溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了Python中ADF單位根檢驗實現查看結果的方法,內容清晰明了,對此有興趣的小伙伴可以學習一下,相信大家閱讀完之后會有幫助。
如下所示:
from statsmodels.tsa.stattools import adfuller
print(adfuller(data))
(-8.14089819118415, 1.028868757881713e-12, 8, 442, {'1%': -3.445231637930579, '5%': -2.8681012763264233, '10%': -2.5702649212751583}, -797.2906467666614)
第一個是adt檢驗的結果,簡稱為T值,表示t統計量。
第二個簡稱為p值,表示t統計量對應的概率值。
第三個表示延遲。
第四個表示測試的次數。
第五個是配合第一個一起看的,是在99%,95%,90%置信區間下的臨界的ADF檢驗的值。
第一點,1%、%5、%10不同程度拒絕原假設的統計值和ADF Test result的比較,ADF Test result同時小于1%、5%、10%即說明非常好地拒絕該假設。本數據中,adf結果為-8, 小于三個level的統計值
第二點,p值要求小于給定的顯著水平,p值要小于0.05,等于0是最好的。本數據中,P-value 為 1e-15,接近0.
ADF檢驗的原假設是存在單位根,只要這個統計值是小于1%水平下的數字就可以極顯著的拒絕原假設,認為數據平穩。注意,ADF值一般是負的,也有正的,但是它只有小于1%水平下的才能認為是及其顯著的拒絕原假設。
對于ADF結果在1% 以上 5%以下的結果,也不能說不平穩,關鍵看檢驗要求是什么樣子的。
補充知識:python 編寫ADF 檢驗 ,代碼結果參數所表示的含義
我就廢話不多說了,大家還是直接看代碼吧!
from statsmodels.tsa.stattools import adfuller import numpy as np import pandas as pd adf_seq = np.array([1,2,3,4,5,7,5,1,54,3,6,87,45,14,24]) dftest = adfuller(adf_seq,autolag='AIC') dfoutput = pd.Series(dftest[0:4],index=['Test Statistic','p-value','#Lags Used','Number of Observations Used']) # 第一種顯示方式 for key,value in dftest[4].items(): dfoutput['Critical Value (%s)' % key] = value print(dfoutput) # 第二種顯示方式 print(dftest)
(1)第一種顯示方式如圖所示:
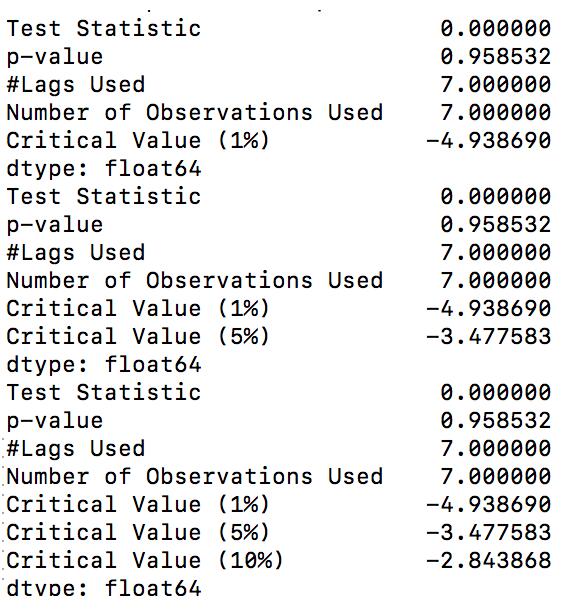
具體的參數含義如下所示:
Test Statistic : T值,表示T統計量
p-value: p值,表示T統計量對應的概率值
Lags Used:表示延遲
Number of Observations Used: 表示測試的次數
Critical Value 1% : 表示t值下小于 - 4.938690 , 則原假設發生的概率小于1%, 其它的數值以此類推。
其中t值和p值是最重要的,其實這兩個值是等效的,既可以看t值也可以看p值。
p值越小越好,要求小于給定的顯著水平,p值小于0.05,等于0最好。
t值,ADF值要小于t值,1%, 5%, 10% 的三個level,都是一個臨界值,如果小于這個臨界值,說明拒絕原假設。
其中,1% : 嚴格拒絕原假設; 5%: 拒絕原假設; 10% 以此類推,程度越來越低。如果,ADF小于1% level, 說明嚴格拒絕原假設。
(2)第二種表示方式,如下圖所示:
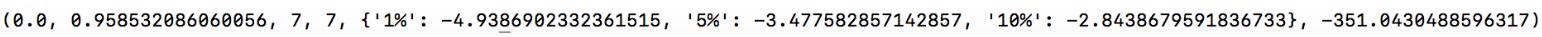
第一個值(0.0): 表示Test Statistic , 即T值,表示T統計量
第二個值(0.958532086060056):p-value,即p值,表示T統計量對應的概率值
第三個值(7):Lags Used,即表示延遲
第四個值(7):Number of Observations Used,即表示測試的次數
大括號中的值,分別表示1%, 5%, 10% 的三個level
查閱了資料,簡單的做的總結經驗。
看完上述內容,是不是對Python中ADF單位根檢驗實現查看結果的方法有進一步的了解,如果還想學習更多內容,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





