomHorizontalFlip(),#已給定的概率隨即水平翻轉給定的PIL圖像
transforms.ToTensor(),#將圖片轉換為Tensor,歸一化至[0,1]
transforms.Normalize([0.485,0.456,0.406],[0.229, 0.224, 0.225])#用平均值和標準偏差歸一化張量圖像
]),
'val':transforms.Compose([
#transforms.Resize(56),
transforms.CenterCrop(32),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
]),
}
data_dir = 'bees vs ants' #樣本文件夾
image_datasets = {x:datasets.ImageFolder(os.path.join(data_dir,x),
data_transforms[x])
for x in ['train','val']
}
dataloaders = {x:torch.utils.data.DataLoader(image_datasets[x],batch_size =16,
shuffle = True,num_workers = 0)
for x in ['train','val']
}
dataset_sizes = {x:len(image_datasets[x]) for x in ['train','val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def imshow(inp,title = None):
#print(inp.size())
inp = inp.numpy().transpose((1,2,0))
mean = np.array([0.485,0.456,0.406])
std = np.array([0.229,0.224,0.225])
inp = std * inp + mean
inp = np.clip(inp,0,1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)#為了讓圖像更新可以暫停一會
#Get a batch of training data
inputs,classes = next(iter(dataloaders['train']))
#print(inputs.size())
#print(inputs.size())
#Make a grid from batch
out = torchvision.utils.make_grid(inputs)
#print(out.size())
imshow(out,title=[class_names[x] for x in classes])
def train_model(model,criterion,optimizer,scheduler,num_epochs = 25):
since = time.time()
# best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch,num_epochs - 1))
print('-' * 10)
#Each epoch has a training and validation phase
for phase in ['train','val']:
if phase == 'train':
scheduler.step()
model.train() #Set model to training mode
else:
model.eval()
running_loss = 0.0
running_corrects = 0
#Iterate over data
for inputs,labels in dataloaders[phase]:
inputs = inputs.to(device)
# print(inputs.size())
labels = labels.to(device)
#print(inputs.size())
# print(labels.size())
#zero the parameter gradients(參數梯度為零)
optimizer.zero_grad()
#forward
#track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_,preds = torch.max(outputs,1)
loss = criterion(outputs,labels)
#backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
#statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase,epoch_loss,epoch_acc))
writer.add_scalar('Train/Loss', epoch_loss,epoch)
writer.add_scalar('Train/Acc',epoch_acc,epoch)
else:
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase,epoch_loss,epoch_acc))
writer.add_scalar('Test/Loss', epoch_loss,epoch)
writer.add_scalar('Test/Acc',epoch_acc,epoch)
if epoch_acc > best_acc:
best_acc = epoch_acc
print()
writer.close()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60 , time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
#load best model weights
#model.load_state_dict()#best_model_wts)
return model
def visualize_model(model,num_images = 6):
was_training = model.training
model.eval()
images_so_far = 0
plt.figure()
with torch.no_grad():
for i,(inputs,labels) in enumerate(dataloaders['val']):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_,preds = torch.max(outputs,1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images //2,2,images_so_far)
ax.axis('off')
ax.set_title('predicted: {}'.format(class_names[preds[j]]))
imshow(inputs.cpu().data[j])
if images_so_far == num_images:
model.train(mode = was_training)
return
model.train(mode=was_training)
net = LeNet.LeNet5()
net = net.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(),lr = 0.001,momentum = 0.9)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer,step_size = 7,gamma = 0.1)
net = train_model(net,criterion,optimizer,exp_lr_scheduler,num_epochs = 25)
#net1 = train_model(net,criterion,optimizer,exp_lr_scheduler,num_epochs = 25)
visualize_model(net)
plt.ioff()
plt.show()
最終的二分類結果為:
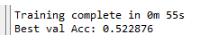
樣本圖像是pytorch官網中介紹遷移學習時用到的,螞蟻與蜜蜂的二分類圖像,圖像大小不一。LeNet5 的輸入圖像是32*32,所以進行分類時會損失一定的圖像像素,導致識別率較低。
下面介紹顯示loss和acc曲線,在以上訓練代碼中,writer = SummaryWriter('LeNet5'),表示在訓練過程中會生成LeNet5文件夾,保存loss曲線和acc曲線的文件,如下圖:
首先解釋一下這個文件夾為什么是1,因為我之前訓練了很多次,在LeNet5文件夾下有很多1文件夾中這樣的文件,待會用Anaconda Prompt來顯示loss和acc的時候,它只識別一個文件,所以我就重新建了一個1文件夾,并將剛剛運行完畢的文件放到文件夾中。在LeNet_train_test.py中, writer.add_scalar('Train/Loss', epoch_loss,epoch)和
writer.add_scalar('Train/Acc',epoch_acc,epoch),這兩行代碼就是生成train數據集的loss和acc曲線,同理測試數據集亦是如此。
好啦,下面開始顯示loss和acc:
1.打開Anaconda Prompt,再次進入pytorch虛擬環境,
2.輸入tensorboard --logdir=C:\Users\Administrator\.spyder-py3\python\pytorch\LeNet\LeNet5\1,紅色部分是來自上圖文件夾的根目錄,按回車鍵,會出現tensorboard的版本和一個網址,總體顯示效果如下圖:

復制網址到瀏覽器中,在此處是復制:http://8AEYUVZ5PNOFCBX:6006 到瀏覽器中,

最終結果如下圖:
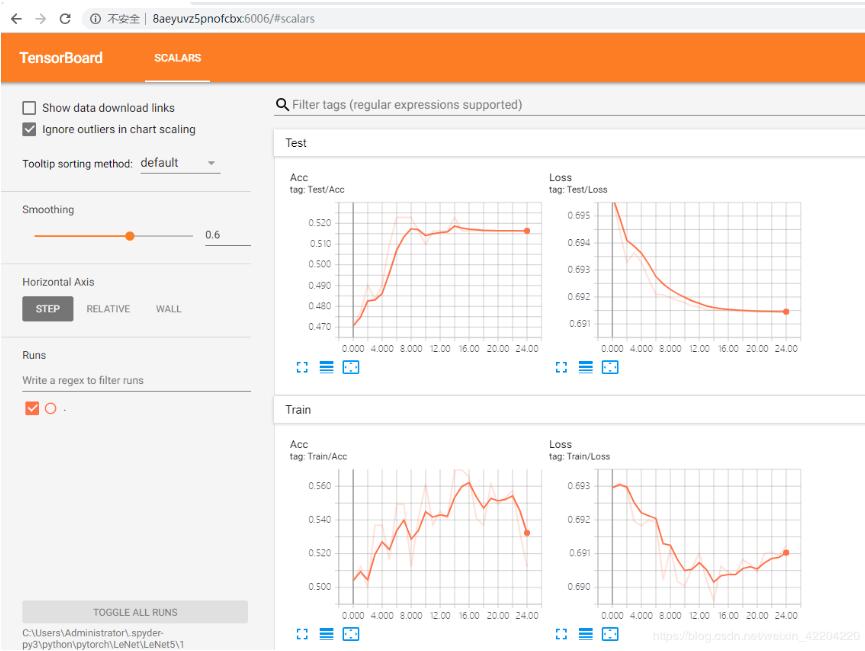
好啦,以上就是如何顯示loss曲線和acc曲線以及LeNet5模型建立及訓練的過程啦。
如果,文中有哪些地方描述的不恰當,請大家批評指正,不喜歡也不要噴我,好不好~~~
以上這篇pytorch繪制并顯示loss曲線和acc曲線,LeNet5識別圖像準確率就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





