溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關怎么在Python中使用py2neo操作neo4j數據庫,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
圖:數據結構中的圖由節點和其之間的邊組成。節點表示一個實體,邊表示實體之間的聯系。
圖數據庫:以圖的結構存儲管理數據的數據庫。其中一些數據庫將原生的圖結構經過優化后直接存儲,即原生圖存儲。還有一些圖數據庫將圖數據序列化后保存到關系型或其他數據庫中。
之所以使用圖數據庫存儲數據是因為它在處理實體之間存在復雜關系的數據具有很大的優勢。使用傳統的關系型數據庫在處理數據之間的關系時其實很不方便。例如查詢選修一個課程的同學時需要join兩個表,查詢選修某個課程的同學還選修什么課程,這就需要兩次join操作,當涉及到十分復雜的關系以及龐大的數據量時,關系型數據庫效率十分低下。而通過圖存儲,可以通過節點之間的邊十分便捷地查詢到結果。
圖模型:
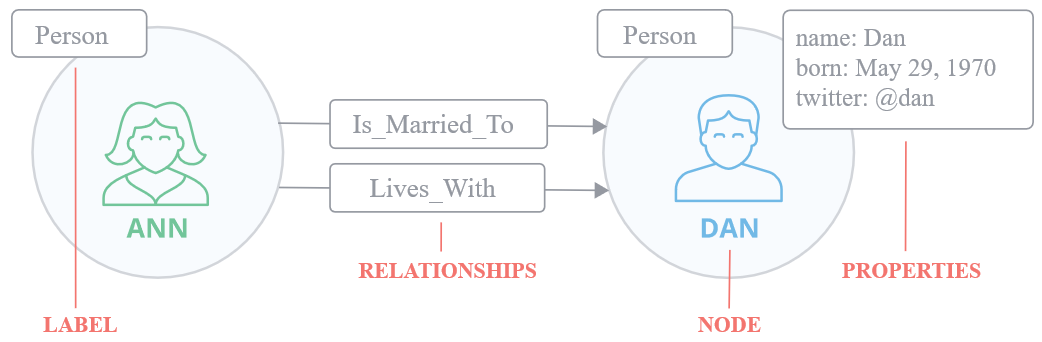
節點(Node)是主要的數據元素,表示一個實體。
屬性(Properties)用于描述實體的特征,以鍵值對的方式表示,其中鍵是字符串,可以對屬性創建索引和約束。
關系(Relationships)表示實體之間的聯系,關系具有方向,實體之間可以有多個關系,關系也可以具有屬性
標簽(Label)用于將實體分類,一個實體可以具有多個標簽,對標簽進行索引可以加速查找
Neo4j是目前最流行的圖數據庫,它采用原生圖存儲,在windows中下載安裝訪問如下地址https://neo4j.com/download/community-edition/。在Linux下通過如下命令下載解壓
curl -O http://dist.neo4j.org/neo4j-community-3.4.5-unix.tar.gz tar -axvf neo4j-community-3.4.5-unix.tar.gz
修改配置文件conf/neo4j.conf
# 修改第22行load csv時l路徑,在前面加個#,可從任意路徑讀取文件 #dbms.directories.import=import # 修改35行和36行,設置JVM初始堆內存和JVM最大堆內存 # 生產環境給的JVM最大堆內存越大越好,但是要小于機器的物理內存 dbms.memory.heap.initial_size=5g dbms.memory.heap.max_size=10g # 修改46行,可以認為這個是緩存,如果機器配置高,這個越大越好 dbms.memory.pagecache.size=10g # 修改54行,去掉改行的#,可以遠程通過ip訪問neo4j數據庫 dbms.connectors.default_listen_address=0.0.0.0 # 默認 bolt端口是7687,http端口是7474,https關口是7473,不修改下面3項也可以 # 修改71行,去掉#,設置http端口為7687,端口可以自定義,只要不和其他端口沖突就行 #dbms.connector.bolt.listen_address=:7687 # 修改75行,去掉#,設置http端口為7474,端口可以自定義,只要不和其他端口沖突就行 dbms.connector.http.listen_address=:7474 # 修改79行,去掉#,設置http端口為7473,端口可以自定義,只要不和其他端口沖突就行 dbms.connector.https.listen_address=:7473 # 去掉#,允許從遠程url來load csv dbms.security.allow_csv_import_from_file_urls=true # 修改250行,去掉#,設置neo4j-shell端口,端口可以自定義,只要不和其他端口沖突就行 dbms.shell.port=1337 # 修改254行,設置neo4j可讀可寫 dbms.read_only=false
在bin目錄下執行 ./neo4j start,啟動服務,在瀏覽器http://服務器ip地址:7474/browser/可以看到neo4j的可視化界面
py2neo是一個社區第三方庫,通過它可以更為便捷地使用python來操作neo4j
安裝py2neo:pip install py2neo,我安裝的版本是4.3.0
創建節點和它們之間的關系,注意在使用下面的py2neo相關類之前首先需要import導入:
# 引入庫
from py2neo import Node, Relationship
# 創建節點a、b并定義其標簽為Person,屬性name
a = Node("Person", name="Alice",height=166)
b = Node("Person", name="Bob")
# 節點添加標簽
a.add_label('Female')
# 創建ab之間的關系
ab = Relationship(a, "KNOWS", b)
