溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹數據結構之一組圖讓你搞懂時間復雜度的案例,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
本篇文章中通過一組圖片讓你輕松明白什么是時間復雜度,有趣生動,具有一定學習價值,感興趣的朋友快來了解一下吧。







時間復雜度的意義
究竟什么是時間復雜度呢?讓我們來想象一個場景:某一天,小灰和大黃同時加入了一個公司......

一天過后,小灰和大黃各自交付了代碼,兩端代碼實現的功能都差不多。大黃的代碼運行一次要花100毫秒,內存占用5MB。小灰的代碼運行一次要花100秒,內存占用500MB。于是......


由此可見,衡量代碼的好壞,包括兩個非常重要的指標:
1.運行時間;
2.占用空間。



基本操作執行次數
關于代碼的基本操作執行次數,我們用四個生活中的場景,來做一下比喻:
場景1:給小灰一條長10寸的面包,小灰每3天吃掉1寸,那么吃掉整個面包需要幾天?

答案自然是 3 X 10 = 30天。
如果面包的長度是 N 寸呢?
此時吃掉整個面包,需要 3 X n = 3n 天。
如果用一個函數來表達這個相對時間,可以記作 T(n) = 3n。
場景2:給小灰一條長16寸的面包,小灰每5天吃掉面包剩余長度的一半,第一次吃掉8寸,第二次吃掉4寸,第三次吃掉2寸......那么小灰把面包吃得只剩下1寸,需要多少天呢?
這個問題翻譯一下,就是數字16不斷地除以2,除幾次以后的結果等于1?這里要涉及到數學當中的對數,以2位底,16的對數,可以簡寫為log16。
因此,把面包吃得只剩下1寸,需要 5 X log16 = 5 X 4 = 20 天。
如果面包的長度是 N 寸呢?
需要 5 X logn = 5logn天,記作 T(n) = 5logn。
場景3:給小灰一條長10寸的面包和一個雞腿,小灰每2天吃掉一個雞腿。那么小灰吃掉整個雞腿需要多少天呢?

答案自然是2天。因為只說是吃掉雞腿,和10寸的面包沒有關系 。
如果面包的長度是 N 寸呢?
無論面包有多長,吃掉雞腿的時間仍然是2天,記作 T(n) = 2。
場景4:給小灰一條長10寸的面包,小灰吃掉第一個一寸需要1天時間,吃掉第二個一寸需要2天時間,吃掉第三個一寸需要3天時間.....每多吃一寸,所花的時間也多一天。那么小灰吃掉整個面包需要多少天呢?
答案是從1累加到10的總和,也就是55天。
如果面包的長度是 N 寸呢?
此時吃掉整個面包,需要 1+2+3+......+ n-1 + n = (1+n)*n/2 = 0.5n^2 + 0.5n。
記作 T(n) = 0.5n^2 + 0.5n。

上面所講的是吃東西所花費的相對時間,這一思想同樣適用于對程序基本操作執行次數的統計。剛才的四個場景,分別對應了程序中最常見的四種執行方式:
場景1:T(n) = 3n,執行次數是線性的。
void eat1(int n){
for(int i=0; i<n; i++){;
System.out.println("等待一天");
System.out.println("等待一天");
System.out.println("吃一寸面包");
}
}
vo場景2:T(n) = 5logn,執行次數是對數的。
void eat2(int n){
for(int i=1; i<n; i*=2){
System.out.println("等待一天");
System.out.println("等待一天");
System.out.println("等待一天");
System.out.println("等待一天");
System.out.println("吃一半面包");
}
}場景3:T(n) = 2,執行次數是常量的。
void eat3(int n){
System.out.println("等待一天");
System.out.println("吃一個雞腿");
}場景4:T(n) = 0.5n^2 + 0.5n,執行次數是一個多項式。
void eat4(int n){
for(int i=0; i<n; i++){
for(int j=0; j<i; j++){
System.out.println("等待一天");
}
System.out.println("吃一寸面包");
}
}
漸進時間復雜度
有了基本操作執行次數的函數 T(n),是否就可以分析和比較一段代碼的運行時間了呢?還是有一定的困難。
比如算法A的相對時間是T(n)= 100n,算法B的相對時間是T(n)= 5n^2,這兩個到底誰的運行時間更長一些?這就要看n的取值了。
所以,這時候有了漸進時間復雜度(asymptotic time complectiy)的概念,官方的定義如下:
若存在函數 f(n),使得當n趨近于無窮大時,T(n)/ f(n)的極限值為不等于零的常數,則稱 f(n)是T(n)的同數量級函數。
記作 T(n)= O(f(n)),稱O(f(n)) 為算法的漸進時間復雜度,簡稱時間復雜度。
漸進時間復雜度用大寫O來表示,所以也被稱為大O表示法。


