溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一、哈希和紅黑樹基本原理
哈希(hash)也稱散列,通過散列算法變成固定的輸出到數組,所有的線性數據結構中,數組的定位速度最快,因為它可通過數組下標直接定位到相應的數組空間,就不需要一個個查找。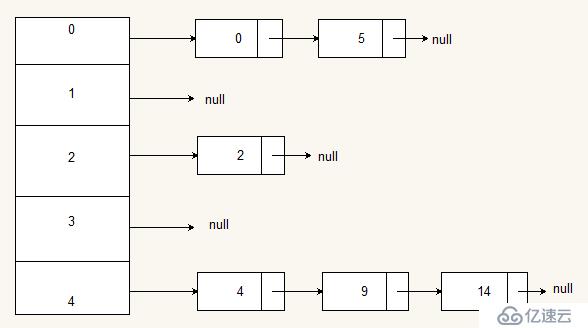
紅黑樹的自旋是天才的設計,是一種特殊的平衡二叉樹數據結構,特點也是從幾十萬的數據里面幾步就能查找到,速度快。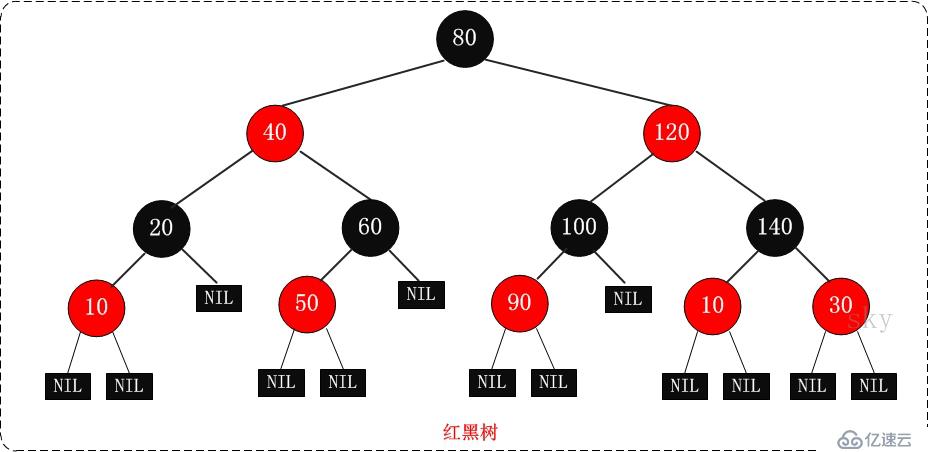
二、使用場景
1、速度對比
物聯網可能是數百萬設備或者用戶聯網,對高并發要求很大,所以,對網絡安全產品第一要求的是性能和速度。總體來說,哈希查找速度會比紅黑樹快,而且查找速度基本和數據量大小無關,屬于常數級別;而RB樹的查找速度是log(n)級別。
紅黑樹查找和刪除的時間復雜度都是O(logn),Hash查找和刪除的時間復雜度都是O(1)。 如果紅黑樹的樹高度不深如小于8,采用的是數字查找,兩者性能沒有太多的差異。
也就是并非所有的場景,哈希都比紅黑樹快,要看代碼的優化程度。hihttps使用的linux高并發EPOLL模式事件管理,就是紅黑樹。
2、數據預知
靜態數據,可以基本預知大小,用哈希。如t初始化的規則就幾百條在可控范圍內,另外TOPIC黑白名單、URL地址等也不會太多,也是用的哈希就可以了。
動態數據,如統計IP地址、任務調度、epoll高并發事件管理,無法判斷多少,可能很少,也可能巨多,用紅黑樹更佳。當然,如果大概知道設備IP地址數量在一定范圍,如只有幾千,完全也可以用哈希。
3、內存消耗
對內存要求嚴格的地方,如嵌入式系統,用紅黑樹。紅黑樹占用的內存更小(僅需要為其存在的節點分配內存),而哈希事先就應該分配足夠的內存存儲散列表,浪費內存。
對內存消耗無所謂的地方,如服務器有巨大的內存,用哈希。哈希最大的缺點是內存分配得小,可能元素就會沖突,沖突的元素大于8個成鏈表,效率還不如紅黑樹。 Java 的hashmap就是把哈希和紅黑樹結合在以前的。當同一個hash值的節點數不小于8時,不再采用單鏈表形式存儲,而是采用紅黑樹。
4 復雜程度
哈希更簡單,紅黑樹算法復雜一點,不過這都不是事,大神早開源了很多穩定的版本。
三、應用場景總結
紅黑樹是有序的,哈希是無序的,根據項目需求來選擇,阿里巴巴的很多項目用紅黑樹更多,筆者認為主要還是和內存有關,如果內存要求苛刻的項目,就用紅黑樹;如果內存足夠大,犧牲內存換取更快的速度,哈希完全適合。
Hiihttps開源waf大量采用哈希算法,可能和速度并發要求有關。總之,數據結構是網絡安全最基礎的學科。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