# 輸出節點之間的關系:(Alice)-[:KNOWS]->(Bob)
print(ab)Node 和 Relationship 都繼承了 PropertyDict 類,類似于python的dictionary,可以通過如下方式對 Node 或 Relationship 進行屬性賦值和訪問
# 節點和關系添加、修改屬性
a['age']=20
ab['time']='2019/09/03'
# 刪除屬性
del a['age']
# 打印屬性
print(a[name])
# 設置默認屬性,如果沒有賦值,使用默認值,否則設置的新值覆蓋默認值
a.setdefault('sex','unknown')
# 更新屬性
a.update(age=22, sex='female')
ab.update(time='2019/09/03')由節點和關系組成的集合就是子圖,通過關系運算符求交集&、并集|、差集-、對稱差集^
subgraph.labels返回子圖中所有標簽集合,keys()返回所有屬性集合,nodes返回所有節點集,relationships返回所有關系集
# 構建一個子圖
s = a | b | ab
# 對圖中的所有節點集合進行遍歷
for item in s.nodes:
print('s的節點:', item)通常將圖中的所有節點和關系構成一個子圖后再統一寫入數據庫,與多次寫入單個節點相比效率更高
# 連接neo4j數據庫,輸入地址、用戶名、密碼
graph = Graph('http://localhost:7474', username='neo4j', password='123456')
# 將節點和關系通過關系運算符合并為一個子圖,再寫入數據庫
s=a | b | ab
graph.create(s)walkable是在子圖subgraph的基礎上增加了遍歷信息的對象,通過它可以便捷地遍歷圖數據庫。
通過+號將關系連接起來就構成了一個walkable對象。通過walk()函數對其進行遍歷,可以利用 start_node、end_node、nodes、relationships屬性來獲取起始 Node、終止 Node、所有 Node 和 Relationship
# 組合成一個walkable對象w
w = ab + bc + ac
# 對w進行遍歷
for item in walk(w):
print(item)
# 訪問w的初始、終止節點
print('起始節點:', w.start_node, ' 終止節點:', w.end_node)
# 訪問w的所有節點、關系列表
print('節點列表:', w.nodes)
print('關系列表:', w.relationships)運行結果為:
(:Person {age: 20, name: 'Bob'})
(Bob)-[:KNOWS {}]->(Alice)
(:Person {age: 21, name: 'Alice'})
(Alice)-[:LIKES {}]->(Mike)
(:Person {name: 'Mike'})
(Bob)-[:KNOWS {}]->(Mike)
(:Person {age: 20, name: 'Bob'})
起始節點: (:Person {age: 22, name: 'Bob', sex: 'female'}) 終止節點: (:Person {age: 22, name: 'Bob', sex: 'female'})
節點列表: ((:Person {age: 22, name: 'Bob', sex: 'female'}), (:Person {age: 21, name: 'Alice'}), (:Person {name: 'Mike'}), (:Person {age: 22, name: 'Bob', sex: 'female'}))
關系列表: ((Bob)-[:KNOWS {time: '2019/09/03'}]->(Alice), (Alice)-[:LIKES {}]->(Mike), (Bob)-[:KNOWS {}]->(Mike))
py2neo通過graph對象操作neo4j數據庫,目前的neo4j只支持一個數據庫定義一張圖
通過Graph的初始化函數完成對數據庫的連接并創建一個graph對象
graph.create()可以將子圖寫入數據庫,也可以一次只寫入一個節點或關系
graph.delete()刪除指定子圖,graph.delete_all()刪除所有子圖
graph.seperate()刪除指定關系
# 初始化連接neo4j數據庫,參數依次為url、用戶名、密碼
graph = Graph('http://localhost:7474', username='neo4j', password='123456')
# 寫入子圖w
graph.create(w)
# 刪除子圖w
graph.delete(w)
# 刪除所有圖
graph.delete_all()
# 刪除關系rel
graph.separate(rel)graph.match(nodes=None, r_type=None, limit=None)查找符合條件的關系,第一個參數為節點集合或者集合(起始節點,終止節點),如果省略代表所有節點。第二個參數為關系的屬性,第三個為返回結果的數量。也可以使用match_one()代替,返回一條結果。例如查找所有節點a認識的人:
