溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
前言
今天開發同學向我們提了一個緊急的需求,從集合mt_resources_access_log中,根據字段refererDomain分組,取分組中最近一筆插入的數據,然后將這些符合條件的數據導入到集合mt_resources_access_log_new中。
接到這個需求,還是有些心虛的,原因有二,一是,業務需要,時間緊;二是,實現這個功能MongoDB聚合感覺有些復雜,聚合要走好多步。
數據記錄格式如下:
記錄1
{
"_id" : ObjectId("5c1e23eaa66bf62c0c390afb"),
"_class" : "C1",
"resourceUrl" : "/static/js/p.js",
"refererDomain" : "1234",
"resourceType" : "static_resource",
"ip" : "17.17.13.13",
"createTime" : ISODate("2018-12-22T19:45:46.015+08:00"),
"disabled" : 0
}
記錄2
{
"_id" : ObjectId("5c1e23eaa66bf62c0c390afb"),
"_class" : "C1",
"resourceUrl" : "/static/js/p.js",
"refererDomain" : "1234",
"resourceType" : "Dome_resource",
"ip" : "17.17.13.14",
"createTime" : ISODate("2018-12-21T19:45:46.015+08:00"),
"disabled" : 0
}
記錄3
{
"_id" : ObjectId("5c1e23eaa66bf62c0c390afb"),
"_class" : "C2",
"resourceUrl" : "/static/js/p.js",
"refererDomain" : "1235",
"resourceType" : "static_resource",
"ip" : "17.17.13.13",
"createTime" : ISODate("2018-12-20T19:45:46.015+08:00"),
"disabled" : 0
}
記錄4
{
"_id" : ObjectId("5c1e23eaa66bf62c0c390afb"),
"_class" : "C2",
"resourceUrl" : "/static/js/p.js",
"refererDomain" : "1235",
"resourceType" : "Dome_resource",
"ip" : "17.17.13.13",
"createTime" : ISODate("2018-12-20T19:45:46.015+08:00"),
"disabled" : 0
}
以上是我們的4條記錄,類似的記錄文檔有1500W。
因為情況特殊,業務發版需要這些數據。催的比較急,而 通過 聚合 框架aggregate,短時間有沒有思路, 所以,當時就想著嘗試采用其他方案。
最后,問題處理方案如下。
Step 1 通過聚合框架 根據條件要求先分組,并將新生成的數據輸出到集合mt_resources_access_log20190122 中(共產生95筆數據);
實現代碼如下:
db.log_resources_access_collect.aggregate(
[
{ $group: { _id: "$refererDomain" } },
{ $out : "mt_resources_access_log20190122" }
]
)
Step 2 通過2次 forEach操作,循環處理 mt_resources_access_log20190122和mt_resources_access_log的數據。
代碼解釋,處理的邏輯為,循環逐筆取出mt_resources_access_log20190122的數據(共95筆),每筆逐行加工處理,處理的邏輯主要是 根據自己的_id字段數據(此字段來自mt_resources_access_log聚合前的refererDomain字段), 去和 mt_resources_access_log的字段 refererDomain比對,查詢出符合此條件的數據,并且是按_id 倒序,僅取一筆,最后將Join刷選后的數據Insert到集合mt_resources_access_log_new。
新集合也是95筆數據。
大家不用擔心性能,查詢語句在1S內實現了結果查詢。
db.mt_resources_access_log20190122.find({}).forEach(
function(x) {
db.mt_resources_access_log.find({ "refererDomain": x._id }).sort({ _id: -1 }).limit(1).forEach(
function(y) {
db.mt_resources_access_log_new.insert(y)
}
)
}
)
Step 3 查詢驗證新產生的集合mt_resources_access_log_new,結果符合業務要求。
刷選前集合mt_resources_access_log的數據量為1500多W。
刷選后產生新的集合mt_resources_access_log_new 數據量為95筆。
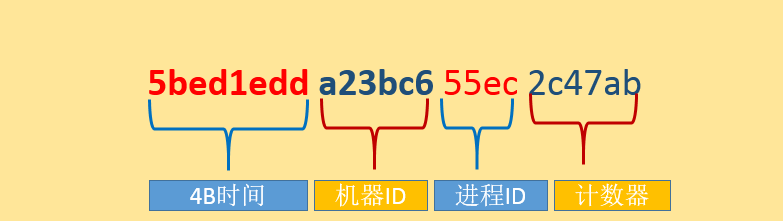
注意:根據時間排序的要求,因為部分文檔沒有createTime字段類型,且 createTime字段上沒有創建索引,所以未了符合按時間排序我們采用了sort({_id:1})的變通方法,因為_id 還有時間的意義。下面的內容為MongoDB對應_id 的相關知識。
最重要的是前4個字節包含著標準的Unix時間戳。后面3個字節是機器ID,緊接著是2個字節的進程ID。最后3個字節存儲的是進程本地計數器。計數器可以保證同一個進程和同一時刻內不會重復。
總結
以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作具有一定的參考學習價值,如果有疑問大家可以留言交流,謝謝大家對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





