溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了Python爬蟲JSON及JSONPath的代碼實例詳解,內容清晰明了,對此有興趣的小伙伴可以學習一下,相信大家閱讀完之后會有幫助。
JSON(JavaScript Object Notation) 是一種輕量級的數據交換格式,它使得人們很容易的進行閱讀和編寫。同時也方便了機器進行解析和生成。適用于進行數據交互的場景,比如網站前臺與后臺之間的數據交互。
JsonPath 是一種信息抽取類庫,是從JSON文檔中抽取指定信息的工具,提供多種語言實現版本,包括:Javascript, Python, PHP 和 Java。
JsonPath 對于 JSON 來說,相當于 XPATH 對于 XML。
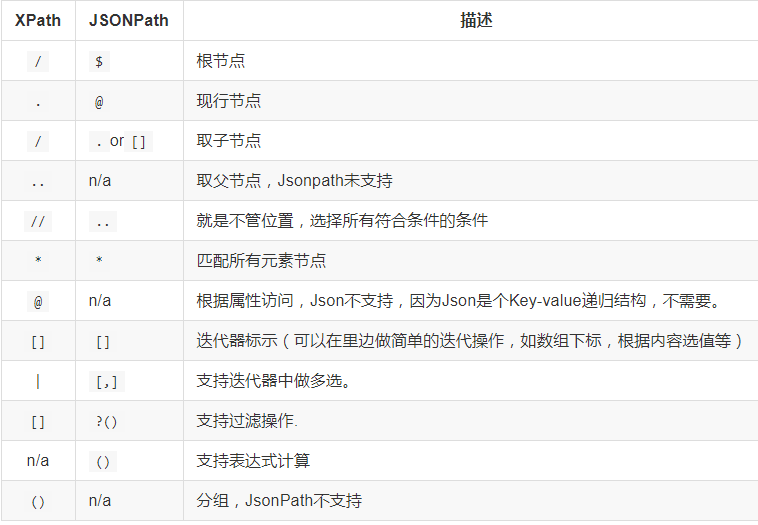
JsonPath與XPath語法對比:
Json結構清晰,可讀性高,復雜度低,非常容易匹配,下表中對應了XPath的用法。
相關推薦:《Python相關教程》
利用JSONPath爬取拉勾網上所有的城市
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import urllib2
# json解析庫,對應到lxml
import json
# json的解析語法,對應到xpath
import jsonpath
url = "http://www.lagou.com/lbs/getAllCitySearchLabels.json"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
request = urllib2.Request(url, headers = headers)
response = urllib2.urlopen(request)
# 取出json文件里的內容,返回的格式是字符串
html = response.read()
# 把json形式的字符串轉換成python形式的Unicode字符串
unicodestr = json.loads(html)
# Python形式的列表
city_list = jsonpath.jsonpath(unicodestr, "$..name")
#for item in city_list:
# print item
# dumps()默認中文為ascii編碼格式,ensure_ascii默認為Ture
# 禁用ascii編碼格式,返回的Unicode字符串,方便使用
array = json.dumps(city_list, ensure_ascii=False)
#json.dumps(city_list)
#array = json.dumps(city_list)
with open("lagoucity.json", "w") as f:
f.write(array.encode("utf-8"))結果:

糗事百科爬取
利用XPATH的模糊查詢
獲取每個帖子里的內容
保存到 json 文件內
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import urllib2
import json
from lxml import etree
url = "http://www.qiushibaike.com/8hr/page/2/"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
request = urllib2.Request(url, headers = headers)
html = urllib2.urlopen(request).read()
# 響應返回的是字符串,解析為HTML DOM模式 text = etree.HTML(html)
text = etree.HTML(html)
# 返回所有段子的結點位置,contains()模糊查詢方法,第一個參數是要匹配的標簽,第二個參數是標簽名部分內容
node_list = text.xpath('//div[contains(@id, "qiushi_tag")]')
items ={}
for node in node_list:
# xpath返回的列表,這個列表就這一個參數,用索引方式取出來,用戶名
username = node.xpath('./div/a/@title')[0]
# 取出標簽下的內容,段子內容
content = node.xpath('.//div[@class="content"]/span')[0].text
# 取出標簽里包含的內容,點贊
zan = node.xpath('.//i')[0].text
# 評論
comments = node.xpath('.//i')[1].text
items = {
"username" : username,
"content" : content,
"zan" : zan,
"comments" : comments
}
with open("qiushi.json", "a") as f:
f.write(json.dumps(items, ensure_ascii=False).encode("utf-8") + "
")看完上述內容,是不是對Python爬蟲JSON及JSONPath的代碼實例詳解有進一步的了解,如果還想學習更多內容,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