# 查找所有以a為起點,并且屬性為KNOWS的關系 res = graph.match((a, ), r_type="KNOWS") # 打印關系的終止節點,即為a所有認識的人 for rel in res: print(rel.end_node["name"])
使用graph.nodes.match()查找指定節點,可以使用first()、where()、order_by()等函數對查找做高級限制
還可以通過節點或關系的id查找
# 查找標簽為Person,屬性name="Alice"的節點,并返回第一個結果
graph.nodes.match("Person", name="Alice").first()
# 查找所有標簽為Person,name以B開頭的節點,并將結果按照age字段排序
res = graph.nodes.match("Person").where("_.name =~ 'B.*'").order_by('_.age')
for node in res:
print(node['name'])
# 查找id為4的節點
t_node = graph.nodes[4]
# 查找id為196的關系
rel = graph.relationships[196]通過Graph對象進行Cypher操作并處理返回結果
graph.evaluate()執行一個Cypher語句并返回結果的第一條數據
# 執行Cypher語句并返回結果集的第一條數據
res = graph.evaluate('MATCH (p:Person) return p')
# 輸出:(_3:Person {age: 20, name: 'Bob'})
print(res)graph.run()執行Cypher語句并返回結果數據流的游標Cursor,通過forward()方法不斷向前移動游標可以向前切換結果集的每條記錄Record對象
# 查詢(p1)-[k]->(p2),并返回所有節點和關系 gql="MATCH (p1:Person)-[k:KNOWS]->(p2:Person) RETURN *" cursor=graph.run(gql) # 循環向前移動游標 while cursor.forward(): # 獲取并打印當前的結果集 record=cursor.current print(record)
打印的每條Record記錄對象如下所示,可以看到其中的元素是key=value的集合,通過方法get(key)可以取出具體元素。通過方法items(keys)可以將記錄中指定的key按(key,value)元組的形式返回
<Record k=(xiaowang)-[:KNOWS {}]->(xiaozhang) p1=(_96:Person {name: 'xiaowang'}) p2=(_97:Person {name: 'xiaozhang'})>
record = cursor.current
print('通過get返回:', record.get('k'))
for (key, value) in record.items('p1', 'p2'):
print('通過items返回元組:', key, ':', value)
# 運行結果如下
'''
通過get返回: (xiaowang)-[:KNOWS {}]->(xiaozhang)
通過items返回元組: p1 : (_92:Person {name: 'xiaowang'})
通過items返回元組: p2 : (_93:Person {name: 'xiaozhang'})
'''還可以將graph.run()返回的結果通過data()方法轉化為字典列表,所有結果整體上是一個列表,其中每一條結果是字典的格式,其查詢與結果如下,可以通過訪問列表與字典的方式獲取數據:
# 查詢(p1)-[k]->(p2),并返回所有節點和關系
gql = "MATCH (p1:Person)-[k:KNOWS]->(p2:Person) RETURN *"
res = graph.run(gql).data()
print(res)
#結果如下:
'''
[{'k': (xiaowang)-[:KNOWS {}]->(xiaozhang),
'p1': (_196:Person {name: 'xiaowang'}),
'p2': (_197:Person {name: 'xiaozhang'})},
{'k': (xiaozhang)-[:KNOWS {}]->(xiaozhao),
'p1': (_197:Person {name: 'xiaozhang'}),
'p2': (_198:Person {name: 'xiaozhao'})},
{'k': (xiaozhao)-[:KNOWS {}]->(xiaoli),
'p1': (_198:Person {name: 'xiaozhao'}),
'p2': (_199:Person {name: 'xiaoli'})}
]
'''通過graph.run().to_subgraph()方法將返回的結果轉化為SubGraph對象,接著按之前操作SubGraph對象的方法取得節點對象,這里的節點對象Node可以直接按照之前的Node操作
