溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編這次要用代碼詳解tensorflow中dataset.shuffle、dataset.batch、dataset.repeat順序區別,文章內容豐富,感興趣的小伙伴可以來了解一下,希望大家閱讀完這篇文章之后能夠有所收獲。
1.作用
2.各種不同順序的區別
示例代碼(以下面代碼作為說明):
# -*- coding: utf-8 -*- import tensorflow as tf import numpy as np dataset = tf.data.Dataset.from_tensor_slices(np.arange(20).reshape((4, 5))) dataset = dataset.shuffle(100) dataset = dataset.batch(3) dataset = dataset.repeat(2) sess = tf.Session() iterator = dataset.make_one_shot_iterator() input_x = iterator.get_next() print(sess.run(input_x)) print(sess.run(input_x)) print(sess.run(input_x)) print(sess.run(input_x))
1.順序1(訓練過程最常用的順序)
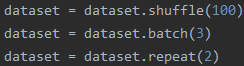
先看結果:
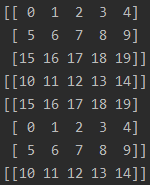
解釋:相當于把所有數據先打亂,然后打包成batch輸出,整體數據重復2個epoch
特點:1.一個batch中的數據不會重復;2.每個epoch的最后一個batch的尺寸小于等于batch_size
2.順序2
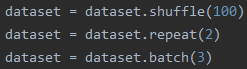
先看結果:
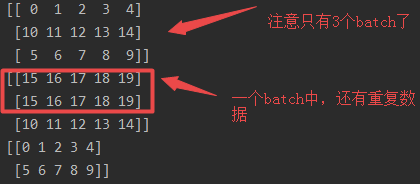
解釋:相當于把所有數據先打亂,再把所有數據重復兩個epoch,然后將重復兩個epoch的數據放在一起,最后打包成batch_size輸出
特點:1.因為把數據復制兩份,還進行打亂,因此某個batch數據可能會重復,而且出現重復數據的batch只會是兩個batch交叉的位置;2.最后一個batch的尺寸小于等于batch_size
3.順序3
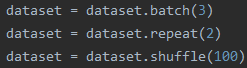
先看結果:
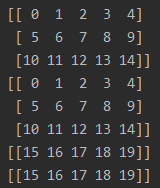
解釋:相當于把所有數據先打包成batch,然后把打包成batch的數據重復兩遍,最后再將所有batch打亂進行輸出
特點:1.打亂的是batch;2.某些batch的尺寸小于等于batch_size,因為是對batch進行打亂,所以這些batch不一定是最后一個
3.其他組合方式
根據上面幾種順序,大家可以自己分析其他順序的輸出結果
看完這篇關于用代碼詳解tensorflow中dataset.shuffle、dataset.batch、dataset.repeat順序區別的文章,如果覺得文章內容寫得不錯的話,可以把它分享出去給更多人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