如何推導出時間復雜度呢?有如下幾個原則:
如果運行時間是常數量級,用常數1表示;
只保留時間函數中的最高階項;
如果最高階項存在,則省去最高階項前面的系數。
讓我們回頭看看剛才的四個場景。
場景1:
T(n) = 3n
最高階項為3n,省去系數3,轉化的時間復雜度為:
T(n) = O(n)
場景2:
T(n) = 5logn
最高階項為5logn,省去系數5,轉化的時間復雜度為:
T(n) = O(logn)

場景3:
T(n) = 2
只有常數量級,轉化的時間復雜度為:
T(n) = O(1)

場景4:
T(n) = 0.5n^2 + 0.5n
最高階項為0.5n^2,省去系數0.5,轉化的時間復雜度為:
T(n) = O(n^2)

這四種時間復雜度究竟誰用時更長,誰節省時間呢?稍微思考一下就可以得出結論:
O(1)< O(logn)< O(n)< O(n^2)
在編程的世界中有著各種各樣的算法,除了上述的四個場景,還有許多不同形式的時間復雜度,比如:
O(nlogn), O(n^3), O(m*n),O(2^n),O(n!)
今后遨游在代碼的海洋里,我們會陸續遇到上述時間復雜度的算法。


時間復雜度的巨大差異


我們來舉過一個栗子:
算法A的相對時間規模是T(n)= 100n,時間復雜度是O(n)
算法B的相對時間規模是T(n)= 5n^2,時間復雜度是O(n^2)
算法A運行在小灰家里的老舊電腦上,算法B運行在某臺超級計算機上,運行速度是老舊電腦的100倍。
那么,隨著輸入規模 n 的增長,兩種算法誰運行更快呢?
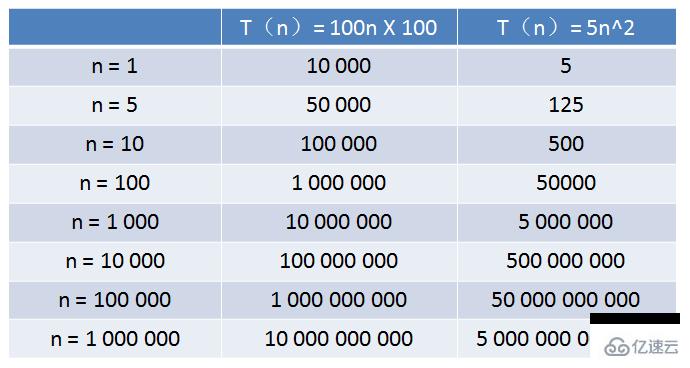
從表格中可以看出,當n的值很小的時候,算法A的運行用時要遠大于算法B;當n的值達到1000左右,算法A和算法B的運行時間已經接近;當n的值越來越大,達到十萬、百萬時,算法A的優勢開始顯現,算法B則越來越慢,差距越來越明顯。
這就是不同時間復雜度帶來的差距。

以上是數據結構之一組圖讓你搞懂時間復雜度的案例的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