# 查詢(p1)-[k]->(p2),并返回所有節點和關系
gql = "MATCH (p1:Person)-[k:KNOWS]->(p2:Person) RETURN *"
sub_graph = graph.run(gql).to_subgraph()
# 獲取子圖中所有節點對象并打印
nodes=sub_graph.nodes
for node in nodes:
print(node)
# 輸出的節點對象如下:
'''
(_101:Person {name: 'xiaozhang'})
(_100:Person {name: 'xiaowang'})
(_103:Person {name: 'xiaoli'})
(_102:Person {name: 'xiaozhao'})
'''Object-Graph Mapping將圖數據庫中的節點映射為python對象,通過對象的方式對節點進行訪問和操作。
將圖中的每種標簽定義為一個python類,其繼承自GraphObject,注意使用前先import。在定義時可以指定數據類的主鍵,并定義類的屬性Property()、標簽Label()、關系RelatedTo()/RelatedFrom。
from py2neo.ogm import GraphObject, Property, RelatedTo, RelatedFrom, Label
class Person(GraphObject):
# 定義主鍵
__primarykey__ = 'name'
# 定義類的屬性
name=Property()
age=Property()
# 定義類的標簽
student=Label()
# 定義Person指向的關系
knows=RelatedTo('Person','KNOWS')
# 定義指向Person的關系
known=RelatedFrom('Person','KNOWN')通過類方法wrap()可以將一個普通節點轉化為類的對象。
類方法match(graph,primary_key)可以在graph中查找主鍵值為primary_key的節點
可以直接通過類構造方法創建一個對象,并直接訪問對象的屬性及方法,并通過關系方法add()添加關系
類的標簽是一個bool值,默認為False,將其修改為True,即可為對象添加標簽
# 將節點c轉化為OGM類型 c=Person.wrap(c) print(c.name) # 查找Person類中主鍵(name)為Alice的節點 ali=Person.match(graph,'Alice').first() # 創建一個新的Person對象并對其屬性賦值 new_person = Person() new_person.name = 'Durant' new_person.age = 28 # 標簽值默認為False print(new_person.student) # 修改bool值為True,為對象添加student標簽 new_person.student=True # 將修改后的圖寫入數據庫 graph.push(ali)
在定義節點類時還可以定義其相關的關系,例如通過RelatedTo()定義從該節點指出的關系,RelatedFrom()定義指向該節點的關系。通過對象調用關系的對應的方法完成節點周圍的關系操作,例如add()添加關系,clear()清除節點所有的關系,get()獲取關系屬性,remove()清楚指定的關系,update()更新關系
class Person(GraphObject):
# 定義Person指向的關系
knows=RelatedTo('Person','KNOWS')
# 定義指向Person的關系
known=RelatedFrom('Person','KNOWN')
# 新建一個從ali指向new_person的關系
ali.knows.add(new_person)
# 清除ali節點所有的know關系
ali.knows.clear()
# 清除ali節點指向new_person的那個know關系
ali.knows.remove(new_person)
# 更新ali指向new_person關系的屬性值
ali.knows.update(new_person,year=5)
# 獲取ali指向new_person關系的屬性year的值
ali.knows.get(new_person,'year')通過圖對象也可以調用match方法對節點、關系進行匹配
# 獲取第一個主鍵name名為Alice的Person對象
ali = Person.match(graph, 'Alice').first()
# 獲取所有name以B開頭的Person對象
Person.match(graph).where("_.name =~ 'B.*'")也可以通過圖graph對節點對象進行操作:
# 更新圖中ali節點的相關數據 graph.push(ali) # 用圖中的信息來更新ali節點 graph.pull(ali) # 刪除圖中的ali對象節點 graph.delete(ali)
關于怎么在Python中使用py2neo操作neo4j數據庫就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





