溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關java獲取文本文件字符編碼的方法,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
一、認識字符編碼:
1、Java中String的默認編碼為UTF-8,可以使用以下語句獲取:Charset.defaultCharset();
2、Windows操作系統下,文本文件的默認編碼為ANSI,對中文Windows來說即為GBK。例如我們使用記事本程序新建一個文本文檔,其默認字符編碼即為ANSI。
3、Text文本文檔有四種編碼選項:ANSI、Unicode(含Unicode Big Endian和Unicode Little Endian)、UTF-8、UTF-16
4、因此我們讀取txt文件可能有時候并不知道其編碼格式,所以需要用程序動態判斷獲取txt文件編碼。
ANSI :無格式定義,對中文操作系統為GBK或GB2312
UTF-8 :前三個字節為:0xE59B9E(UTF-8)、0xEFBBBF(UTF-8含BOM)
UTF-16 :前兩字節為:0xFEFF
Unicode:前兩個字節為:0xFFFE
例如:Unicode文檔以0xFFFE開頭,用程序取出前幾個字節并進行判斷即可。
5、Java編碼與Text文本編碼對應關系:

Java讀取Text文件,如果編碼格式不匹配,就會出現亂碼現象。所以讀取文本文件的時候需要設置正確字符編碼。Text文檔編碼格式都是寫在文件頭的,在程序中需要先解析文件的編碼格式,獲得編碼格式后,再以此格式讀取文件就不會產生亂碼了。
二、舉個例子:
有一個文本文件:test.txt
測試代碼:
/**
* 文件名:CharsetCodeTest.java
* 功能描述:文件字符編碼測試
*/
import java.io.*;
public class CharsetCodeTest {
public static void main(String[] args) throws Exception {
String filePath = "test.txt";
String content = readTxt(filePath);
System.out.println(content);
}
public static String readTxt(String path) {
StringBuilder content = new StringBuilder("");
try {
String fileCharsetName = getFileCharsetName(path);
System.out.println("文件的編碼格式為:"+fileCharsetName);
InputStream is = new FileInputStream(path);
InputStreamReader isr = new InputStreamReader(is, fileCharsetName);
BufferedReader br = new BufferedReader(isr);
String str = "";
boolean isFirst = true;
while (null != (str = br.readLine())) {
if (!isFirst)
content.append(System.lineSeparator());
//System.getProperty("line.separator");
else
isFirst = false;
content.append(str);
}
br.close();
} catch (Exception e) {
e.printStackTrace();
System.err.println("讀取文件:" + path + "失敗!");
}
return content.toString();
}
public static String getFileCharsetName(String fileName) throws IOException {
InputStream inputStream = new FileInputStream(fileName);
byte[] head = new byte[3];
inputStream.read(head);
String charsetName = "GBK";//或GB2312,即ANSI
if (head[0] == -1 && head[1] == -2 ) //0xFFFE
charsetName = "UTF-16";
else if (head[0] == -2 && head[1] == -1 ) //0xFEFF
charsetName = "Unicode";//包含兩種編碼格式:UCS2-Big-Endian和UCS2-Little-Endian
else if(head[0]==-27 && head[1]==-101 && head[2] ==-98)
charsetName = "UTF-8"; //UTF-8(不含BOM)
else if(head[0]==-17 && head[1]==-69 && head[2] ==-65)
charsetName = "UTF-8"; //UTF-8-BOM
inputStream.close();
//System.out.println(code);
return charsetName;
}
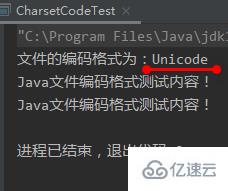
}運行結果:
以上就是java獲取文本文件字符編碼的方法,詳細使用情況還需要大家自己親自動手使用過才能領會。如果想了解更多相關內容,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





