溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
事故背景:一大早還在路上,群里陸續有人反饋系統一直報錯 “ Unknown error 258 ”,后來查詢日志發現錯誤日志

第一反應是不是數據庫連接不夠用了?導致超時?但是通過sql查詢當時連接也只有40個左右,于是繼續排查問題,發現dbserver機器這段時間磁盤io操作特別的高,很不正常,詳見下圖
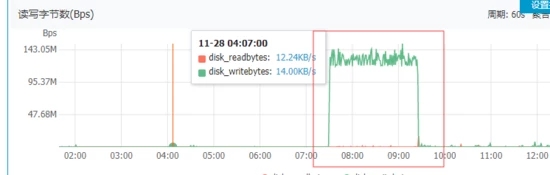
發現磁盤io問題,繼續查看sqlserver日志,發現原因: “Autogrow of file ‘xxxx_log' in database ‘xxxx' was cancelled by user or timed out after 3398 milliseconds. Use ALTER DATABASE to set a smaller FILEGROWTH value for this file or to explicitly set a new file size.”
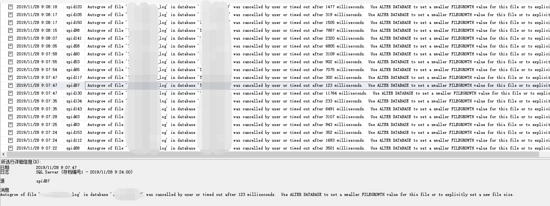
發現這種問題因為log日志文件太大了一直沒有壓縮過,并且創建數據庫的時候默認選擇了10%的增量來擴大log增量文件,這樣日志文件的10%會越來越大從而產生超時高io操作
解決方案:
1、定期清理log文件,防止log文件越來越大
USE [master] GO ALTER DATABASE 數據庫名 SET RECOVERY SIMPLE WITH NO_WAIT GO ALTER DATABASE 數據庫名 SET RECOVERY SIMPLE GO USE 數據庫名 GO DBCC SHRINKFILE (N'數據庫名_Log' , 11, TRUNCATEONLY) GO USE [master] GO ALTER DATABASE 數據庫名 SET RECOVERY FULL WITH NO_WAIT GO ALTER DATABASE 數據庫名 SET RECOVERY FULL GO
2、修改默認數據庫log增量10% 為 500M(看具體情況,一般夠了)
總結
以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作具有一定的參考學習價值,謝謝大家對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





